





01
写在之前
namespace是什么
Linux的namespace就是用来隔离内核资源而存在的,不同namespace里的进程只能看到自己的进程及相关的资源,无法看到其它namespace里面的进程和资源,不同namespace相互隔离,相互独立,一个改变不影响另外的namespace,彼此感觉不到对方的存在。
Linux中namespace有哪些
| Namespace | 参数标识 | 功能 |
| Mount | CLONE_NEWNS | 对挂载点文件系统的隔离 |
| UTS | CLONE_NEWUTS | 对主机名或者域名进行隔离 |
| IPC | CLONE_NEWIPC | posix进程间通信、消息队列和共享内存 |
| network | CLONE_NEWNET | 隔离网络设备、网络栈协议、socket端口等 |
| user | CLONE_NEWUSER | 隔离用户和用户组,通过此隔离用户权限 |
| PID | CLONE_NEWPID | 对进程PID进行编号,然后进行隔离 |
namespace实际上是给人一种错觉,好像是在namespace中进程独享系统所有的资源,只能看到自己,别人无法看到;这6个namespace的操作也是直接作用于Linux系统调用的三个API,分别是clone、unshare、setns,根据传的不同参数标识确认创建的是什么namespace,想要深入了解,可以看下源码。
02
Network Namespace
今天简单聊聊网络名称空间,它主要是隔离Linux系统里面的设备、IP地址、端口范围、路由表、防火樯、/proc/net目录等网络资源,每个namespace都有自己的网络协议栈,用途是显而易见的,之前我们在一台服务器上面只能开启一个80端口,有了namespace后,就可以在一台主机监听多个80,不用担心端口冲突。
关于network namespace的操作,如果让普通用户直接操作API进行增(创建)、删、改、查的话,估计很多人都望而却步,对普通用户来说也相对困难,Linux系统为我们提供了ip命令(如果没有,请安装iproute工具包),使得我们很简单的操作network namespace;
操作演示(创建、修改、查看、删除)
# 查看ip命令是由哪个软件包提供
[root@master01 ~]# rpm -qf usr/sbin/ip
iproute-3.10.0-54.el7.x86_64
# 创建networker namespace:k8svip
[root@master01 ~]# ip netns add k8svip
# 查看刚才创建的namespace
[root@master01 ~]# ip netns list
k8svip
# 查看namespace 网络设备情况,环回口处于down状态
[root@master01 ~]# ip netns exec k8svip ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@master01 ~]# ip netns exec k8svip ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 修改环回口的状态
[root@master01 ~]# ip netns exec k8svip ping 127.0.0.1
connect: Network is unreachable
[root@master01 ~]# ip netns exec k8svip ip link set dev lo up
[root@master01 ~]# ip netns exec k8svip ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.061 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.039 ms
^C
--- 127.0.0.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.039/0.050/0.061/0.011 ms
# 再次查看namespace 网络设备情况,环回口由down--> UP
[root@master01 ~]# ip netns exec k8svip ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@master01 ~]# ip netns exec k8svip ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 删除刚刚创建的namespace
[root@master01 ~]# ip netns delete k8svip
# 再次查看,名称为k8svip的namespace已经消失
[root@master01 ~]# ip netns list
[root@master01 ~]#
03
veth pair
veth pair是什么
上面例子只有一个环回口127.0.0.1,它是无法访问外部资源的,这里就需要添加一个真实设备,应该如何做呢?这里先说下veth pair,它总是成对出现的并且相互连接,就像Linux的双向管道(pipe),一端发送报文,另一端接收报文,veth pair通常被用于network namespace之间的通信,即把veth pair的两端,分别放在不同的namespace里面,就像是你在用吸管喝一杯可乐,吸管的两端,一端在杯内(一个名称空间),另一端在你嘴里 (另一个名称空间),在veth pair设备上,任意一端(RX)接受的数据都会在另一端(TX)发送出去,veth pair传输过程 中不会篡改数据包的内容。现在我们创建一个veth对,一端放在根network namespace空间中,一端放在k8svip network namespace空间下,并配置IP,使这两个veth对可以通信;
(另一个名称空间),在veth pair设备上,任意一端(RX)接受的数据都会在另一端(TX)发送出去,veth pair传输过程 中不会篡改数据包的内容。现在我们创建一个veth对,一端放在根network namespace空间中,一端放在k8svip network namespace空间下,并配置IP,使这两个veth对可以通信;
veth pair实验
# 1. 现在创建一对veth pair
[root@master01 ~]# ip link add veth0 type veth peer name veth1
[root@master01 ~]# ip a
....
37: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether be:e3:d2:68:35:5b brd ff:ff:ff:ff:ff:ff
38: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether c2:fe:36:f0:c0:bd brd ff:ff:ff:ff:ff:ff
[root@master01 ~]#
# 2. 创建一个network namespace
[root@master01 ~]# ip netns add k8svip
[root@master01 ~]# ip netns list
k8svip
# 3. 把veth对中的veth1放置在k8svip名称空间下
[root@master01 ~]# ip link set veth1 netns k8svip
# 本地 根network namespace,只有veth0了
[root@master01 ~]# ip a
。。。
38: veth0@if37: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether c2:fe:36:f0:c0:bd brd ff:ff:ff:ff:ff:ff link-netnsid 2
# 4. 查看k8svip 名称空间下的veth1
[root@master01 ~]# ip netns exec k8svip ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
37: veth1@if38: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether be:e3:d2:68:35:5b brd ff:ff:ff:ff:ff:ff link-netnsid 0
destination
[root@master01 ~]#
# 5. 为veth对设置IP
[root@master01 ~]# ifconfig veth0 192.168.0.1/24 up
[root@master01 ~]# ip netns exec k8svip ifconfig veth1 192.168.0.2/24 up
# 6. 查看veth下面的路由及防火墙规则,这也证明了不同的network namespace,是相互隔离的
[root@master01 ~]# ip netns exec k8svip ip route
192.168.0.0/24 dev veth1 proto kernel scope link src 192.168.0.2
[root@master01 ~]# ip netns exec k8svip iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
[root@master01 ~]# ip netns exec k8svip route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
# 7. 测试连通性
[root@master01 ~]# ip netns exec k8svip ping 192.168.0.1
PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data.
64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=0.116 ms
^C
--- 192.168.0.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.116/0.116/0.116/0.000 ms
[root@master01 ~]# ip netns exec k8svip ping 114.114.114.114
connect: Network is unreachable
[root@master01 ~]#
[root@master01 ~]# ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.084 ms
64 bytes from 192.168.0.2: icmp_seq=2 ttl=64 time=0.066 ms
^C
--- 192.168.0.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.066/0.075/0.084/0.009 ms
# 8. 查看根network namespace的route信息
[root@master01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
。。。。
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
[root@master01 ~]#
通过上面的实验,了解了veth pair对的使用方法,veth两端的网卡放在不同的名称空间下,这两个端口可以通信,但在k8svip名称空间下路由信息无法访问外网,如果想访问有很多方法可以解决,例如我们在根network namespace下面创建一个网桥,并把veth0(在根名称空间下的veth)绑定到网桥上,也可以通过NAT(网络地址转换的方式)。
04
Bridge 网桥
什么是网桥
网络设备最早是hub集线器,共享背板总线,在同一个冲突域和广播域中,后来为了隔离冲突域,出了桥接技术,利用网桥可以将两个或多个共享式以太网段连接起来,位于网桥两边的以太网分属于不同的冲突域,独享背板总线,但仍处于同一个广播域中,但网桥被具有更多端口、可隔离冲突域的交换机所取代。
这里大家理解下即可,Linux Bridge也是类似的虚拟网络设备,具有相同的功能,把不同的网段桥接在一起,使其通信可用。
为什么需要网桥
linux服务器有了多个network namespace,里面有可能是不同的网段,这些不同的网段之间需要相互通信,所以需要类似物理设备交换机一样,把需要相互通信的物理服务器,连起来加以配置就可以通信了,但在一台物理服务器中,就可以使用Linux Bridge把多个不同的network namespace逻辑上连起来,实现通信,说白了就是把创建的veth pair对的一端加入到网桥中。
创建网桥前
# 1. 创建 network namespace k8svip
[root@ipip02 ~]# ip netns add k8svip
# 2. 创建 veth pair 对,并把 veth1 放在 k8svip 下面
[root@ipip02 ~]# ip link add veth0 type veth peer name veth1
[root@ipip02 ~]# ip link set veth1 netns k8svip
# 3. 设置 IP
[root@ipip02 ~]# ip addr add 192.168.1.1/24 dev veth0
[root@ipip02 ~]# ip netns exec k8svip ifconfig veth1 192.168.1.2/24 up
[root@ipip02 ~]# ip link set dev veth0 up
# 4. 验证连通性
[root@ipip02 ~]# ping -c 2 -I veth0 192.168.1.2
PING 192.168.1.2 (192.168.1.2) from 192.168.1.1 veth0: 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.020 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.051 ms
--- 192.168.1.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.020/0.035/0.051/0.016 ms
[root@ipip02 ~]# ^C
[root@ipip02 ~]# ip netns exec k8svip ping -c 2 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.027 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.048 ms
--- 192.168.1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.027/0.037/0.048/0.012 ms
[root@ipip02 ~]#
创建网桥前通信正常。
创建网桥并把veth0 加入进去
# 1. 创建网桥并启动
[root@ipip02 ~]# ip link add name br0 type bridge
[root@ipip02 ~]# ip link set br0 up
# 2. 把 veth0 桥接到br0上面
[root@ipip02 ~]# ip link set dev veth0 master br0
验证
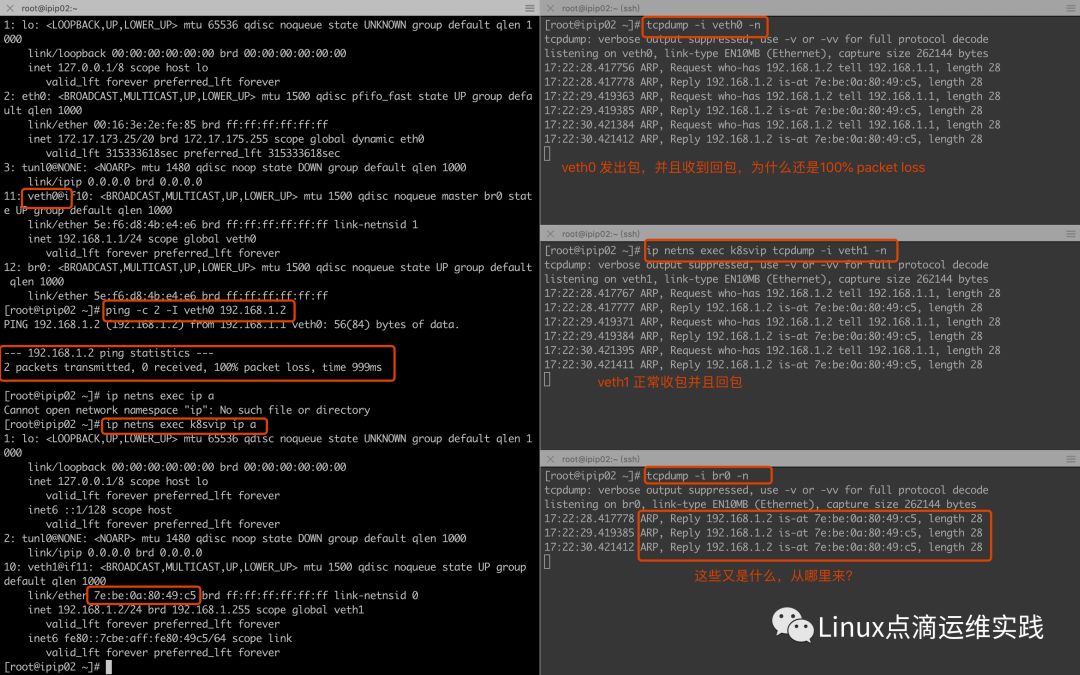
通过验证发现不通了,什么情况呢?正常情况下 veth0 与 veth1 是相互通的,现在不通的,原因是我们把 veth0 桥接到 br0 之后,我们ping的时候,veth0 收到了Replay包,但没有给他它所在名称空间的网络协议栈,而是丢给了网桥,网桥 br0 协议栈没有veth0的mac地址,导致通信失败。
通过上面的分析得出,给veth0配置IP没有意义,协议栈传数据包给veth0,应答报文也回不来,我们把veth0的IP给br0,再实验;
[root@ipip02 ~]# ip addr del 192.168.1.1/24 dev veth0
[root@ipip02 ~]# ip addr add 192.168.1.1/24 dev br0
再次验证
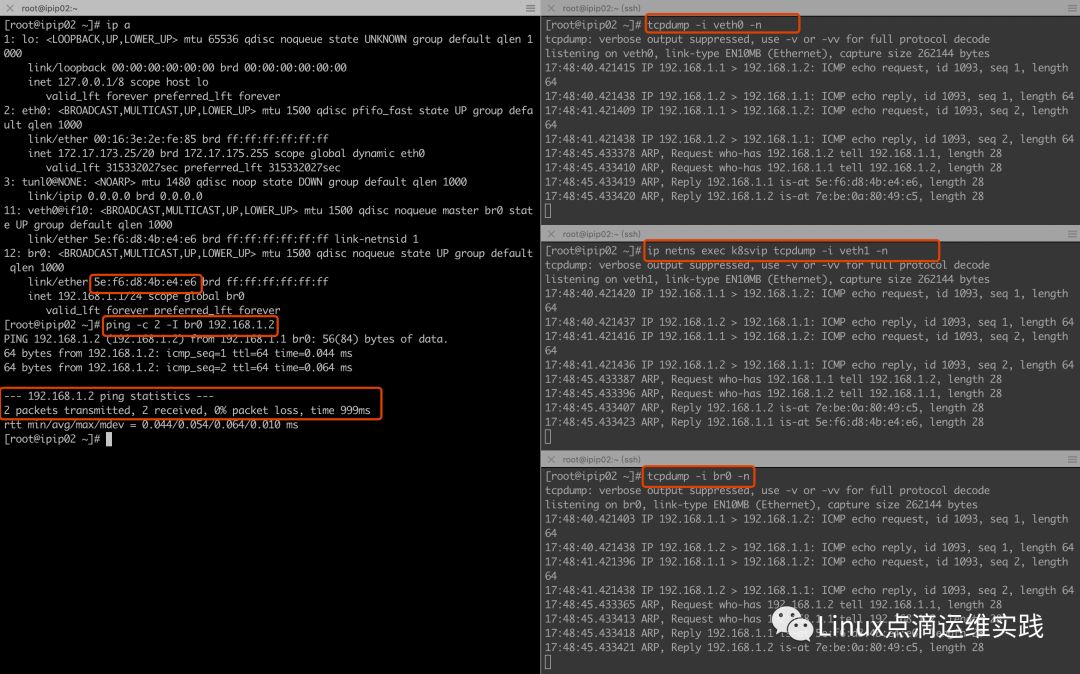
以上测试完美通信了,但我们还需要namespace与外网进行通信,应该如何做呢?
network namespace内与外部通信
[root@k8svip ~]# ip netns exec k8svip01 ip route add default via 192.168.1.1
[root@k8svip ~]# iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
实验结果
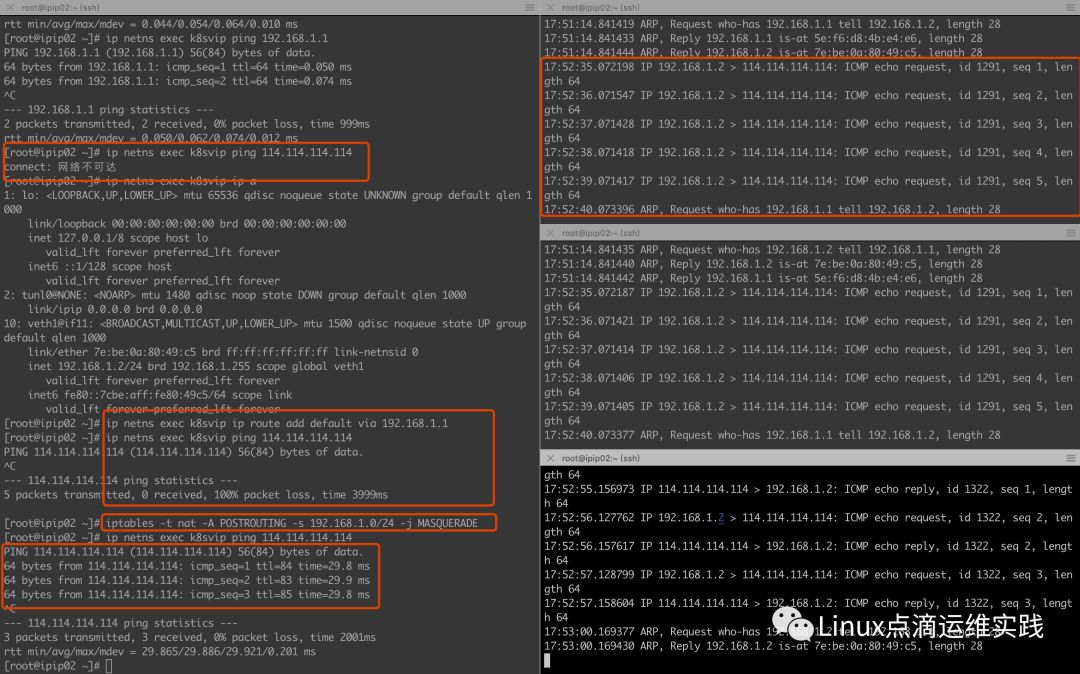
通过上面的实验我们发现,为 network namespace 设置路由后,发现ping出去的包,没有应答包(tcpdump可以看到),其实原因是源地址是私有地址,应答包的目的地址是私有地址的话,会被丢弃,解决办法是做一下SNAT,使用 -j MASQUERADE 做下 IP 地址伪装,设置完成后,发现创建的k8svip 网络名称空间内可以与外界通信了。
05
实验
实验图
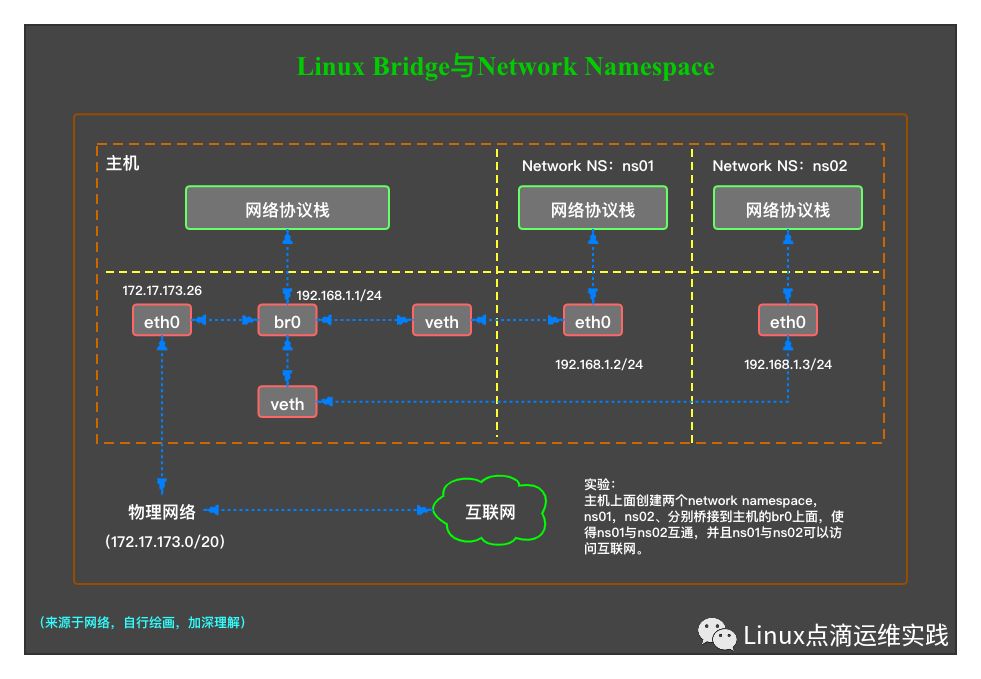
从上图中,我们也可以看到veth与br0桥接后,不会再把应答包给网络协议栈,而是给了br0。
通过上面的总结,可以很容易的完成以上实验需求?
操作步骤
# 1. 添加两个ns
[root@k8svip ~]# ip netns add ns01
[root@k8svip ~]# ip netns add ns02
[root@k8svip ~]# ip netns list
ns02
ns01
[root@k8svip ~]#
# 2. 添加两对网卡
[root@k8svip ~]# ip link add veth0 type veth peer name br0-veth0
[root@k8svip ~]# ip link add veth1 type veth peer name br0-veth1
[root@k8svip ~]#
# 3. 分别把veth0和veth1添加到ns01和02 network namespace中
[root@k8svip ~]# ip link set veth0 netns ns01
[root@k8svip ~]# ip link set veth1 netns ns02
[root@k8svip ~]#
# 4. 创建网卡
[root@k8svip ~]# ip link add name br0 type bridge
[root@k8svip ~]#
# 5. 把br0-veth0 br0-veth1桥接到br0并查看
[root@k8svip ~]# ip link set dev br0-veth0 master br0
[root@k8svip ~]# ip link set dev br0-veth1 master br0
[root@k8svip ~]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.4e9afbd7f2b7 no br0-veth0 br0-veth1
[root@k8svip ~]#
# 6. 设置IP地址
[root@k8svip ~]# ip addr add 192.168.1.1/24 dev br0
[root@k8svip ~]# ip netns exec ns01 ifconfig veth0 192.168.1.2/24 up
[root@k8svip ~]# ip netns exec ns02 ifconfig veth1 192.168.1.3/24 up
[root@k8svip ~]# ip link set br0-veth0 up
[root@k8svip ~]# ip link set br0-veth1 up
[root@k8svip ~]# ip link set br0 up
[root@k8svip ~]#
# 7. 设置路由
[root@k8svip ~]# ip netns exec ns01 ip route add default via 192.168.1.1
[root@k8svip ~]# ip netns exec ns02 ip route add default via 192.168.1.1
[root@k8svip ~]# ip netns exec ns01 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 veth0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
[root@k8svip ~]#
[root@k8svip ~]# ip netns exec ns02 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 veth1
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
[root@k8svip ~]#
# 8. 设置防火墙 SNAT 的 IP 伪装
[root@k8svip ~]# iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
# 9. 单独network namespace 内的IP ping不通的话,需要启动lo
[root@k8svip ~]# ip netns exec ns01 ip link set lo up
[root@k8svip ~]# ip netns exec ns02 ip link set lo up
[root@k8svip ~]#
实验结果
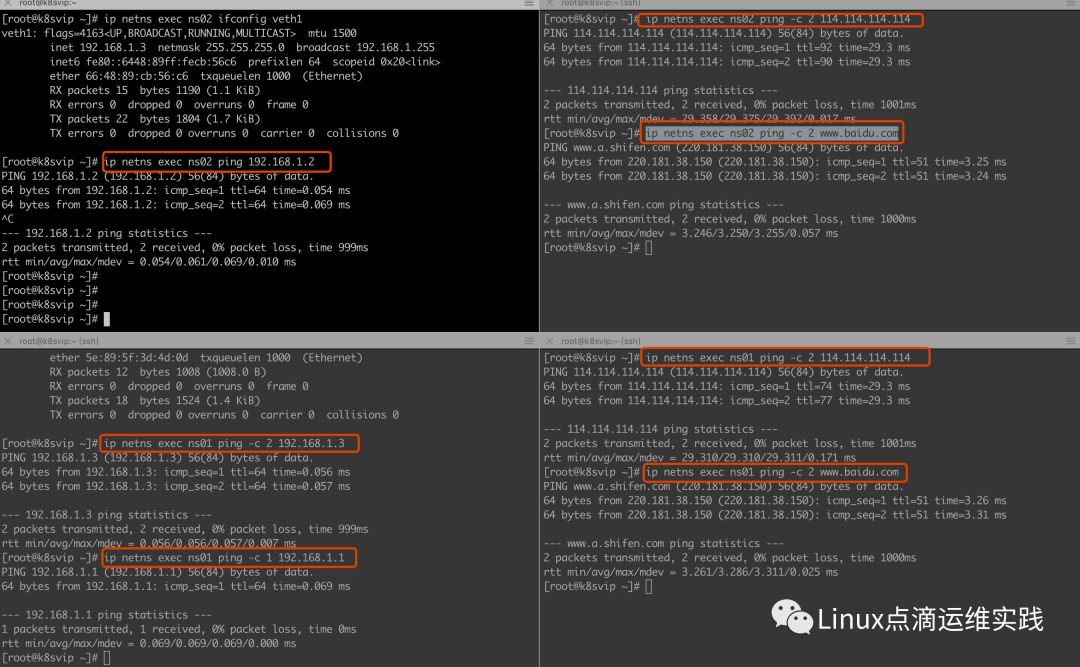
05
总结
Linux 内核隔离技术是由namespace实现的,直接调用操作系统提供的API(clone、unshare、setns),根据用户的参数进行6种不同名称空间的创建。
linux操作系统 ip 命令可以对网络名称空间进行创建,大大降低了用户的难度,后面又总结了veth pair、bridge等知识点并通过实验的情况进行了演示总结。
从底层分析了 network namespace 与 bridge 的相爱相杀,这个总结对今后总结 kubernetes flannel 与 calico 插件起一个铺垫作用。

您的关注是我写作的动力

往期分享
kubeadm使用外部etcd部署kubernetes v1.17.3 高可用集群
同一kubernetes部署多个Nginx Ingress Controller
通过traceID实例讲解 Nginx Ingress 参数配置
