




点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/incubator-seatunnel

在9月24日的海外线上会议上,Apache SeaTunnel PPMC 范佳分享了如何使用正确的数据集成工具,事半功倍地完成数据处理。以下为演讲全程整理,供参考学习。


范佳,Apache SeaTunnel PPMC
01
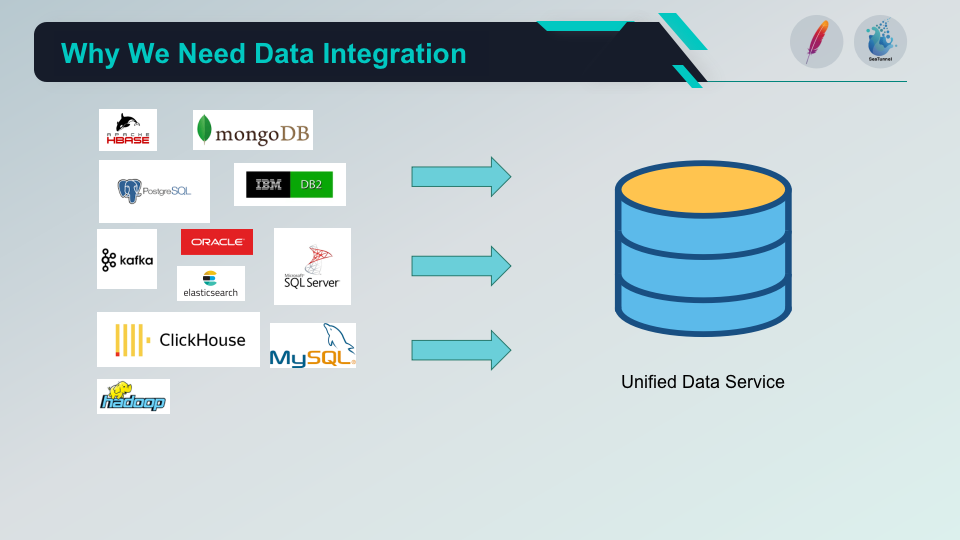
为什么我们需要数据集成?

02
我们需要什么样的工具?
支持多种数据源,这样我们才能支持把多种数据源统一到同一个数据存储中。 数据一致性保证,所以我们才能确保两个数据库的数据是一致的。 高效的数据同步能力,海量的数据同步需要快速的同步,才能保证数据的及时性。
02
Apache SeaTunnel


03
如何使用SeaTunnel


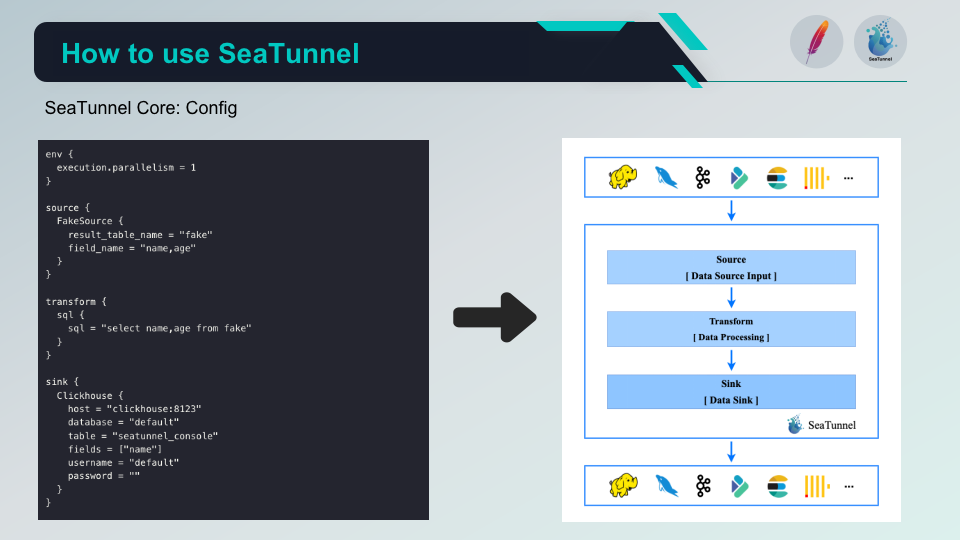
04
SeaTunnel社区
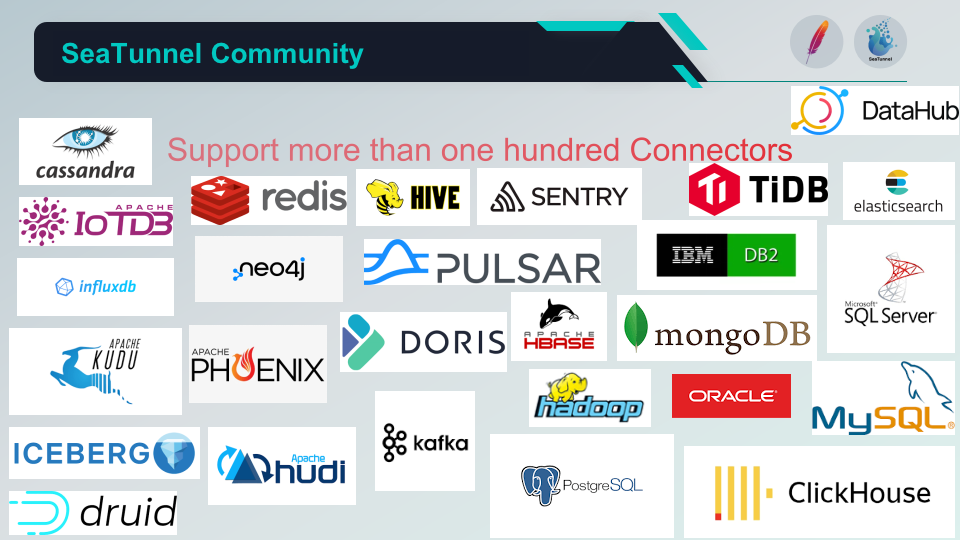
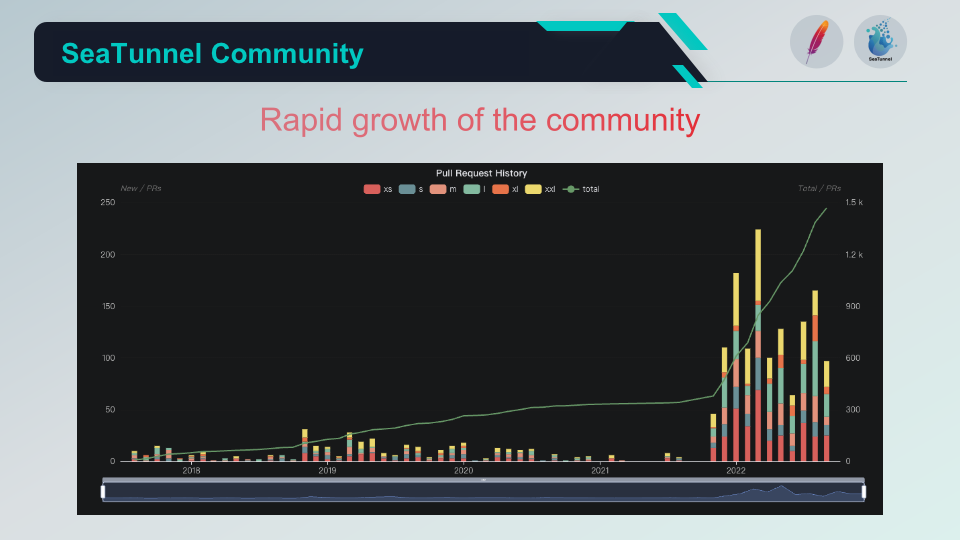
05
用户案例

项目官网: https://seatunnel.apache.org/ Twitter: https://twitter.com/ASFSeaTunnel
Apache SeaTunnel

往期推荐
点击“阅读原文”参与开源

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
阿里云李飞飞:将大模型,装进数据库里
科技行者
391次阅读
2025-02-28 11:47:59
金仓数据库26套!宁波市司法局信息系统适配改造(一期)采购项目
天下观查
312次阅读
2025-03-21 10:33:59
达梦数据与法本信息签署战略合作协议
达梦数据
280次阅读
2025-03-06 09:26:57
大连农商40万,采购Greenplum数据库原厂订阅服务
天下观查
270次阅读
2025-03-13 09:52:29
国产化+性能王炸!这套国产方案让 3.5T 数据 5 小时“无感搬家”
YMatrix
266次阅读
2025-03-13 09:51:26
IBM收购数据库厂商DataStax:瞄准向量和AI搜索
深度数据云
256次阅读
2025-02-28 12:04:04
国产数据库高光时刻!天翼云TeleDB荣登TPC-DS全球测评总榜第二
天翼云开发者社区
181次阅读
2025-03-13 17:24:48
从湖仓分离到湖仓一体,四川航空基于 SelectDB 的多源数据联邦分析实践
SelectDB
176次阅读
2025-03-03 11:23:24
神州数码携手云原生数据库 PolarDB,共筑国产数据库新生态
神州数码集团
167次阅读
2025-03-03 18:04:27
DBAIOPS社区将在知衍平台上推出数据库运维智能体
白鳝的洞穴
164次阅读
2025-03-07 10:29:18
