





【摘要】k8s常见故障速查指南。
一、前言
二、问题列表
1、生产k8s集群故障实例
问题描述
pod错误如下图所示:
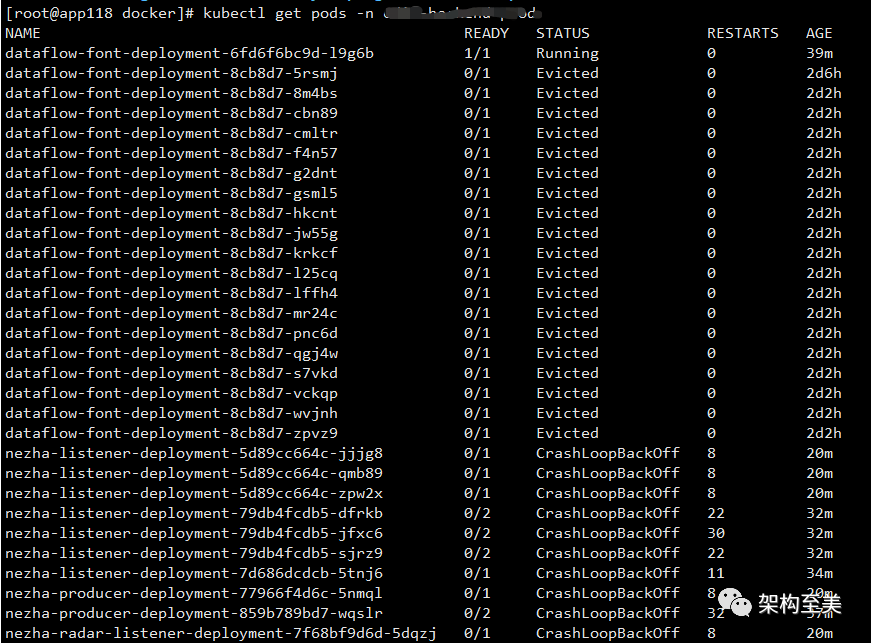
Java应用如下图所示:

进入容器后,也显示没有权限:
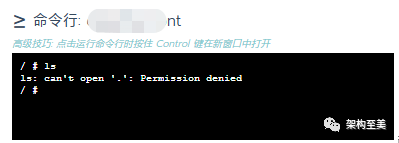
问题分析
解决方案
#永久关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config
注:重启机器后,selinux配置才能永久生效 执行getenforce 显示Disabled说明selinux已经关闭
#临时关闭selinux
setenforce 0
注:临时关闭后,服务器重启后selinux还是会开启,不要用这种方式,若是方式服务器无法重启也要把selinux变成Disabled
为什么要关闭selinux?
2、网络插件Calico故障实例
问题描述
情况1:某个节点的Calico状态是CrashLoopBackOff,即等待中。情况2:其中一个节点的calico是Running 但是not READY。
kubectl get pods -n kube-system
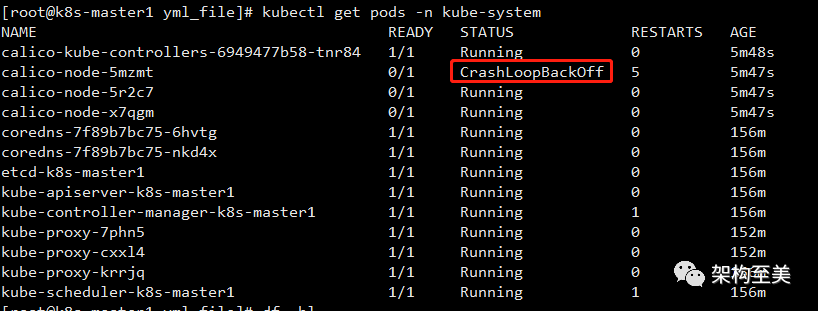
如上图可以看到有个calico状态是CrashLoopBackOff,即等待中
如上图可以其中一个节点的calico是Running 但是not READY
查看属于哪个节点:
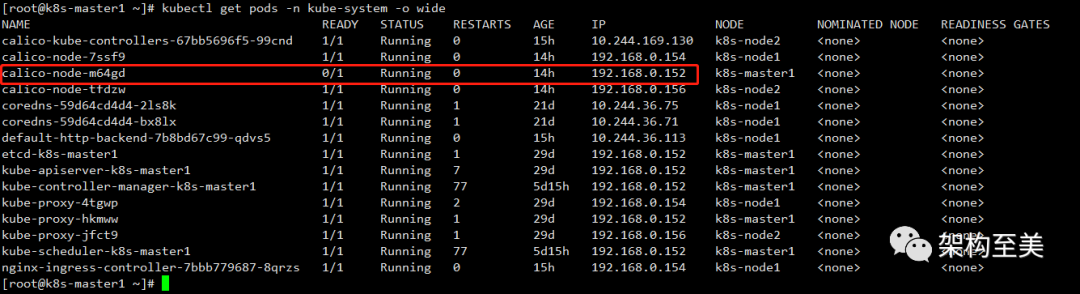
kubectl get pods -n kube-system -o wide
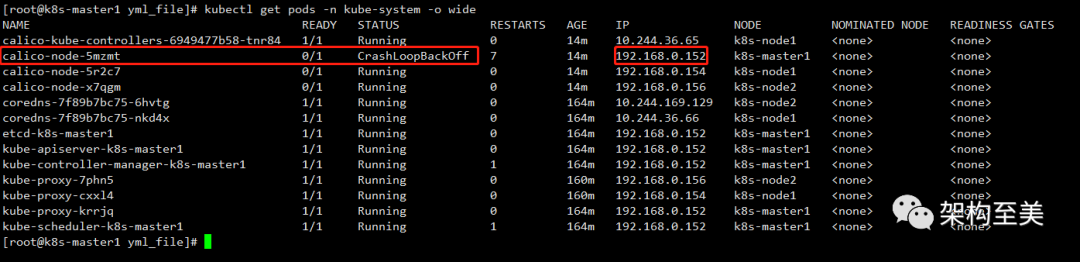
如上图可以看到k8s-master1的calico有问题。
查看日志:
kubectl logs -f -n kube-system calico-node-5mzmt -c calico-node
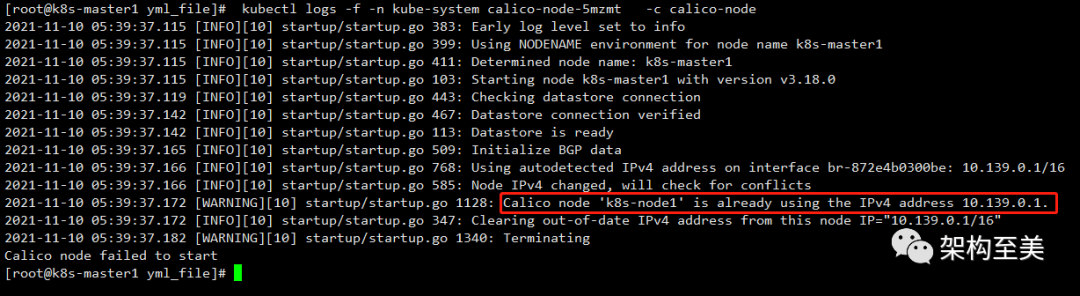
如上图可以看到10.139.0.1被占用了,10.139.0.1是我之前测试其他docker容器新建的自定义网络,把它删除掉试试
问题分析
解决方案
查看network:
docker network ls
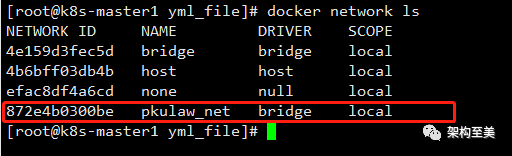
删除自定义网络:
docker network rm pkulaw_net
删除pod:
kubectl delete pod calico-node-5mzmt -n kube-system
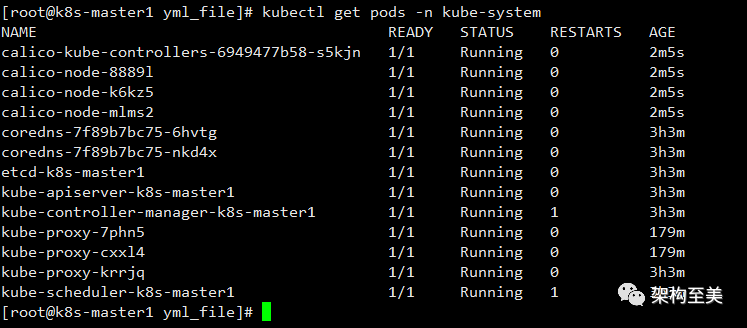
再次查看calico:
kubectl get pods -n kube-system
彻底根治:
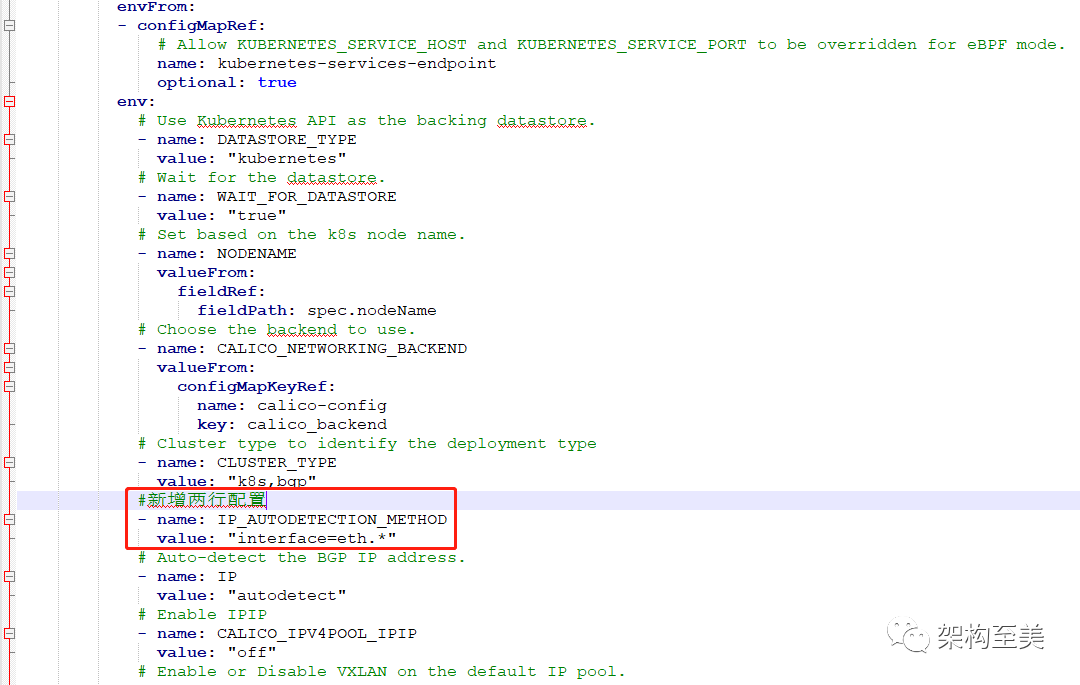
在配置文件CALICO_NETWORKING_BACKEND处新增两行配置:
#新增两行配置 直接配置通配符 :value: “interface=eth.*”
- name: IP_AUTODETECTION_METHOD
value: "interface=eth.*"
更新一下资源清单文件calico.yaml :
kubectl apply -f calico.yaml
3、因系统内核版本低引发的网络插件Calico故障实例
问题描述
calico-node pod错误如下图所示:
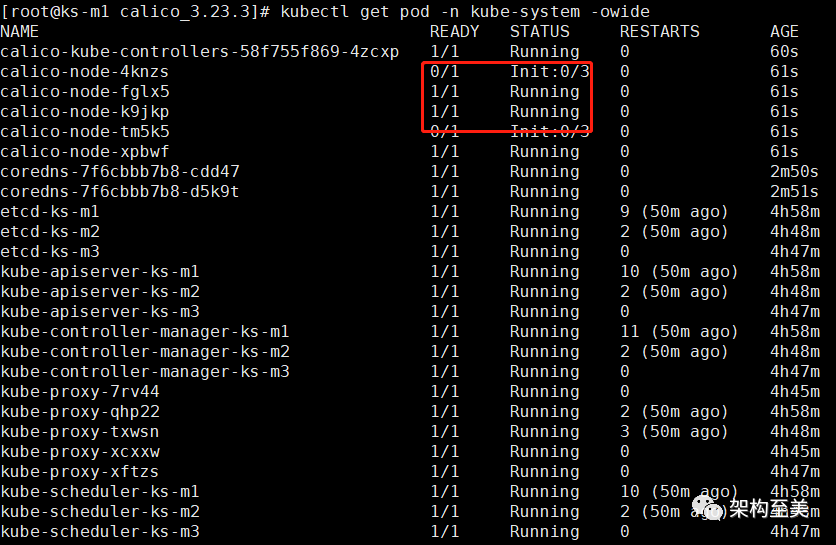
calico-node pod报错详情如下图所示:
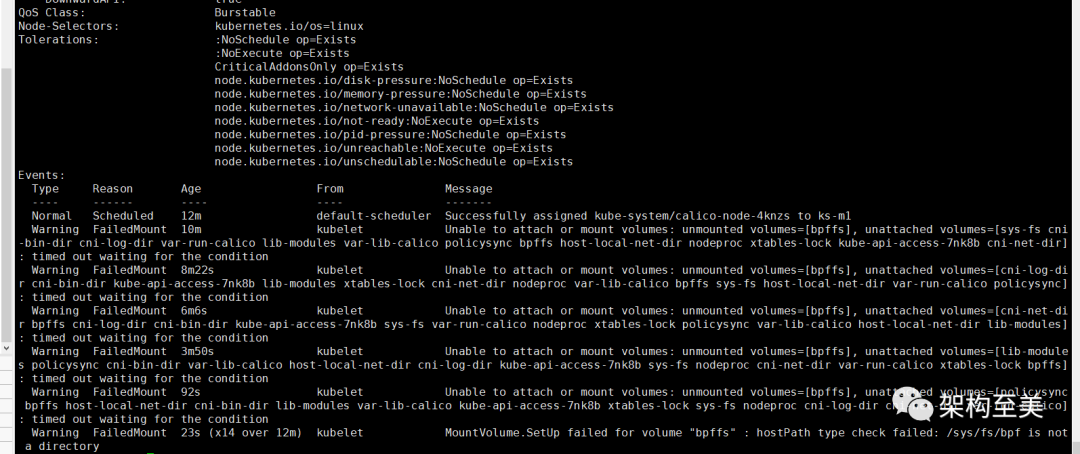
解决方案
请参考:Centos 7.x 升级内核
4、k8s组件不健康问题
问题描述
kubectl get cs 出现Unhealthy,且rancher控制台提示组件不健康。
$ kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
etcd-0 Healthy {"health":"true"}
这是由于scheduler、controller-manager端口(127.0.0.1:10251),物理机不能监听.
calico-node pod报错详情如下图所示:
解决方案
把scheduler、controller-manager端口变成物理机可以监听的端口,如下:
# 修改kube-scheduler的配置文件
$ vim /etc/kubernetes/manifests/kube-scheduler.yaml
# 修改如下内容
把—port=0注释即可
# 重启各个节点的kubelet
$ systemctl restart kubelet
$ systemctl restart kubelet
# 相应的端口已经被物理机监听了
$ ss -antulp | grep :10251
tcp LISTEN 0 128 :::10251 :::* users:(("kube-scheduler",pid=36945,fd=7))
# 修改kube-controller-manager的配置文件
$ vim /etc/kubernetes/manifests/kube-controller-manager.yaml
# 修改如下内容
把—port=0注释即可
# 重启各个节点的kubelet
$ systemctl restart kubelet
$ systemctl restart kubelet
# 查看状态
$ kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
$ ss -antulp | grep :10252
tcp LISTEN 0 128 :::10252 :::* users:(("kube-controller",pid=41653,fd=7))
5、k8s命名空间或crd资源无法删除
问题描述
有时候我们删除k8s的命名空间或crd资源时一直卡在 Terminating,例如以下场景:
场景一:在KubeSphere中开启了日志服务(KubeSphere Logging System)以后,我并不想使用它,于是我先关闭了日志服务,然后对它进行强制删除。
$ kubectl delete ns kubesphere-logging-system --force --grace-period=0
过了十几分钟,再次查看删除进度:
$ kubectl get ns kubesphere-logging-system
NAME STATUS AGE
kubesphere-logging-system Terminating 6d19h
卡在了 Terminating 的状态。
解决方案
获取 namespace 的详情信息并转为 json,如下:
$ kubectl get namespace kubesphere-logging-system -o json > kubesphere-logging-system.json
打开 json 文件编辑,找到 spec 将 finalizers 下的 kubernetes 删除:
"spec": {
"finalizers": [
"kubernetes" # 将此行删除
]
}
进行替换:
$ kubectl replace --raw "/api/v1/namespaces/kubesphere-logging-system/finalize" -f ./kubesphere-logging-system.json
最后再次查看,发现已经删除了,如下:
$ kubectl get ns kubesphere-logging-system
Error from server (NotFound): namespaces "kubesphere-logging-system" not found
场景二:想卸载KubeSphere,执行官方的kubesphere-delete.sh,一直卡在如下所示:
customresourcedefinition.apiextensions.k8s.io "fluentbits.logging.kubesphere.io" deleted
解决方案
#查看 crd资源对象
$ kubectl get crd|grep fluentbits.logging.kubesphere.io
fluentbits.logging.kubesphere.io
#删除crd
$ kubectl patch crd/fluentbits.logging.kubesphere.io -p '{"metadata":{"finalizers":[]}}' --type=merge
customresourcedefinition.apiextensions.k8s.io/fluentbits.logging.kubesphere.io patched
#再次查看crd资源对象,已经删除了
$ kubectl get crd|grep fluentbits.logging.kubesphere.io
· END ·
如果这篇文章对您有帮助或者有所启发的话,请帮忙三连暴击点赞、转发和在看。您的支持是我坚持更新的最大动力。
