





【摘要】Elasticsearch 的分片平衡问题。
大家好,我是小盒子。上次推文:Infinispan篇(三):如何对线上的Infinispan进行调优?通过实践详细阐述了Infinispan集群的备份、还原以及对生产中的Infinispan进行调JVM调优。
今天的主题:Elasticsearch篇(一):Elasticsearch 的分片均衡问题。
一、前言
年前生产中的Elasticsearch(以下简称ES)集群在凌晨做完一次自动索引优化后,出现了大量慢查询告警,导致请求堆积。经过几天的排查发现了ES节点主分片和副本分片分布存在不均匀的问题。当然了暂未有定论是由于分片不均衡导致了性能下降,但是主分片和副本分片分布不均匀确实是个问题。
“所谓“邪乎到家必有鬼”---《三体》,非常喜欢大史的这句口头禅,因为在技术问题中也有“鬼”存在。
”
二、Elasticsearch概述
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
三、三节点ES集群搭建
3.1 ES搭建
version: '3.7'
services:
elasticsearch:
image: elasticsearch:6.5.4
container_name: bdyh-es
#失败自动重启策略
restart: on-failure
environment:
ES_JAVA_OPTS: "-Xms1g -Xmx1g"
TZ: Asia/Shanghai
#栈内存的上限 -1不限制
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- /data/elasticsearch/plugins:/usr/share/elasticsearch/plugins
- /data/elasticsearch/data:/usr/share/elasticsearch/data
- /data/elasticsearch/log:/usr/share/elasticsearch/log
- /data/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
ports:
- "9200:9200"
- "9300:9300"
healthcheck:
test: ["CMD-SHELL", "curl --silent --fail localhost:9200/_cluster/health || exit 1"]
#健康检查的时间间隔,默认为 20s。
interval: 20s
#健康检查的超时时间,默认为 20s。
timeout: 20s
#连续几次健康检查失败即认为容器不健康,默认为 3。
retries: 3
#为需要时间引导的容器提供初始化时间。在此期间的探测失败将不计入最大重试次数。但是,如果在启动期间健康检查成功,则认为容器已启动,所有连续失败都将计入最大重试次数
start_period: 30s
networks:
- pkulaw_net
networks:
pkulaw_net:
external: true复制
配置文件elasticsearch.yml内容如下:
#集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-1
#指定该节点是否有资格被选举成为node(注意这里只是设置成有资格, 不代表该node一定就是master),默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master
node.master: true
#指定该节点是否存储索引数据,默认为true
node.data: true
#数据和日志存储目录
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/log
#内存交换的选项,官网建议为true
bootstrap.memory_lock: true
#网关设置,设置 host 为 0.0.0.0 ,即可启用该物理机器所有网卡网络访问
network.host: 0.0.0.0
#设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址
network.publish_host: 192.168.0.152
#设置对外服务的http端口,默认为9200
http.port: 9200
#es节点之间通信的端口,默认为 9300
transport.tcp.port: 9300
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
#设置集群中节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
discovery.zen.ping.unicast.hosts: ["192.168.0.152:9300", "192.168.0.154:9300", "192.168.0.156:9300"]
#主资格节点参与选主的最小数量,该配置能有效地防止其发生脑裂现象。如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 - 分裂的大脑 - 这将导致数据丢失。缺省配置是 1。一个基本的原则是这里需要设置成 N / 2 + 1 , N 是 node.master=true 的节点个数,也就是 主资格节点 个数。例如在一个三节点的集群中, minimum_master_nodes 应该被设为 3 / 2 + 1 = 2
discovery.zen.minimum_master_nodes: 2
#设置ping其他节点时的超时时间,网络比较慢时可将该值设大复制
自定义docker网关:
#预先创建一个自定义的网络pkulaw_net,此处的10.139可以自定义,不冲突即可
sudo docker network create --driver bridge --subnet 10.139.0.0/16 --gateway 10.139.0.1 pkulaw_net复制
3.2 kibana和cerebro搭建
kibana和cerebro搭建:
version: '3.7'
services:
kibana:
image: kibana:6.5.4
container_name: kibana
environment:
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- "5601:5601"
networks:
- pkulaw_net
cerebro:
image: lmenezes/cerebro:0.9.4
container_name: cerebro
restart: always
ports:
- "9000:9000"
networks:
- pkulaw_net
networks:
pkulaw_net:
external: true复制
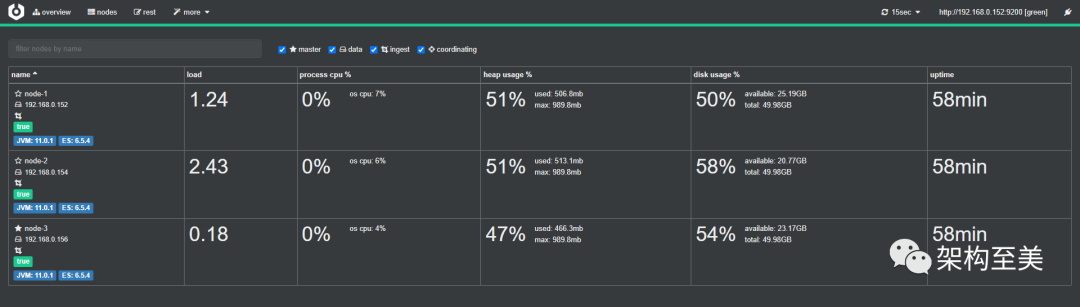
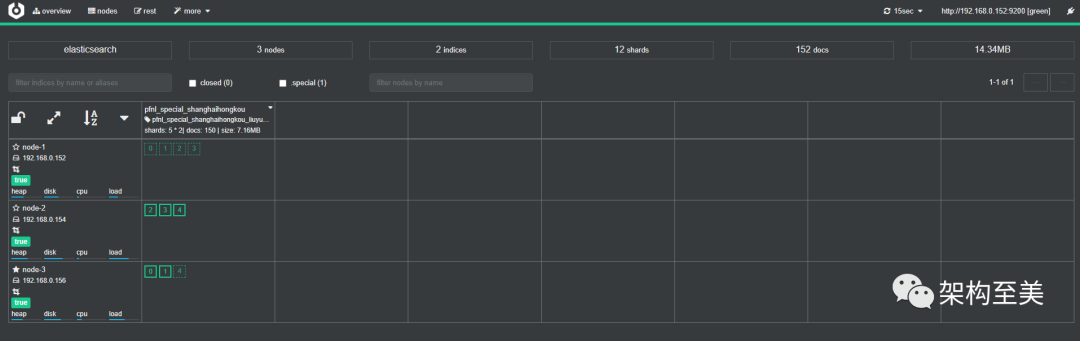
“为了模拟生产ES集群的数据分布状态,我手动将其中一个节点的副本都放在了nonde-1这个节点上,即索引的主分片(primary shard)和副本分片(replica shard)在每个节点上分布不均匀。
”
四、问题分析
先看一些重要概念:
cluster:代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
Primary Shard:代表索引主分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
Replica Shard:代表索引副本分片,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery:代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
什么情况下可能会造成分片分布不均匀呢?
1. 节点上下线维护:通常在下线一个es节点后,下线节点上存在的主分片会被检测掉丢失,elasticsearch集群会自动将其他节点上的副本分片设置为主分片,当该下线节点被重新拉起时,分片数据被识别,但均会被识别为副本分片。这些操作会导致一些节点的主分片比较集中,一些节点上的副本分片比较集中。 2. 大量较为集中的数据写入:大量的数据集中写入,可能导致暂时的主分片不均匀的情况。当业务场景为写入较多时,设置了较多的ingest节点进行写入,由于无法及时同步,导致主分片节点较为集中。
“以上两个场景我们都有过,那么出现分片不均匀也就不足为奇了。
”
五、解决方案
1. 重启集群
在重启之前我们先来看看集群分片分配设置(allocation和rebalance):
#查到集群reblance和allocation属性
GET _cluster/settings复制
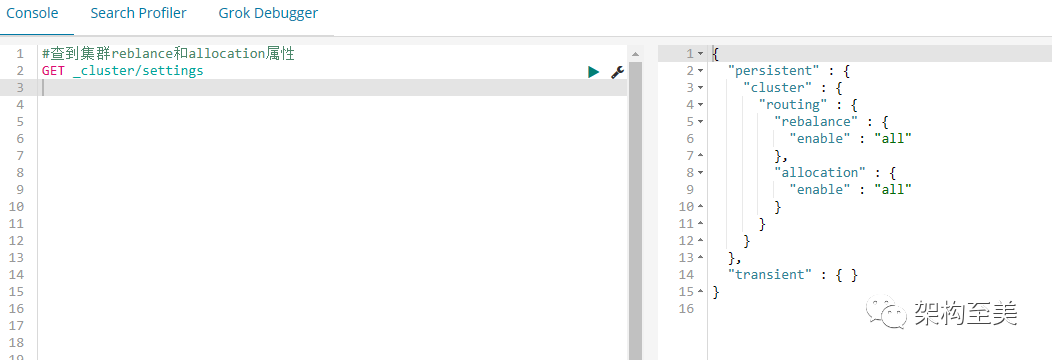
“参数说明: cluster.routing.allocation.enable-(动态) 启用或禁用特定类型分片的分配:
”
all-(默认值)允许为所有类型的分片分配分片。 primaries- 仅允许为主分片分配分片。 new_primaries- 仅允许为新索引的主分片分配分片。 none- 不允许对任何索引进行任何类型的分片分配。
“cluster.routing.rebalance.enable-(动态) 启用或禁用特定类型的分片的重新平衡:
”
all-(默认)允许对所有类型的分片进行分片平衡。 primaries- 仅允许主分片的分片平衡。 replicas- 仅允许副本分片的分片平衡。 none- 不允许对任何指数进行任何形式的分片平衡。
重启集群:
docker restart bdyh-es复制
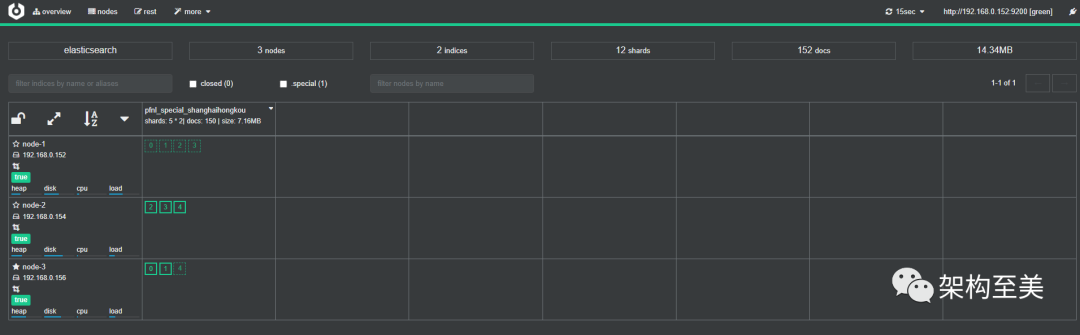
“经过多次重启,实践证明重启集群不会触发自动均衡。我认为这个时候和没重启之前是一样的,无法触发自动均衡策略,需要满足一定的条件后才能触发的。比如,手动去移动一些分片,改变当前的分片分布。
”
通过API来看一下未分配分片的原因:
GET /_cluster/allocation/explain
{
"index": "pfnl_special_shanghaihongkou",
"shard": 2,
"primary": false,
"current_node": "node-1"
}复制
“参数说明:
”
index: 索引 shard: 分片id primary: 是否有副本,false存在副本,true主分片id current_node: 节点名称
结果:
{
"index" : "pfnl_special_shanghaihongkou",
"shard" : 2,
"primary" : false,
"current_state" : "started",
"current_node" : {
"id" : "KHND3hLTRCu0lYJ71Nl70Q",
"name" : "node-1",
"transport_address" : "192.168.0.152:9300",
"attributes" : {
"ml.machine_memory" : "14330880000",
"ml.max_open_jobs" : "20",
"xpack.installed" : "true",
"ml.enabled" : "true"
},
"weight_ranking" : 1
},
"can_remain_on_current_node" : "yes",
"can_rebalance_cluster" : "yes",
"can_rebalance_to_other_node" : "no",
"rebalance_explanation" : "cannot rebalance as no target node exists that can both allocate this shard and improve the cluster balance",
"node_allocation_decisions" : [
{
"node_id" : "m9THMHMLQBuHtEVdRiLTAQ",
"node_name" : "node-2",
"transport_address" : "192.168.0.154:9300",
"node_attributes" : {
"ml.machine_memory" : "14330888192",
"ml.max_open_jobs" : "20",
"xpack.installed" : "true",
"ml.enabled" : "true"
},
"node_decision" : "no",
"weight_ranking" : 1,
"deciders" : [
{
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated to the same node on which a copy of the shard already exists [[pfnl_special_shanghaihongkou][2], node[m9THMHMLQBuHtEVdRiLTAQ], [P], s[STARTED], a[id=TDA78volSryaTJ5vcatp6A]]"
}
]
},
{
"node_id" : "685mB42hSB6tA0syP3UpFg",
"node_name" : "node-3",
"transport_address" : "192.168.0.156:9300",
"node_attributes" : {
"ml.machine_memory" : "14330880000",
"ml.max_open_jobs" : "20",
"xpack.installed" : "true",
"ml.enabled" : "true"
},
"node_decision" : "worse_balance",
"weight_ranking" : 1
}
]
}复制
“结果都是 "rebalance_explanation" : "cannot rebalance as no target node exists that can both allocate this shard and improve the cluster balance",翻译过来就是不能重新平衡,因为没有目标节点既可以分配这个分片,又可以改善集群平衡。
”
2. 关闭索引
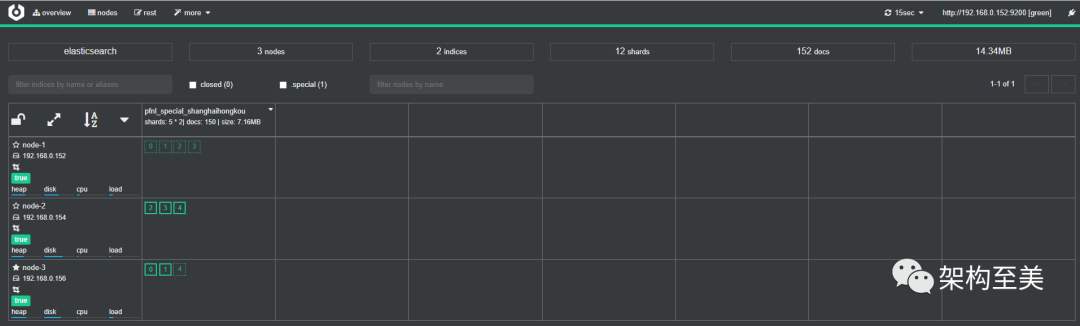
“关闭索引后再开启是否会触发自动均衡呢?
”
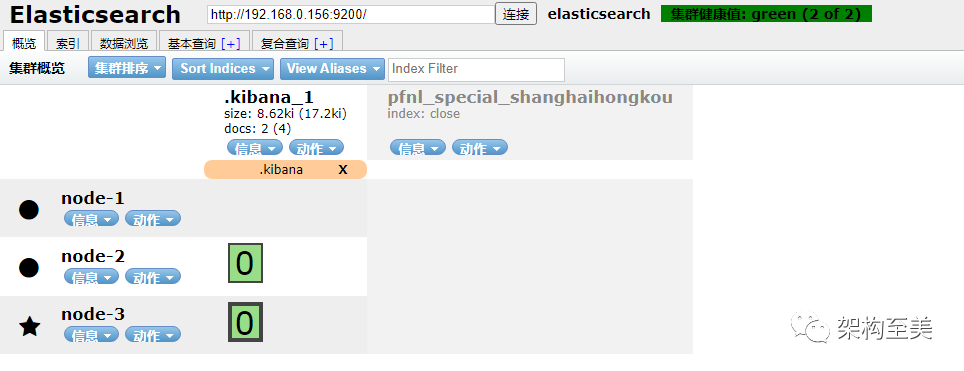
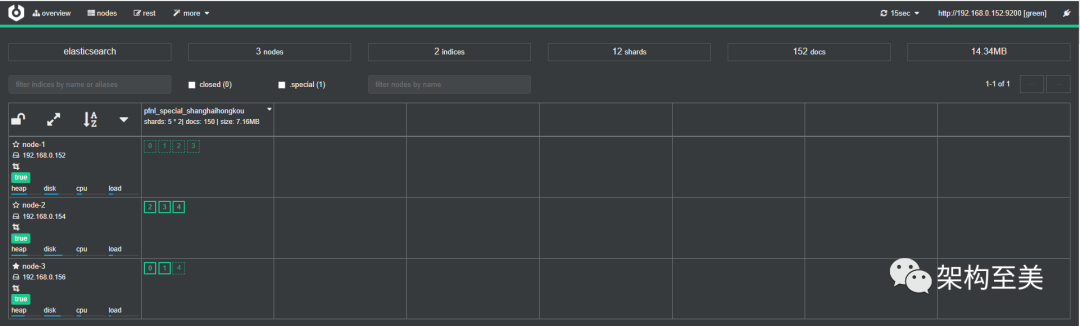
“再次开启索引后,并没有触发主分片自动均衡。
”
3. 通过API手动移动分片
移动node-1的分片0到node-2,看看会有什么效果,如下操作:
POST /_cluster/reroute
{
"commands" : [
{
"move" : {
"index" : "pfnl_special_shanghaihongkou", "shard" : 0,
"from_node" : "node-1", "to_node" : "node-2"
}
}
]
}复制
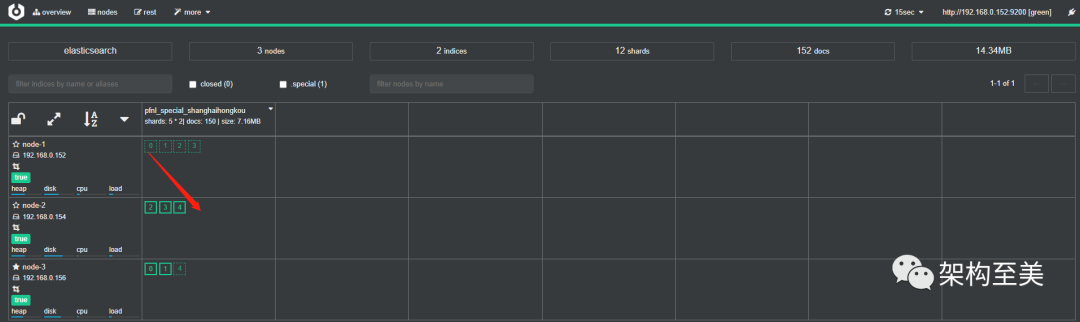
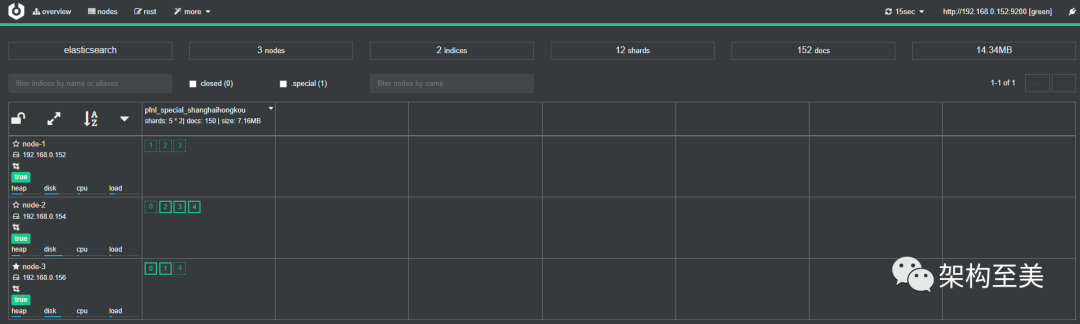
移动node-2的分片4到node-1,看看会有什么效果,如下操作:
POST /_cluster/reroute
{
"commands" : [
{
"move" : {
"index" : "pfnl_special_shanghaihongkou", "shard" : 4,
"from_node" : "node-2", "to_node" : "node-1"
}
}
]
}复制
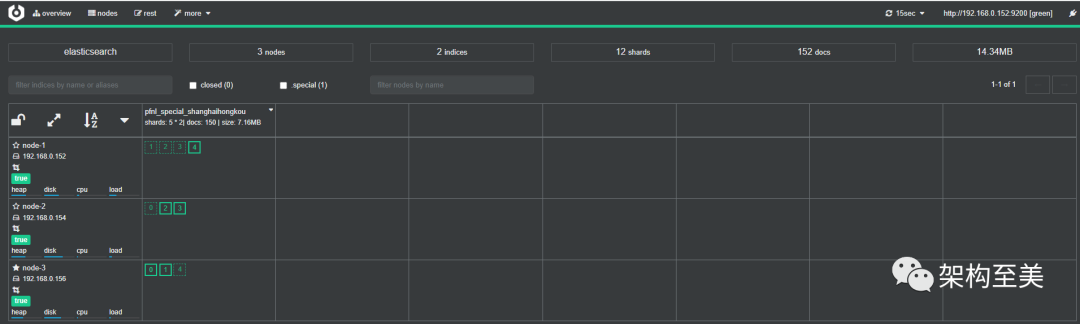
“通过上面可以看到,API手动移动分片可行。
”
优点:操作简单,恢复时间短,不必修改master node的配置。
缺点:索引大,移动时有很高的IO。
4. 取消副本
PUT /pfnl_special_shanghaihongkou/_settings
{
"number_of_replicas": 0
}复制
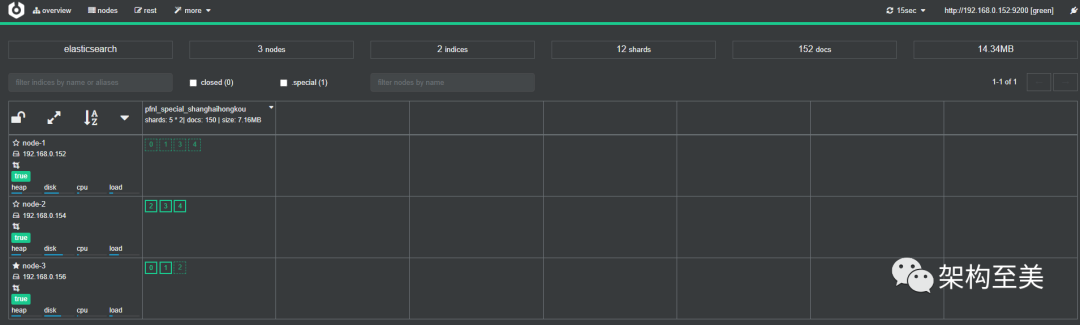
“取消副本之前。
”
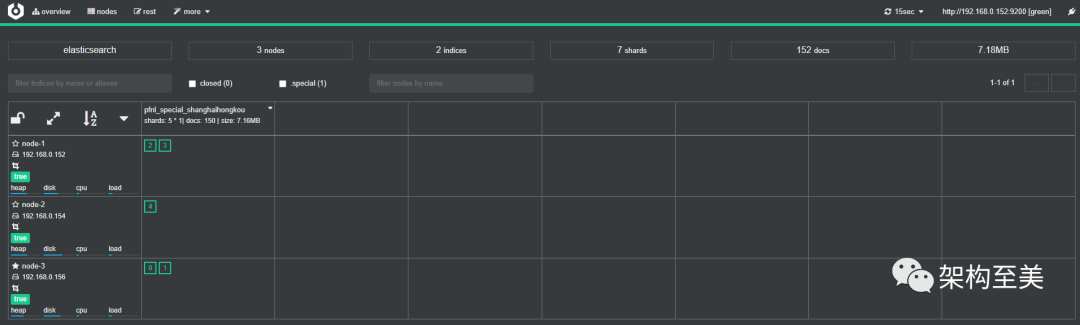
“实践证明,取消副本之后,一定会触发均衡策略。
”


