




因Clickhouse运维的坑太多,我们在一个数据量较大的业务上使用了一个单节点的CK来简化运维工作。随着我们在CK上逐步掉落到一个又一个坑里,我们也开始逐步积累了一点点CK运维的经验,打算把这个单节点的CK上的表逐步加上副本集,我们先来看看涉及到的相关知识点。
Clickhouse 副本
关于Clickhouse的副本,我主要参考了以下二篇文章:
https://blog.csdn.net/qq_42194171/article/details/109703100
https://blog.csdn.net/aizhupo1314/article/details/121378994
Clickhouse 的副本是完全基于表的,只有有Replicated前缀的Mergetree引擎才能开启副本集, 我们生产环境就有些表建表的时候使用的MergeTree,这个就没办法直接做副本,需要转换引擎,基本上MergeTree家族的引擎都有相对应的Replicated 引擎。
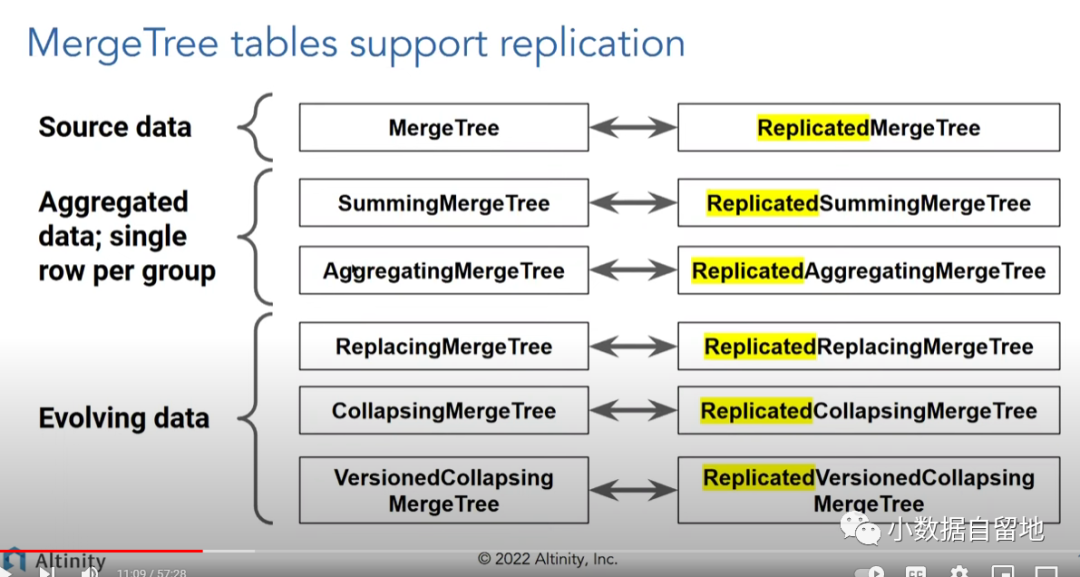
Clickhouse的数据副本的同步流程如下图:
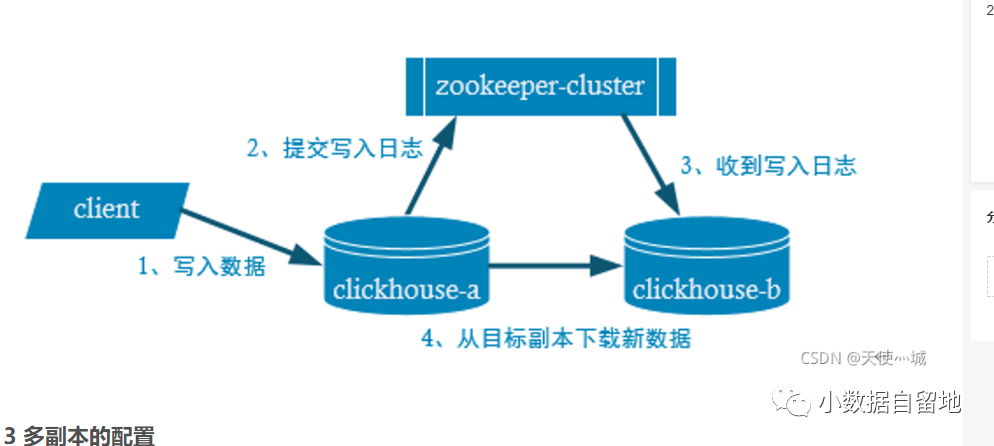
副本同步机制是通过Zookeeper的监听机制实现的,当我们向Node1发送写入操作请求,首先Node1会先写入数据,然后Node1 推送操作日志到zookeeper集群中的预先定义好的表的log路径下,Node2 通过监听zk log目录发现Node1有新的数据写入, Node2 从zookeeper上下载操作日志,然后从Node1下载副本到本地。
zookeeper中记录操作日志的目录是在建replicated表的时候指定的zkpath目录下的log文件夹, 比如
/clickhouse/tables/{cluster}/{shared}/{tables}/log,这个数据在CK的system.zookeeper里面也是可以实时查到的:
select * from zookeeper where path='/clickhouse/tables/test/01/ELK_LOG_SHARD/log' limit 1;create_time: 2023-02-02 16:54:27source replica: 46161.ck.navrmo.mlblock_id: 20230202_7543699351354629130_2976871714623993796get20230202_35285_35285_0part_type: Compact│ 159444020287 │ 159444020287 │ 2023-02-02 16:52:46 │ 2023-02-02 16:52:46 │ 0 │ 0 │ 0 │ 0 │ 191 │ 0 │ 159444020287 │ clickhouse/tables/test/01/ELK_LOG_SHARD/log │复制
这里我们可以很清晰的看到source replicas, block id 等信息。
我们看完了CK的副本同步原理以后,可以看到CK的副本主要依赖Replicated*MergeTree和Zookeeper完成.
从单节点单副本到双节点双副本
单节点的CK是完全可以不需要配置zookeeper的, 但我们当时安装单节点的时候还是配置了zk,也只有这样才能建replicated的表。
我们先来看看zk的配置, zk的配置每个节点都是一样的,既可以直接在/etc/clickhouse-server/config.xml 配置,也可以在/etc/clickhouse-server/config.d/metrika.xml 中配置(更建议以这方式配置),
<zookeeper><node index="1"><host>192.72.83.135</host><port>2181</port></node><node index="2"><host>192.72.83.136</host><port>2181</port></node><node index="3"><host>192.72.83.137</host><port>2181</port></node></zookeeper>复制
然后以include的方式添加到config.xml文件中:
<yandex><include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from></yandex>复制
我们再在metrika.xml 中配置下集群相关的配置,这个也是每个节点相同,这里可以看到我们配置的是一个1个shard2个replicas的集群。
<remote_servers><rtdw><shard><internal_replication>true</internal_replication><replica><host>46161.ck.ml</host><port>9000</port></replica><replica><host>46152.ck.ml</host><port>9000</port></replica></shard></rtdw></remote_servers>复制
每个节点需要个性化的配置主要是放在/etc/clickhouse-server/config.d/macros.xml,这里replica就是指定该节点的replicas的名字,比如这里我们这个节点上面表的replicas就叫做46161.ck.ml
<yandex><macros><cluster>rtdw</cluster><shard>01</shard><replica>46161.ck.ml</replica></macros></yandex>复制
这样我们一个双节点双副本的集群就配置好了,直接在2个节点上重启服务,在CK里面就可以查到的集群信息了:
select * from system.clusters where cluster='rtdw';┌─cluster─┬─shard_num─┬─shard_weight─┬─replica_num─┬─host_name──────────┬─host_address─────────────────┬─port─┬─is_local─┬─user────┬─default_database─┬─errors_count─┬─slowdowns_count─┬─estimated_recovery_time─┐│ rtdw │ 1 │ 1 │ 1 │ 46161.ck.ml │ 10.72.46.161 │ 9000 │ 0 │ default │ │ 0 │ 0 │ 0 ││ rtdw │ 1 │ 1 │ 2 │ 46152.ck.ml │ fe80::5054:ff:fe20:9339%eth0 │ 9000 │ 1 │ default │ │ 0 │ 0 │ 0 │└─────────┴───────────┴──────────────┴─────────────┴────────────────────┴──────────────────────────────┴──────┴──────────┴─────────┴──────────────────┴──────────────┴─────────────────┴─────────────────────────┘复制
建表和数据同步
这时候二台CK服务器端的工作就已经准备好了,只需要在新节点建好replicated的表就行了, 官网的例子如下:
CREATE TABLE table_name(EventDate DateTime,CounterID UInt32,UserID UInt32,ver UInt16) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/table_name', '{replica}')PARTITION BY toYYYYMM(EventDate)ORDER BY (CounterID, EventDate, intHash32(UserID))SAMPLE BY intHash32(UserID);复制
其中{shard}和{replicas}就是我们在服务器的macros.xml文件中个性化配置的参数。
在新节点建好表后,我们首先会在zk的replicas目录下观察到新的ck节点的加入:
ls /clickhouse/tables/test/01/ELK_LOG_SHARD/replicas[46152.ck.ml, 46161.ck.ml]复制
然后新节点就开始自动replication该表的数据了, 这个直接在新节点的表里面查看数据量就可以观察到。
小结
CK的副本机制是基于表级别的,本文这里描述的同步机制还是基于的zk的,在新的节点配置好zk和集群,定义好节点replcias的名称,然后建Replicated*MergeTree的表,新节点的上的表就会自动开始副本的同步。CK已经发布了ClickHouse-keeper来替代zk,虽然说官方文档已经开始建议用ClickHouse-keeper来替代zk, 但我看了下网上的文档大家还是建议让子弹再飞一会。
