




PG中的WAL:1 buffer cache
为什么需要WAL日志
数据库管理系统需要操作的数据位于RAM,并会异步刷写到磁盘或其他非易失性存储介质。写被推迟,推迟时间越久IO次数越少,系统操作越快。
但如果有故障,例如断电或代码bug或操作系统故障会发生什么?RAM中所有内容会丢失,仅持久化到磁盘的数据会保留(磁盘也不能幸免于故障,如果发生仅备份能够提供帮助)。当然也可通过同步的方式刷写来保证一致性,但这样比较复杂且不高效,据我所知仅Firebird采用这种方式。
通常特别是PG中,写入磁盘的数据不能保证一致性,在故障恢复时需要特殊的操作来恢复数据,WAL日志只是使其成为可能的一个特性。
Buffer cache
从buffer cache开始讨论WAL。Buffer cache是RAM中最重要且最复杂的结构之一。理解如何工作非常重要,此外我们将之作为一个例子,以了解RAM和磁盘如何交换数据。
现代计算机到处都在使用cache,一个处理器本身就有三级或四级cache。。一般来说,需要缓存来缓解两种内存之间的性能差异,其中一种内存相对较快,但不够循环使用,另一种内存相对较慢,但足够使用。缓冲区缓存减轻了访问内存(纳秒)和磁盘存储(毫秒)的时间差异。
请注意,操作系统也有解决相同问题的磁盘缓存。因此,数据库管理系统通常通过直接访问磁盘而不是通过操作系统缓存来避免双重缓存。但PostgreSQL的情况并非如此:所有数据都是使用正常的文件操作读写的。
此外,磁盘阵列的控制器甚至磁盘本身也有自己的缓存。当我们讨论可靠性时,这将是有用的。
但是让我们回到DBMS缓冲区缓存。
之所以这样称呼他是因为他被表示为buffers数组。每个buffer由数据页和数据页头组成。其中页头包括:页面在缓冲区的位置;是否为脏的标记,buffer的使用次数,buffer的pin次数。
缓冲区缓存位于服务器的共享内存中,所有进程都可以访问。为了处理数据,即读取或更新数据,进程将页面读入缓存。当页面在缓存中时,我们在内存中处理它,并在磁盘访问时保存。
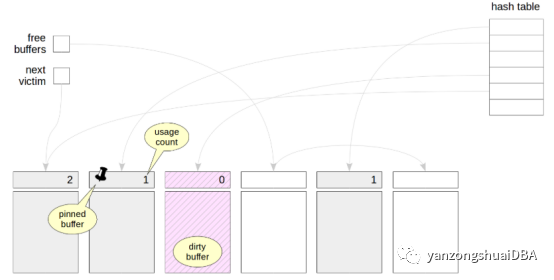
缓存最初包含空缓冲区,所有缓冲区都链接到空闲缓冲区列表中。指向“next victim”的指针的含义稍后将会清楚。缓存中的哈希表用于快速找到您需要的页面。
在cache中查询一个页
当一个进程需要读取一个页面时,它首先试图通过哈希表在缓冲区缓存中找到它。文件OID和文件中的页号用作哈希键。该过程在适当的散列桶中找到缓冲区号,并检查它是否真的包含所需的页面。与任何哈希表一样,这里可能会出现冲突,在这种情况下,该过程将不得不检查几页。
哈希表的使用长期以来一直是抱怨的来源。这个结构可以通过页号迅速找到内存中对应的buffer,但是如需要找到某一个表的所有buffer时,这个结构就是无用的。
如果在缓存中找到了所需的页面,进程必须通过增加pin数来“pin”缓冲区(几个进程可以同时这样做)。当一个缓冲区被固定(计数值大于零)时,它被认为是被使用的,并且具有不能“drastically”改变的内容。例如:一个新的元组可以出现在页面上——由于多版本并发和可见性规则,这对任何人都没有害处。但是不能将不同的页面读入pin的缓冲区。
驱逐
缓存中可能找不到所需的页面。在这种情况下,需要将页面从磁盘读入某个缓冲区。
如果缓存中仍有空缓冲区,则选择第一个空缓冲区。但它们迟早会结束(数据库的大小通常大于分配给缓存的内存),然后我们必须选择一个已占用的缓冲区,驱逐位于那里的页面,并将新页面读取到已释放的空间中。
驱逐技术基于这样一个事实,即对于对缓冲区的每次访问,进程都会增加缓冲区头中的使用计数。因此,使用频率较低的缓冲区具有较小的计数值,因此是驱逐的良好候选对象。
这时钟扫描算法循环遍历所有缓冲区(使用指向“next victim”的指针)并将它们的使用计数减少1。被选择用于驱逐的缓冲区是第一个:
1、使用计数为零
2、Pin数为零(即未被固定)
请注意,如果所有缓冲区都有非零使用计数,算法将不得不在缓冲区中循环不止一次,减少计数值,直到其中一些减少到零。对于避免“跑圈”的算法,使用计数的最大值被限制为5。但是,对于大容量缓冲区缓存,该算法会导致相当大的开销。
一旦找到缓冲区,就会发生以下情况。
缓冲区被锁定,以显示它正在使用的其他进程。除了锁定之外,还使用了其他锁定技术,但我们将在后面更详细地讨论这一点。
如果缓冲区看起来脏,也就是说,要包含已更改的数据,就不能直接删除页面,需要先将其保存到磁盘上。这不是一个好的情况,因为要读取页面的进程必须等到其他进程的数据被写入,但是检查点和后台写入器进程减轻了这种影响,这将在后面讨论。
然后,新页面从磁盘读入选定的缓冲区。使用计数被设置为等于1。此外,必须将对加载页面的引用写入哈希表,以便将来能够找到该页面。
对“next victim”的引用现在指向下一个缓冲区,刚刚加载的缓冲区有时间增加使用计数,直到指针循环通过整个缓冲区缓存并再次返回。
查看buffer cache
可通过扩展pg_buffercache查看buffer cache。:
=> CREATE TABLE cacheme(id integer) WITH (autovacuum_enabled = off);=> INSERT INTO cacheme VALUES (1);复制
缓冲区缓存将包含什么?至少,必须有元祖对应的这个页。让我们使用下面的查询来检查这一点,该查询只选择与我们的表相关的缓冲区(由relfilenode号)并解释relforknumber:
=> SELECT bufferid,CASE relforknumberWHEN 0 THEN 'main'WHEN 1 THEN 'fsm'WHEN 2 THEN 'vm'END relfork,relblocknumber,isdirty,usagecount,pinning_backendsFROM pg_buffercacheWHERE relfilenode = pg_relation_filenode('cacheme'::regclass);bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends----------+---------+----------------+---------+------------+------------------15735 | main | 0 | t | 1 | 0(1 row)复制
正如我们所想:缓冲区包含一页。很脏(isdirty),使用计数(使用计数)等于1,并且页面没有被任何进程锁定(锁定_后端).
现在让我们再添加一行并重新运行查询。为了保存击键,我们在另一个会话中插入该行,并使用\g命令。
| => INSERT INTO cacheme VALUES (2);=> \gbufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends----------+---------+----------------+---------+------------+------------------15735 | main | 0 | t | 2 | 0(1 row)复制
没有添加新的缓冲区,第二个元祖落在了同一页,注意使用次数的增加
| => SELECT * FROM cacheme;| id| ----| 1| 2| (2 rows)=> \gbufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends----------+---------+----------------+---------+------------+------------------15735 | main | 0 | t | 3 | 0(1 row)复制
读后,增加了次数。Vacuum后呢?
| => VACUUM cacheme;=> \gbufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends----------+---------+----------------+---------+------------+------------------15731 | fsm | 1 | t | 1 | 015732 | fsm | 0 | t | 1 | 015733 | fsm | 2 | t | 2 | 015734 | vm | 0 | t | 2 | 015735 | main | 0 | t | 3 | 0(5 rows)复制
Vacuum创建了可见性map文件(一个页)以及fsm(3个页)。
调整大小
Cache大小的参数是shared_buffers。默认是128MB。改变这个参数需要重启服务。因为分配的cache的内存在服务启动时分配。
=> SELECT setting, unit FROM pg_settings WHERE name = 'shared_buffers';setting | unit---------+------16384 | 8kB(1 row)复制
如果选择一个合适的值?
即使是最大的数据库也有一组有限的“热”数据,这些数据总是被集中处理。理想情况下,这个数据集必须适合缓冲区缓存(加上一些一次性数据的空间)。如果缓存的大小越来越小,那么密集使用的页面就会不断地相互驱逐,这将导致过多的输入/输出。但是盲目增加缓存也不好。当缓存很大时,其维护的开销成本会增加,此外,其他用途也需要内存。
因此,您需要为您的特定系统选择最佳的缓冲区缓存大小:这取决于数据、应用程序和负载。不幸的是,没有神奇的、一刀切的价值。
通常建议取1/4的RAM作为第一近似值(低于10的PostgreSQL版本建议Windows使用较小的大小)。
然后要适应情况。最好是实验:增加或减少缓存大小,比较系统特性。为此,您当然需要一个测试平台,并且您应该能够重现工作负载。—在生产环境中进行这样的实验是一种可疑的乐趣。
=> SELECT usagecount, count(*)FROM pg_buffercacheGROUP BY usagecountORDER BY usagecount;usagecount | count------------+-------1 | 2212 | 8693 | 294 | 125 | 564| 14689(6 rows)复制
在这种情况下,计数的多个空值对应于空缓冲区。对于一个什么都没有发生的系统来说,这并不奇怪。
我们可以看到哪些表在我们的数据库中被缓存了,这些数据被使用得多频繁(通过“频繁使用”,在这个查询中使用计数大于3的缓冲区是指):
=> SELECT c.relname,count(*) blocks,round( 100.0 * 8192 * count(*) / pg_table_size(c.oid) ) "% of rel",round( 100.0 * 8192 * count(*) FILTER (WHERE b.usagecount > 3) / pg_table_size(c.oid) ) "% hot"FROM pg_buffercache bJOIN pg_class c ON pg_relation_filenode(c.oid) = b.relfilenodeWHERE b.reldatabase IN (0, (SELECT oid FROM pg_database WHERE datname = current_database()))AND b.usagecount is not nullGROUP BY c.relname, c.oidORDER BY 2 DESCLIMIT 10;relname | blocks | % of rel | % hot---------------------------+--------+----------+-------vac | 833 | 100 | 0pg_proc | 71 | 85 | 37pg_depend | 57 | 98 | 19pg_attribute | 55 | 100 | 64vac_s | 32 | 4 | 0pg_statistic | 27 | 71 | 63autovac | 22 | 100 | 95pg_depend_reference_index | 19 | 48 | 35pg_rewrite | 17 | 23 | 8pg_class | 16 | 100 | 100(10 rows)复制
例如:我们可以在这里看到vac表占据了大部分空间(我们在前面的一个主题中使用了这个表),但是它没有被访问很长时间,也没有被收回,只是因为空缓冲区仍然可用。
可以考虑其他观点,会给你提供思考的食粮。你只需要考虑到:
您需要多次重新运行这样的查询:数量将在一定范围内变化。
您不应该连续运行这样的查询(作为监控的一部分),因为扩展会暂时阻止对缓冲区缓存的访问。
还有一点需要注意。也不要忘记PostgreSQL通过通常的操作系统调用来处理文件,因此会发生双重缓存:页面同时进入数据库管理系统的缓冲区缓存和操作系统缓存。因此,不命中缓冲区缓存并不总是需要实际的输入/输出。但是操作系统的驱逐策略不同于数据库管理系统:操作系统对读取数据的含义一无所知。
大规模驱逐
大批量读和写操作容易有这样的风险,即有用的页面可能被“一次性”数据从缓冲区高速缓存中快速逐出。
为了避免这种情况,所以缓冲环使用:每次操作只分配一小部分缓冲区缓存。驱逐仅在环内执行,因此缓冲区缓存中的其余数据不受影响。
对于大型表(其大小大于缓冲区缓存的四分之一)的顺序扫描,会分配32页。如果在扫描表的过程中,另一个进程也需要这些数据,它不会从头开始读取表,而是连接到已经可用的缓冲环。完成扫描后,该过程继续从表开始读取。
让我们验证一下。为此,让我们创建一个表,使一行占据整个页面——这样计数更方便。缓冲区缓存的默认大小为128MB= 16384个8 KB页。这意味着我们需要向表中插入超过4096行,即页面。
=> CREATE TABLE big(id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,s char(1000)) WITH (fillfactor=10);=> INSERT INTO big(s) SELECT 'FOO' FROM generate_series(1,4096+1);执行analyze:=> ANALYZE big;=> SELECT relpages FROM pg_class WHERE oid = 'big'::regclass;relpages----------4097(1 row)复制
重启服务后读取整个表:
student$ sudo pg_ctlcluster 11 main restart=> EXPLAIN (ANALYZE, COSTS OFF) SELECT count(*) FROM big;QUERY PLAN---------------------------------------------------------------------Aggregate (actual time=14.472..14.473 rows=1 loops=1)-> Seq Scan on big (actual time=0.031..13.022 rows=4097 loops=1)Planning Time: 0.528 msExecution Time: 14.590 ms(4 rows)复制
让我们确保表页只占用缓冲区缓存中的32个缓冲区:
=> SELECT count(*)FROM pg_buffercacheWHERE relfilenode = pg_relation_filenode('big'::regclass);count-------32(1 row)复制
但是如果我们禁止顺序扫描,将使用索引扫描读取该表:
=> SET enable_seqscan = off;=> EXPLAIN (ANALYZE, COSTS OFF) SELECT count(*) FROM big;QUERY PLAN-------------------------------------------------------------------------------------------Aggregate (actual time=50.300..50.301 rows=1 loops=1)-> Index Only Scan using big_pkey on big (actual time=0.098..48.547 rows=4097 loops=1)Heap Fetches: 4097Planning Time: 0.067 msExecution Time: 50.340 ms(5 rows)复制
在这种情况下,不使用缓冲环,整个表将进入缓冲区缓存(几乎整个索引也是如此):
=> SELECT count(*)FROM pg_buffercacheWHERE relfilenode = pg_relation_filenode('big'::regclass);count-------4097(1 row)复制
缓冲环以类似的方式用于vacuum处理(也是32页)和批量写入操作复制输入和创建选择表(通常为2048页,但不超过缓冲区缓存的1/8)。
临时表
临时表是普通规则的例外。因为临时数据只对一个进程可见,所以在共享缓冲区缓存中不需要它们。此外,临时数据只存在于一个会话中,因此不需要针对故障的保护。
临时数据使用拥有该表的进程的本地内存中的缓存。因为这样的数据只对一个进程可用,所以它们不需要用锁来保护。本地缓存使用正常的驱逐算法。
与共享缓冲区缓存不同,本地缓存的内存是根据需要分配的,因为临时表在许多会话中很少使用。单个会话中临时表的最大内存大小受temp_buffers参数。
预热缓存
服务器重新启动后,缓存必须经过一段时间才能“预热”,也就是说,用活动使用的数据填充。有时,将某些表的内容立即读取到缓存中似乎很有用,为此有一个专门的扩展:
=> CREATE EXTENSION pg_prewarm;
早期,该扩展只能将某些表读入缓冲区缓存(或只读入操作系统缓存)。但是PostgreSQL 11使它能够将缓存的最新状态保存到磁盘上,并在服务器重新启动后恢复它。要使用它,您需要将库添加到shared_preload_libraries 并重新启动服务器。
=> ALTER SYSTEM SET shared_preload_libraries = 'pg_prewarm';student$ sudo pg_ctlcluster 11 main restart复制
重新启动后,如果pg_prewarm.autoprewarm参数没有改变,则发起autoprewarm master后台进程,该进程将每隔一次pg_prewarm.autoprewarm_interval秒(设置的值时,不要忘记计算新进程的数量max_parallel_processes).刷新缓存中存储的页面列表。PG13中进程名改成了autoprewarm leader。
=> SELECT name, setting, unit FROM pg_settings WHERE name LIKE 'pg_prewarm%';name | setting | unit---------------------------------+---------+------pg_prewarm.autoprewarm | on |pg_prewarm.autoprewarm_interval | 300 | s(2 rows)postgres$ ps -o pid,command --ppid `head -n 1 var/lib/postgresql/11/main/postmaster.pid` | grep prewarm10436 postgres: 11/main: autoprewarm master复制
现在,cache中没有表big:
=> SELECT count(*)FROM pg_buffercacheWHERE relfilenode = pg_relation_filenode('big'::regclass);count-------0(1 row)复制
如果我们认为它的所有内容都是关键的,我们可以通过调用以下函数将它读入缓冲区缓存:
=> SELECT pg_prewarm('big');pg_prewarm------------4097(1 row)=> SELECT count(*)FROM pg_buffercacheWHERE relfilenode = pg_relation_filenode('big'::regclass);count-------4097(1 row)复制
这些页刷写到文件autoprewarm.blocks。等autoprewarm master进程第一次完成后,或者执行下面命令:
=> SELECT autoprewarm_dump_now();autoprewarm_dump_now----------------------4340(1 row)复制
刷新的页数已经超过4097;服务器已经读取的系统catalog 的页面被计算在内。这是文件:
postgres$ ls -l /var/lib/postgresql/11/main/autoprewarm.blocks-rw------- 1 postgres postgres 102078 jun 29 15:51 /var/lib/postgresql/11/main/autoprewarm.blocks复制
重启后再次查看:
=> SELECT count(*)FROM pg_buffercacheWHERE relfilenode = pg_relation_filenode('big'::regclass);count-------4097(1 row)复制
一样的autoprewarm master进程为此做好了准备:读取文件,按数据库划分页面,对它们进行排序(尽可能按顺序从磁盘读取),并将它们传递给单独的autoprewarm worker进程进行处理。
原文
https://postgrespro.com/blog/pgsql/5967951




