




第一章 索引跳跃扫描介绍
索引跳跃式扫描(INDEX SKIP SCAN),它使那些在where条件中没有对目标索引的前导列指定查询条件但同时又对该索引的非前导列指定了查询条件的目标SQL依然可以用上该索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样(实际的执行过程并非如此),这也是索引跳跃式扫描中"跳跃"(SKIP)一词的含义。
为什么在where条件中没有对目标索引的前导列指定查询条件但Oracle依然可以用上该索引呢?这是因为Oracle帮你对该索引的前导列的所有distinct值做了遍历。
根据上述描述,提出以下疑问:
没有使用索引前导列查询,才可能出现索引跳跃扫描?
出现了索引跳跃扫描,一定比索引范围扫描效率更低?
下面分别进行分析及测试:
--创建测试表: CREATE TABLE TEST_SKIPSCAN AS SELECT LPAD(TRUNC(dbms_random.value(1,20)),2,0) C1,LPAD(MOD(ROWNUM,500),100,0) C2 FROM DUAL CONNECT BY ROWNUM<5000;复制
C1列有20个随机生成的唯一值;
C2列是平均分配的500个唯一值。
为了避免一个数据块包含的行数过多,对C2列补0数据到100位。
--创建索引及统计信息 CREATE INDEX IDX_SKIPSCAN_C1_C2 on TEST_SKIPSCAN(C1,C2); EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>'SZT',TABNAME=>'TEST_SKIPSCAN');复制
对C1、C2列创建复合索引。
第二章 典型的索引跳跃扫描
典型的索引跳扫为不包含索引前导列的查询。实验脚本如下:
SELECT COUNT(*) FROM TEST_SKIPSCAN T WHERE C2=LPAD(160,100,0);复制
执行计划如下:
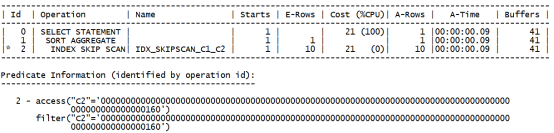
2.1获取索引的层级结构
首先估算一下索引的叶子块数量:
索引条目大小:索引条目头(按4字节算)+表示第一个索引列的长度(1字节)+第一个索引列的值(2字节)+第二个索引列的长度(1字节)+第二个索引列的值(100字节)+ROWID(6字节)约等于114字节。
按照索引叶子块有效存储空间7000字节算,5000行/(7000/114)约等于81个叶子块。
通过以下方式获取索引层级结构:
1.获取OBJECT_ID:

2.转储索引结构:
alter session set events 'immediate trace name treedump level 94562';复制
3.获取TRACE文件目录,得到转储文件:
select value from v$diag_info where name like '%Default%';复制
转储后的索引结构如下:
----- begin tree dump branch: 0x100e733 16836403 (0: nrow: 2, level: 2) branch: 0x1052483 17114243 (-1: nrow: 73, level: 1) leaf: 0x100e734 16836404 (-1: nrow: 62 rrow: 62) leaf: 0x100e735 16836405 (0: nrow: 62 rrow: 62) leaf: 0x100e736 16836406 (1: nrow: 62 rrow: 62) leaf: 0x100e737 16836407 (2: nrow: 62 rrow: 62) leaf: 0x1028cd8 16944344 (3: nrow: 62 rrow: 62) leaf: 0x1028cd9 16944345 (4: nrow: 62 rrow: 62) leaf: 0x1028cda 16944346 (5: nrow: 62 rrow: 62) leaf: 0x1028cdb 16944347 (6: nrow: 62 rrow: 62) leaf: 0x1028cdc 16944348 (7: nrow: 62 rrow: 62) leaf: 0x1028cdd 16944349 (8: nrow: 62 rrow: 62) leaf: 0x1028cde 16944350 (9: nrow: 62 rrow: 62) leaf: 0x1028cdf 16944351 (10: nrow: 62 rrow: 62) leaf: 0x1028ce1 16944353 (11: nrow: 62 rrow: 62) leaf: 0x1028ce2 16944354 (12: nrow: 62 rrow: 62) leaf: 0x1028ce3 16944355 (13: nrow: 62 rrow: 62) leaf: 0x1028ce4 16944356 (14: nrow: 62 rrow: 62) leaf: 0x1028ce5 16944357 (15: nrow: 62 rrow: 62) leaf: 0x1028ce6 16944358 (16: nrow: 62 rrow: 62) leaf: 0x1028ce7 16944359 (17: nrow: 62 rrow: 62) leaf: 0x1028ce8 16944360 (18: nrow: 62 rrow: 62) leaf: 0x1028ce9 16944361 (19: nrow: 62 rrow: 62) leaf: 0x1028cea 16944362 (20: nrow: 62 rrow: 62) leaf: 0x1028ceb 16944363 (21: nrow: 62 rrow: 62) leaf: 0x1028cec 16944364 (22: nrow: 62 rrow: 62) leaf: 0x1028ced 16944365 (23: nrow: 62 rrow: 62) leaf: 0x1028cee 16944366 (24: nrow: 62 rrow: 62) leaf: 0x1028cef 16944367 (25: nrow: 62 rrow: 62) leaf: 0x1028cf1 16944369 (26: nrow: 62 rrow: 62) leaf: 0x1028cf2 16944370 (27: nrow: 62 rrow: 62) leaf: 0x1028cf3 16944371 (28: nrow: 62 rrow: 62) leaf: 0x1028cf4 16944372 (29: nrow: 62 rrow: 62) leaf: 0x1028cf5 16944373 (30: nrow: 62 rrow: 62) leaf: 0x1028cf6 16944374 (31: nrow: 62 rrow: 62) leaf: 0x1028cf7 16944375 (32: nrow: 62 rrow: 62) leaf: 0x1028cf8 16944376 (33: nrow: 62 rrow: 62) leaf: 0x1028cf9 16944377 (34: nrow: 62 rrow: 62) leaf: 0x1028cfa 16944378 (35: nrow: 62 rrow: 62) leaf: 0x1028cfb 16944379 (36: nrow: 62 rrow: 62) leaf: 0x1028cfc 16944380 (37: nrow: 62 rrow: 62) leaf: 0x1028cfd 16944381 (38: nrow: 62 rrow: 62) leaf: 0x1028cfe 16944382 (39: nrow: 62 rrow: 62) leaf: 0x1028cff 16944383 (40: nrow: 62 rrow: 62) leaf: 0x102c049 16957513 (41: nrow: 62 rrow: 62) leaf: 0x102c04a 16957514 (42: nrow: 62 rrow: 62) leaf: 0x102c04b 16957515 (43: nrow: 62 rrow: 62) leaf: 0x102c04c 16957516 (44: nrow: 62 rrow: 62) leaf: 0x102c04d 16957517 (45: nrow: 62 rrow: 62) leaf: 0x102c04e 16957518 (46: nrow: 62 rrow: 62) leaf: 0x102c04f 16957519 (47: nrow: 62 rrow: 62) leaf: 0x102c050 16957520 (48: nrow: 62 rrow: 62) leaf: 0x102c051 16957521 (49: nrow: 62 rrow: 62) leaf: 0x102c052 16957522 (50: nrow: 62 rrow: 62) leaf: 0x102c053 16957523 (51: nrow: 62 rrow: 62) leaf: 0x102c054 16957524 (52: nrow: 62 rrow: 62) leaf: 0x102c055 16957525 (53: nrow: 62 rrow: 62) leaf: 0x102c056 16957526 (54: nrow: 62 rrow: 62) leaf: 0x102c057 16957527 (55: nrow: 62 rrow: 62) leaf: 0x102c059 16957529 (56: nrow: 62 rrow: 62) leaf: 0x102c05a 16957530 (57: nrow: 62 rrow: 62) leaf: 0x102c05b 16957531 (58: nrow: 62 rrow: 62) leaf: 0x102c05c 16957532 (59: nrow: 62 rrow: 62) leaf: 0x102c05d 16957533 (60: nrow: 62 rrow: 62) leaf: 0x102c05e 16957534 (61: nrow: 62 rrow: 62) leaf: 0x102c05f 16957535 (62: nrow: 62 rrow: 62) leaf: 0x102c060 16957536 (63: nrow: 62 rrow: 62) leaf: 0x102c061 16957537 (64: nrow: 62 rrow: 62) leaf: 0x102c062 16957538 (65: nrow: 62 rrow: 62) leaf: 0x102c063 16957539 (66: nrow: 62 rrow: 62) leaf: 0x102c064 16957540 (67: nrow: 62 rrow: 62) leaf: 0x102c065 16957541 (68: nrow: 62 rrow: 62) leaf: 0x102c066 16957542 (69: nrow: 62 rrow: 62) leaf: 0x102c067 16957543 (70: nrow: 62 rrow: 62) leaf: 0x1052481 17114241 (71: nrow: 62 rrow: 62) branch: 0x105248b 17114251 (0: nrow: 8, level: 1) leaf: 0x1052482 17114242 (-1: nrow: 62 rrow: 62) leaf: 0x1052484 17114244 (0: nrow: 62 rrow: 62) leaf: 0x1052485 17114245 (1: nrow: 62 rrow: 62) leaf: 0x1052486 17114246 (2: nrow: 62 rrow: 62) leaf: 0x1052487 17114247 (3: nrow: 62 rrow: 62) leaf: 0x1052488 17114248 (4: nrow: 62 rrow: 62) leaf: 0x1052489 17114249 (5: nrow: 62 rrow: 62) leaf: 0x105248a 17114250 (6: nrow: 39 rrow: 39) ----- end tree dump复制
与我们预估的叶子块数量基本一致。包含81个索引叶子块、2个分支块、一个根块。
2.2获取跳跃扫描的数据块:
为了明确跳跃扫描究竟访问了哪些数据块,采用了何种方式。需要使用10200跟踪事件。操作方法如下:
1.开启跟踪事件:
alter session set events '10200 trace name context forever,level 1';复制
2.执行SQL:
3.关闭跟踪事件:
alter session set events '10200 trace name context off';复制
4.获取TRACE文件:
select value from v$diag_info where name like '%Default%';复制
上述索引跳跃扫描,访问的数据块情况如下:
0x100e733 0x1052483 0x100e734 0x1028cd8 0x1028cd9 0x1028cdc 0x1028cdd 0x1028ce1 0x1028ce2 0x1028ce5 0x1028ce7 0x1028cea 0x1028ceb 0x1028cee 0x1028cef 0x1028cf3 0x1028cf4 0x1028cf7 0x1028cf8 0x1028cfb 0x1028cfd 0x102c049 0x102c04a 0x102c04d 0x102c04e 0x102c051 0x102c052 0x102c055 0x102c057 0x102c05b 0x102c05c 0x102c05f 0x102c061 0x102c064 0x102c065 0x1052481 0x105248b 0x1052482 0x1052486 0x1052487 0x105248a复制
大致的访问路径如下:
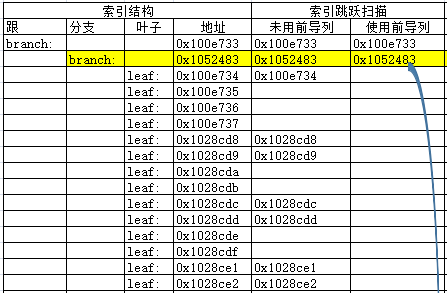
1.首先访问根节点:
2.访问第一个分支节点:
3.访问该分支节点下的第一个叶子块(为了遍历可能存在的所有唯一值);
4.根据该分支节点获得的叶子块(索引条目)最小值情况,确定需要访问哪些叶子块并在叶子块间跳跃扫描;
5.访问该分支节点下的最后一个叶子块(为了遍历可能存在的所有唯一值);
6.访问第二个分支节点并继续完成上述2-5步骤的循环。
为了弄清楚为何从0x1052483分支下的0x100e734叶子块开始扫描,需要首先获取根块、分支块的内容。获取数据块内容采用如下方法:
1.使用DBMS_UTILITY包获得数据块的文件号、块号:
--根块 select DBMS_UTILITY.DATA_BLOCK_ADDRESS_FILE(to_number('100e733','xxxxxxxx')) FILE#, DBMS_UTILITY.DATA_BLOCK_ADDRESS_BLOCK(to_number('100e733','xxxxxxxx')) BLOCK# from dual; --第一个分支块: select DBMS_UTILITY.DATA_BLOCK_ADDRESS_FILE(to_number('1052483','xxxxxxxx')) FILE#, DBMS_UTILITY.DATA_BLOCK_ADDRESS_BLOCK(to_number('1052483','xxxxxxxx')) BLOCK# from dual;复制
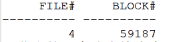

2.dump数据库内容:
alter system dump datafile 4 block 59187; alter system dump datafile 4 block 337027;复制
3.获取TRACE文件:
DUMP出的数据块内容如下:
根块:
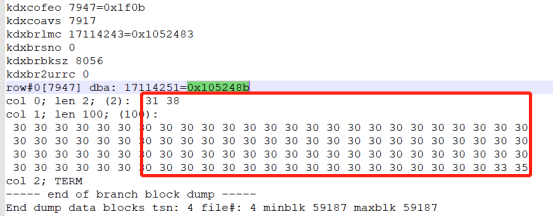
通过根块可知,lmc指向的第一个分支块,最小值没有记录。第二个分支块最小值为C1=‘18’,C2=LPAD(035,100,0)。条件列为 C2=LPAD(160,100,0)。针对C1列并没有做任何过滤,因此所有的分支块都有可能出现满足的C2条件,对所有的分支块都需要进行遍历。
第一个分支块内容:

通过第一个分支块可知,
lmc指向第一个叶子块,其最小值没有记录。该叶子块是必须要访问的。
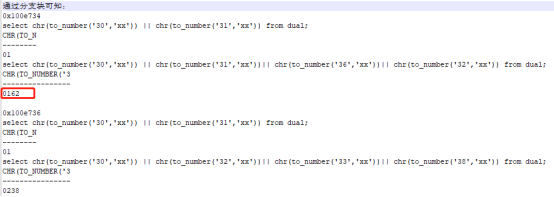
通过分支块可知,第二个叶子块0x100e735最小值为C1=‘01’,C2=LPAD(162,100,0)。其第三个0x100e736叶子块仍为C1=‘01’,且C2的最小值为LPAD(238,100,0)的情况,因此在C1='01’的情况下,已经可以提前预知叶子块0x100e736中不可能再出现满足C1=‘01’,C2=LPAD(160,100,0)的记录。之后第四个叶子块0x100e737最小值为C1=‘01’,C2=LPAD(360,100,0)。可以确定的是0x100e736是无需访问可以跳过的叶子块。
因为索引是有序的,首先会按照C1列排序,相同的C1列值按照C2列进行排序。对当前看到的三个叶子块最小值均为C1=‘10’,不同之处在于对C2列升序排序。
之后的叶子块同理,直到看到第0x1028cd9叶子块,其C1列已经变为了’02’,由于列是字符型,数据库无法确定在’01’和’02’之间,是否还存在’010’、‘011’、'0111’等数据,甚至也有可能是’02’的,因此当发现新的C1列出现时,数据库还需要再访问前一个数据块,以确认是否还有满足上述条件的记录。
最后一个叶子块也是同理,通过分支节点仅能获得索引条目的最小值,后续是否有更大的C1列值无法得知,还需要访问。
更详细的索引访问方法,请参考《索引访问方法》相关书籍资料或优化组内技术分享《第24期_20200219_赵勇_索引块结构及索引访问方法初探二》。本文不再详细说明。

…中间省略部分。
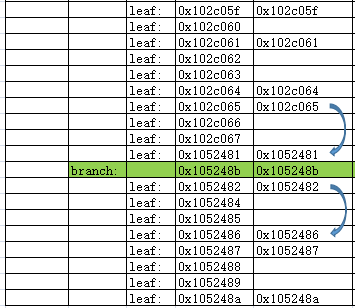
用EXCEL形象的展示,刨去根节点的访问,就是从对应分支节点下的第一个叶子块开始,采用跳跃的方式,直到访问完该节点下的最后一个叶子块。继续访问下一个分支并循环上述步骤。
同时,基于C1列唯一值变化后,就需要访问前一个数据块的原则,当前导列的唯一值数量越多,越有可能需要访问更多变化的C1列及其前一个数据块的情况。因此也是索引跳跃扫描唯一值越多效率越低的原因。
第三章 索引跳跃扫描的其他方式
除了上一章节展示的查询条件未包含索引前导列,优化器可能采用索引跳跃扫描之外。还有一种情况:
查询条件使用了复合索引的前导列和其他列,但是对前导列采用了范围查询,对其他列做等值查询。
实验脚本如下:
SELECT COUNT(*) FROM TEST_SKIPSCAN T WHERE C1 >= '10' AND C2 = LPAD(160, 100, 0);复制
执行计划如下:
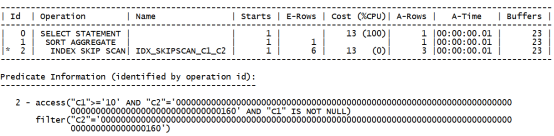
可以看到,优化器仍然使用了索引跳跃扫描,这与我们之前的认知存在差异。
分析跳跃扫描的执行路径。
3.1获取跳跃扫描的数据块
上述索引跳跃扫描,根据10200事件,访问的数据块情况如下:
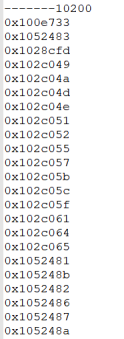
大致的访问路径如下:
1.首先访问根节点:
2.访问可能出现满足条件数据的第一个分支节点:
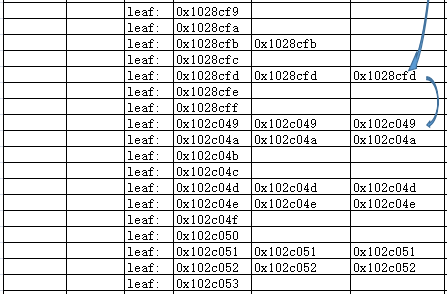
3.访问该节点下的0x1028cfd叶子块;
4.根据该分支节点获得的叶子块(索引条目)最小值情况,确定需要访问哪些叶子块并在叶子块间跳跃扫描;
5.访问该分支下的最后一个叶子块(为了访问所有满足C1条件的数据)。
6.访问第二个分支节点并继续完成上述2-5步骤的循环。
可以看到除了第二步之外,整体的访问方式与典型的索引跳跃扫描基本一致。第二步骤是从中间的0x1028cfd叶子块开始扫描。
3.2分析叶子块内容:
为了弄清楚为何从0x1052483分支下的0x1028cfd叶子块开始扫描,需要首先获取根块、分支块的内容。获取数据块内容方法同上:
DUMP出的数据块内容如下:
根块:

通过根块可知,除了lmc指向的第一个分支块外,第二个分支块最小值为C1=‘18’,C2=LPAD(035,100,0)。条件列为C1>=10 and C2=LPAD(160,100,0)。除了第二个分支块已经确定存在满足C1>=‘18’ 的数据,第一个分支块也是有可能存在C1>=‘18’ 的数据。还需要访问第一个分支块。
第一个分支块内容:
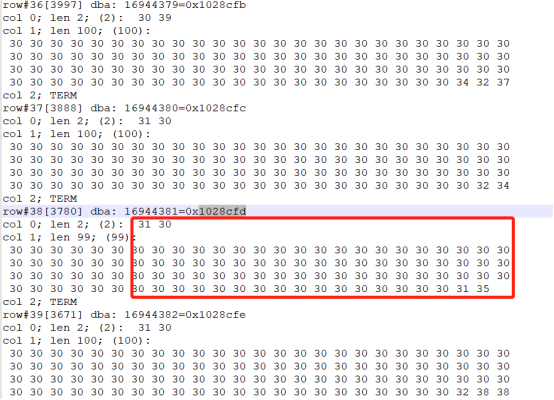
通过第一个分支块可知,
叶子块0x1028cfd的最小值是C1=‘10’、C2=LPAD(150,100,0)。
叶子块0x1028cfe的最小值是C1=‘10’、C2=LPAD(288,100,0)。
通过相应的最小值可以确定,在叶子块0x1028cfd和0x1028cfe之间,存储的最小值都是C1='10’的数据,不同之处在于C2在LPAD(150,100,0)和LPAD(288,100,0)。而我们要查询的列就是C1>=‘10’,C2=LPAD(160,100,0)。那如果存在C1=‘10’,C2=LPAD(160,50,0)的数据,必定存在于0x1028cfd块中。
继续查看叶子节点对应的0x1028cfd索引块信息:
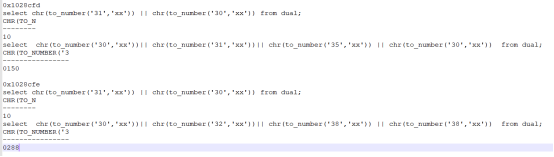
ROW0:
select chr(to_number('31','xx')) || chr(to_number('30','xx')) from dual; select chr(to_number('30','xx')) || chr(to_number('31','xx'))|| chr(to_number('35','xx'))|| chr(to_number('30','xx')) from dual;复制
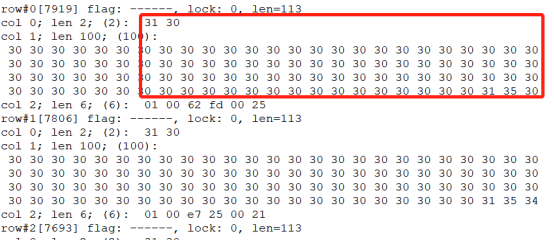
看到叶子节点中的第一个条目确实与该分支节点记录的信息完全一致。
因此,数据库根据根节点,定位到需要访问的第一个分支节点,继续定位到0x1028cfd叶子块,并开始查询。之后的扫描方式与典型的索引跳扫一致。
…中间省略
…中间省略
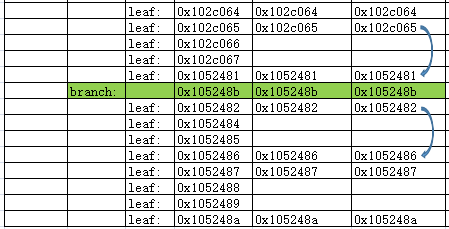
用EXCEL形象的展示,就是从定位到的满足前导列条件的分支节点,并根据分支节点定位到的满足前导列条件并可能出现满足C2列的叶子块开始,采用跳跃的方式,直到访问完该节点的最后一个叶子块。再继续循环上述从分支开始到叶子间的跳跃扫描。
我们可以说,存在前导列查询的索引跳扫,其访问方式与传统理解上的索引跳扫是基本一致的。只是会根据查询的索引前导列条件,确定跳跃扫描的起始点(对应分支、对应分支下的叶子),进而开始后续的跳跃扫描。其访问的效率会比传统的跳跃扫描更高(访问的叶子块少了)。从本例中的逻辑读由41降低为23也可以印证。
第四章 索引跳跃扫描转换为索引范围扫描
针对上一章节的索引跳跃扫描,是否能让该SQL采用索引范围扫描查询呢?
答案是肯定的,通过以下HINT实现:
SELECT /*+ OUTLINE_LEAF(@"SEL$1") index_rs_asc(t IDX_SKIPSCAN_C1_C2) */ COUNT(*) FROM TEST_SKIPSCAN T WHERE C1 >= '10' AND C2 = LPAD(160, 100, 0);复制
执行计划如下:
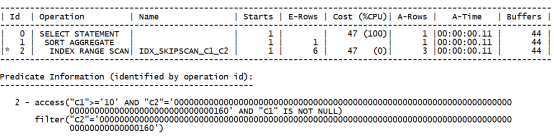
可以看到系统成功的使用了索引范围扫描,但其COST由13升到了47、逻辑读由23增加到44。甚至超过了不加前导列的跳跃扫描。正是此原因,优化器没有使用范围扫描。
根据优化的经验,等值查询在前、范围查询在后,这样的索引使用时是会采用高效的索引范围扫描进行的。而上述提及的情况恰好是范围查询在前、等值查询在后。这种情况根据经验,即使是采用索引范围扫描,也是比较低效的。
下面进行详细分析:
4.1获取范围扫描的数据块
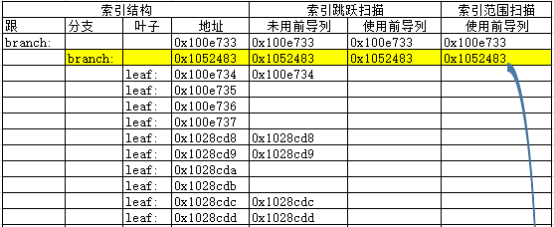
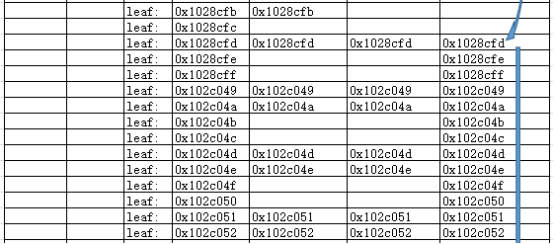
上述索引范围扫描,访问的数据块情况如下:
0x100e733 0x1052483 0x1028cfd 0x1028cfe 0x1028cff 0x102c049 0x102c04a 0x102c04b 0x102c04c 0x102c04d 0x102c04e 0x102c04f 0x102c050 0x102c051 0x102c052 0x102c053 0x102c054 0x102c055 0x102c056 ... 0x102c065 0x102c066 0x102c067 0x1052481 0x105248b 0x1052482 0x1052484 0x1052485 0x1052486 0x1052487 0x1052488 0x1052489 0x105248a复制
大致的访问路径如下:
1.首先访问根节点:
2.访问可能出现满足条件数据的第一个分支节点:
3.访问该节点下的0x1028cfd叶子块;
4.顺序扫描该节点后的所有的叶子块。
5.由于C1列是大于条件,无上边界,需要直至扫描到索引的最后一个叶子块为止(不再需要访问后续的分支节点)。
可以看到与上一章节跳跃扫描的区别在于,顺序访问所有的叶子节点。这也是为什么逻辑读及COST值都会比跳跃扫描更高的原因。
…中间省略
…中间省略
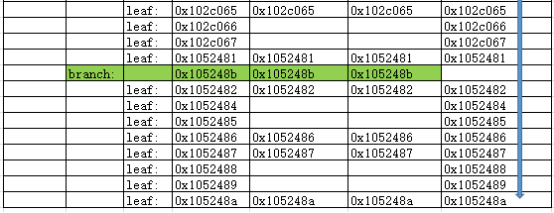
用EXCEL形象的展示,就是从定位到的满足前导列条件并可能出现满足C2列的叶子块开始,采用顺序扫描的方式,直到访问完最后一个叶子块。
4.2去掉C2列的范围扫描
将C2列去掉,是我们比较常见的范围扫描案例。实验脚本如下:
SELECT /*+ index_rs_asc(t IDX_SKIPSCAN_C1_C2) */ count(*) FROM TEST_SKIPSCAN T WHERE C1 >= '10';复制
执行计划如下:

可以看到,比上一小节的逻辑读还多了2。如何得来的?
根据10200,访问的数据块情况如下:
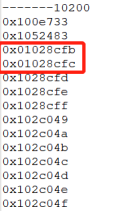
与包含C2列的区别在于,多了访问0x01028cfb和0x01028cfc数据块的2次逻辑读。为何要多访问这两个数据块呢?
仍然需要查看分支节点内容:
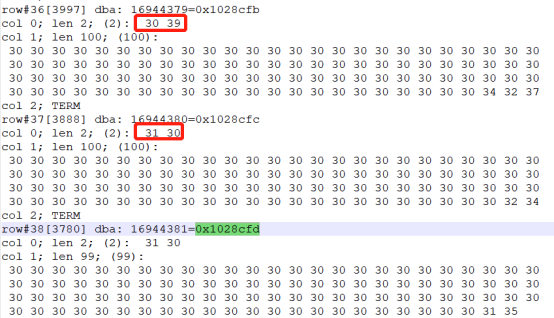
其中:
0x1028cfc叶子块的最小值是C1=‘10’。
0x1028cfb叶子块的最小值是C1=‘09’。
由于分支节点记录的只是叶子块的最小值,已经可以确定在0x1028cfc叶子块的数据满足C1>='10’的条件。SQL的条件是C1>=‘10’。去掉了C2=LPAD(160,50,0)条件。根据分支块中记录的0x1028cfc数据块最小值,无法确定是否在其前一个块中还有满足条件的数据。因此还需要访问一次0x1028cfb数据块,哪怕该块中没有相应的数据,这一个逻辑读的访问也是必须的。
第五章 总结
根据上述章节的分析测试,相应的问题已经可以明确解答:
1.索引跳跃扫描,不一定只存在于不包含索引前导列的查询中,还有可能出现在使用了索引前导列的查询中;
2.索引跳跃扫描,不一定比索引范围扫描效率更低。
索引跳跃扫描需要在叶子节点间跳跃进行,但其也要扫描相应的分支节点;
索引范围扫描只需要访问一次根/分支节点并定位到相应的叶子,之后就可以顺序扫描叶子节点。但在相同扫描路径下,其访问的叶子节点数量一般会≥跳跃扫描。
因此究竟哪种访问方式更高效,还要看跳跃扫描的唯一值数量,唯一值数量越多,跳跃扫描越趋近于要访问同范围的所有叶子节点,除此之外还要访问相应的分支节点。因此才有传统上的跳跃扫描效率一般比较低效的说法。
