




MYSQL索引(上)
众所周知, MYSQL支持许多类型索引,索引使用的正确与否,直接关系到我们的执行效率,一条慢SQL可能拖垮整个系统, innodb索引通常大体可以聚簇索引(一级索引)和非聚簇索引(二级索引), 非聚簇索引中又有唯一索引和普通索引以及不需要人工干预的自适应hash索引,innodb索引通常是以B+树存储数据。
聚簇索引
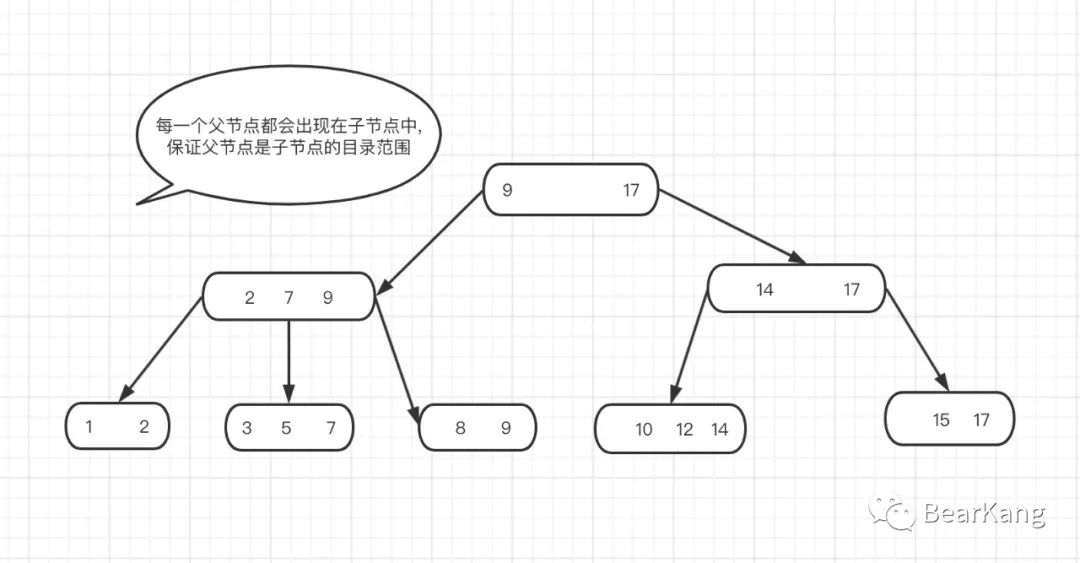
索引组织表都会有一个聚簇索引来组织表数据的顺序,常用的主键索引就是聚簇索引,如果表没有主键,MYSQL会默认创建一个主键来保证索引表有序,聚簇索引的非叶子节点存储索引数据范围(每个节点的父元素都出现在子元素中), 叶子节点储存索引和整行数据(元数据)。
非聚簇索引
非聚簇索引的大体结构和聚簇索引一致,只是叶子节点存储了只有索引列和聚簇索引通常是id列,特别情况下,联合索引中包含联合主键的部分列时, 只会额外存没有的主键列, 例如表t有(a, b, c)列, 主键列(a, b),创建联合索引(c,a)时,索引除了存(c,a)外只需要存主键缺少的部分b即可而不是(a,b)。
为了说明聚簇索引和非聚簇索引的区别,我在一个有200万数据行的user表列id,name,supply_spply_id,address,is_deleted,其中pk(id),index(name)做如下查询。



从两个执行计划可以看出,两个查询都走了索引扫描且扫描行数都是一行,但是从慢查询日志中可以看出使用name索引明显慢于使用id索引,原因就是因为name索引是二级索引,而我们查询字段是所有字段, 使用id索引时定位到数据行时,索引包含完整的行数据,直接返回,而通过name索引定位到叶子节点时, 节点仅仅只有name和id字段,因此需要根据id再次根据id索引去回表查询整行数据,回表恰恰是一个成本比较高的操作,假如我们不需要回表,设想只需要查询id,name,那么通过name索引定位到叶子节点,可以直接返回id和name信息,就不需要再次回表,这样效率也会很高。
总结
MYSQL使用B+树组织数据, 而且非叶子节点只存索引目录, 叶子节点才会存数据, 索引的根缓存在内存中, 假如一颗高为4的B+树,正确使用索引的情况下,最多只需要三次磁盘io即可定位到叶子节点,因此查询中要正确使用索引, 尽量避免大范围回表。
