




 点击蓝色字关注“SQL数据库运维”,回复“SQL”获取2TB学习资源!
点击蓝色字关注“SQL数据库运维”,回复“SQL”获取2TB学习资源!
偶尔处理SQL数据时,常常会发现数据表内存在重复数据的情况,今天就简单归纳整理下关于Oracle数据库去除重复数据常用的方法,仅供大家参考学习!
首先,准备并创建测试数据(测试环境数据库版本:Oracle 11g,工具:PL/SQL Developer)
--创建测试表create table TBQCCE_0313(col_1 varchar2(10), col_2 varchar2(10), col_3 varchar2(10),col_4 varchar2(10));--插入测试数据insert into TBQCCE_0313select 1,2,3,4 from dualunion allselect 1,2,3,4 from dualunion allselect 5,2,3,4 from dualunion allselect 10,20,30,40 from dual ;commit;--查询测试数据select * from TBQCCE_0313;复制
新建数据表查询数据结果如下:
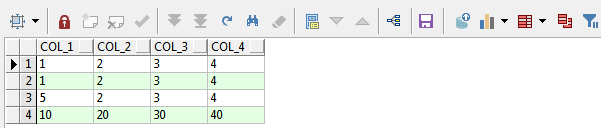
针对不同情况的数据去重方法测试实践
★针对指定列,查询出去重后的结果集(distinct或row_number())如下:
--全部查询的列去重select distinct * from TBQCCE_0313;复制
去重后结果:

此方法局限性比较大,因为它只能对全部查询的列进行去重。
如果需要对col_2,col_3,col_4去重,那我的结果集中就只能有col_2,col_3,col_4列,而不能有col_1列,不过它也是最简单易懂的写法。
--对数据结果集col_2,col_3,col_4去重(distinct)select distinct col_2,col_3,col_4 from TBQCCE_0313;复制
去重后结果:

ROW_NUMBER() OVER(PARTITION BY 需要去重字段 ORDER BY 字段 DESC) 为指定的去重字段,标上行号,如果有重复的,选中行号为1的就可以。(写法上要麻烦不少,但是有更大的灵活性。)
--对数据结果集col_2,col_3,col_4去重(row_number())select t1.col_2, t1.col_3,t1.col_4from (select t1.*,row_number() over(partition by t1.col_2, t1.col_3,t1.col_4 order by col_1 ASC) rnfrom TBQCCE_0313 t1) t1where t1.rn = 1;复制
去重后结果:

★针对指定列,查出所有重复的行(count having或count over)如下:
使用count having查询出指定列的所有重复的行
--count having查询出指定列的所有重复的行select t.col_2, t.col_3,t.col_4from TBQCCE_0313 twhere (t.col_2, t.col_3,t.col_4) in (select t1.col_2, t1.col_3,t1.col_4from TBQCCE_0313 t1group by t1.col_2, t1.col_3,t1.col_4having count(1) > 1)复制
查询结果:
 缺点:要查两次数据表,效率会比较低,不推荐使用。
缺点:要查两次数据表,效率会比较低,不推荐使用。
使用count over查询出指定列的所有重复的行
--count over查询出指定列的所有重复的行select t1.col_2, t1.col_3,t1.col_4from (select t1.*,count(1) over(partition by t1.col_2, t1.col_3,t1.col_4) rnfrom TBQCCE_0313 t1) t1where t1.rn > 1;复制
查询结果:
 只需要查一次表,推荐。
只需要查一次表,推荐。
★删除重复数据并保留一条,如下
分析函数法
拥有分析函数一贯的灵活性高的特点。可以为所欲为的分组,并通过改变order by从句来达到像“保留最大id”这样的要求。
--删除col_1,col_2,col_3,col_4重复的行数据delete from TBQCCE_0313 twhere t.rowid in (select ridfrom (select t1.rowid rid,row_number() over(partition by t1.col_1,t1.col_2, t1.col_3,t1.col_4 order by 1) rnfrom TBQCCE_0313 t1) t1where t1.rn > 1);复制
删除后数据查询结果:

group by
虽然牺牲了一部分灵活性,但是换来了更高的效率。
--删除col_2,col_3,col_4重复的行数据delete from TBQCCE_0313 twhere t.rowid not in(select max(rowid) from TBQCCE_0313 t1 group by t1.col_2, t1.col_3, t1.col_4);复制
删除后数据查询结果:


点击关注“SQL数据库运维”,后台或浏览至公众号文章底部点击“发消息”回复关键字:进群,带你进入高手如云的技术交流群。后台回复关键字:SQL,获取学习资料。
动动小手点击加关注呦☟☟☟
文章转载自SQL数据库运维,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【专家有话说第五期】在不同年龄段,DBA应该怎样规划自己的职业发展?
墨天轮编辑部
1397次阅读
2025-03-13 11:40:53
Oracle RAC ASM 磁盘组满了,无法扩容怎么在线处理?
Lucifer三思而后行
850次阅读
2025-03-17 11:33:53
RAC 19C 删除+新增节点
gh
528次阅读
2025-03-14 15:44:18
2月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
487次阅读
2025-03-13 14:38:19
Oracle 如何修改 db_unique_name?强迫症福音!
Lucifer三思而后行
386次阅读
2025-03-12 21:27:56
Oracle DataGuard高可用性解决方案详解
孙莹
345次阅读
2025-03-26 23:27:33
金仓数据库26套!宁波市司法局信息系统适配改造(一期)采购项目
天下观查
337次阅读
2025-03-21 10:33:59
Oracle数据库调整内存应该注意的几个问题
听见风的声音
330次阅读
2025-03-18 09:43:11
国产化+性能王炸!这套国产方案让 3.5T 数据 5 小时“无感搬家”
YMatrix
318次阅读
2025-03-13 09:51:26
大连农商40万,采购Greenplum数据库原厂订阅服务
天下观查
289次阅读
2025-03-13 09:52:29
