准备环境
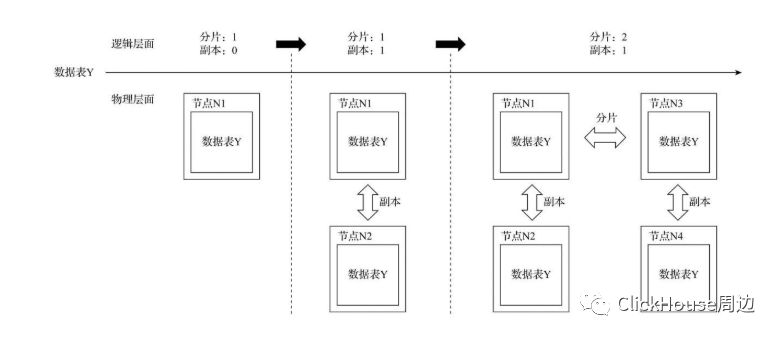
集群架构是2分片,1副本
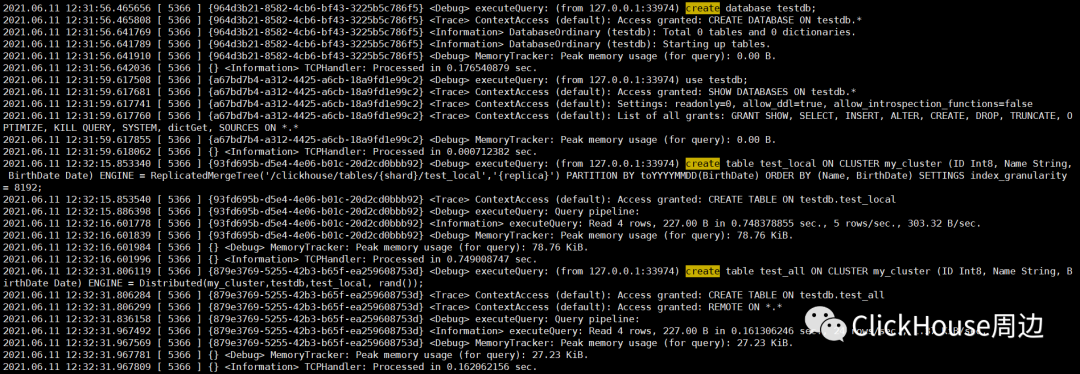
create database testdb;use testdb;
create table test_local ON CLUSTER my_cluster (ID Int8, Name String, BirthDate Date) \ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_local','{replica}') PARTITION BY toYYYYMMDD(BirthDate) ORDER BY (Name, BirthDate) SETTINGS index_granularity = 8192;ReplicatedMergeTree的定义方式 ENGINE =ReplicatedMergeTree('zk_path','replica_name')ClickHouse提供的配置模板
<default_replica_path>/clickhouse/tables/{shard}/{table}</default_replica_path><default_replica_name>{replica}</default_replica_name>
对于zk_path,同一张数据表的同一个分片的不同副本,定义相同的路径;而对于replica_name,同一张数据表的同一个分片的不同副本,定义不同的名称。 详情查看 Creating Replicated Tables
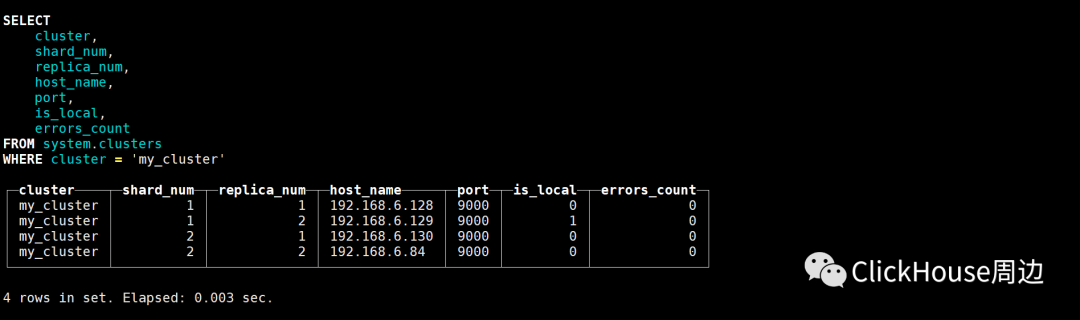
https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/ 2.2 分布表
create table test_all ON CLUSTER my_cluster (ID Int8, Name String, BirthDate Date) \ENGINE = Distributed(my_cluster,testdb,test_local, rand());
3.插入测试数据
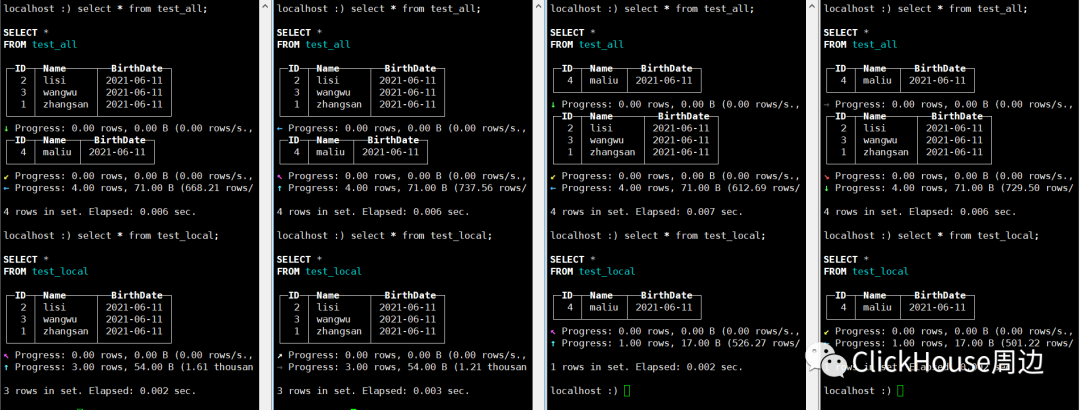
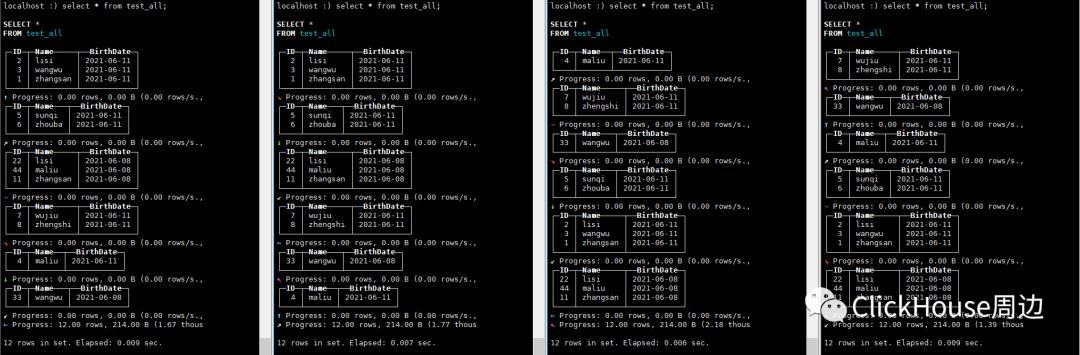
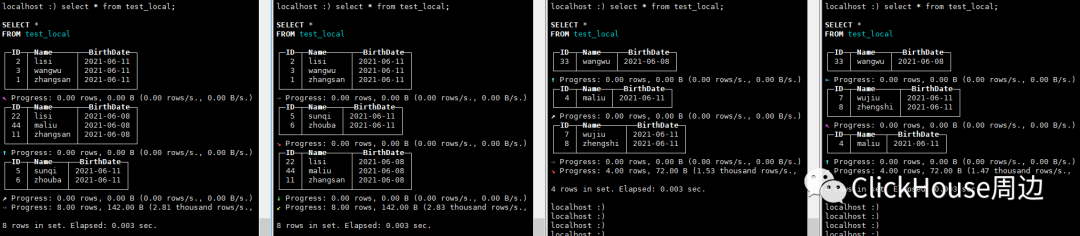
insert into test_all values(1,'zhangsan',now()),(2,'lisi',now()),(3,'wangwu',now()),(4,'maliu',now());
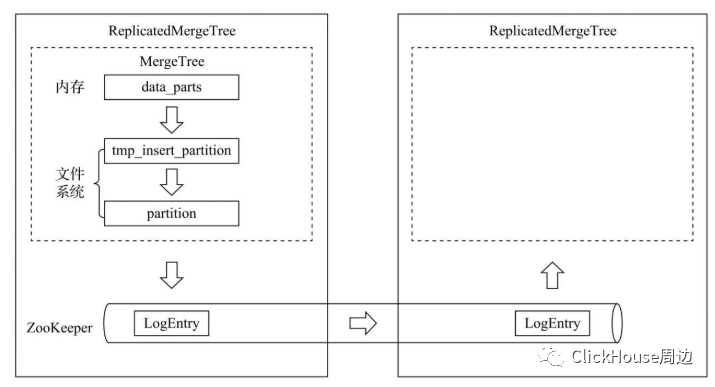
来自《ClickHouse原理解析与应用实践》一书 在MergeTree中,一个数据分区由开始创建到全部完成,会历经两类存储区域。 (1)内存:数据首先会被写入内存缓冲区。 (2)本地磁盘:数据接着会被写入tmp临时目录分区,待全部完成后再将临时目录重命名为正式分区,然后向/block节点写入该数据分区的block_id(用于去重)。ReplicatedMergeTree在上述基础之上增加了ZooKeeper的部分,它会进一步在ZooKeeper内创建一系列的监听节点,并以此实现多个实例之间的通信。
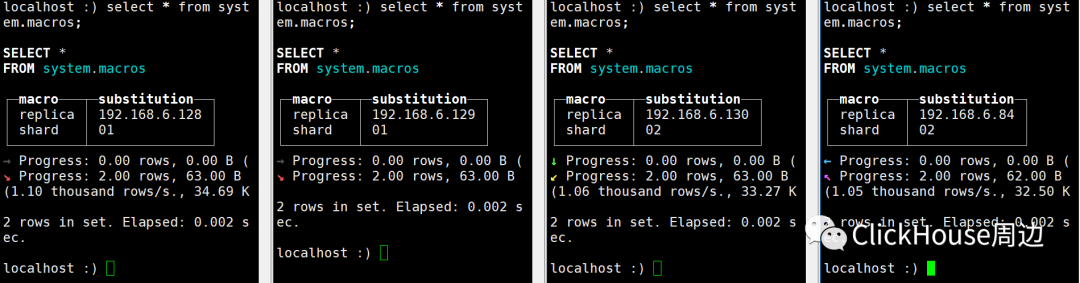
shard:/01/ 192.168.6.129 选择拉取远端副本:192.168.6.128
其中可以看到shard:/01/ 的192.168.6.129 选择拉取远端副本:192.168.6.128 的时候第一次下载请求失败。ClickHouse默认配置可以共请求5次。 shard:/02/ 192.168.6.84 选择拉取远端副本:192.168.6.130
追踪日志信息可以看出,基于DataPartsExchange的响应后,先将数据写入了tmp_fetch_20210611_0_0_0,待全部数据接收完成之后,重命名该目录:Renaming temporary part tmp_fetch_20210611_0_0_0 to 20210611_0_0_0。 4.查询
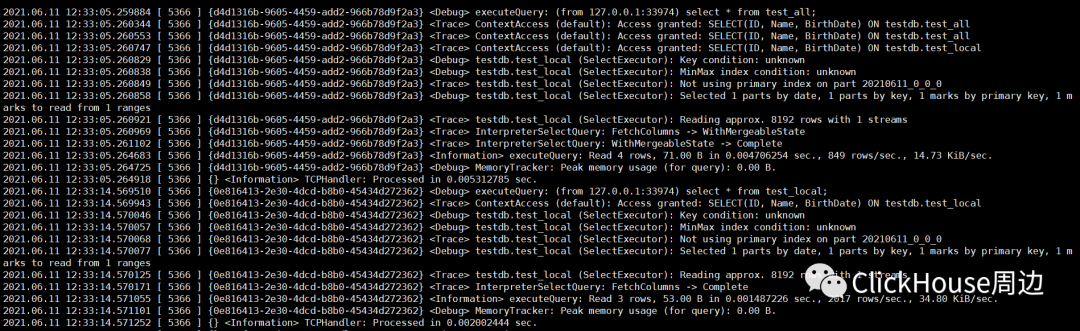
建表语句中分区键是:BirthDate ,主键是 Name, BirthDate 根据追踪的信息,解读SQL执行计划: 该SQL没有使用主键索引: Key condition: unknown该SQL没有使用分区索引:
MinMax index condition: unknown该SQL查询,共扫描了所有的1个分区目录,共计1个MarkRange:
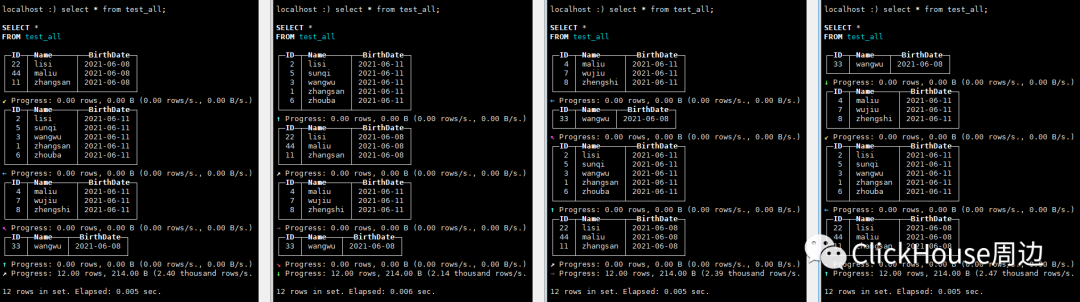
Selected 1 parts by date, 1 parts by key, 1 marks to read from 1 ranges5.合并 insert into test_all values(11,'zhangsan',now()-259200),(22,'lisi',now()-259200),(33,'wangwu',now()-259200),(44,'maliu',now()-259200);insert into test_all values(5,'sunqi',now()),(6,'zhouba',now()),(7,'wujiu',now()),(8,'zhengshi',now());
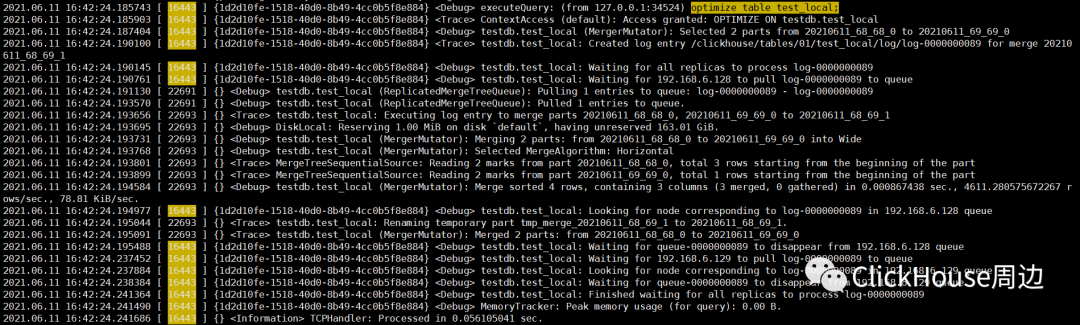
optimize table test_local;
根据追踪的信息,操作类型为Merge合并,需要合并的分区目录是20210611_68_68_0 和 20210611_69_69_0。同时,主副本还锁住执行线程,对日志的接收情况进行监听:
Waiting for 192.168.6.128 to pull log-0000000089 to queue各个副本实例将分别监听/log/log-0000000089日志的推送,它们也会分别拉取日志到本地,并推送到各自的/queue任务队列:
Pulling 1 entries to queue: log-0000000089 - log-0000000089各个副本基于队列分别在本地执行MERGE
Executing log entry to merge parts 20210611_68_68_0, 20210611_69_69_0 to 20210611_68_69_1
Merging 2 parts: from 20210611_68_68_0 to 20210611_69_69_0 into Wide合并完成查询:
近期文章推荐: ClickHouse 之 FORMAT 应用 ClickHouse数据目录完全解析 Distributed表引擎Insert和Select流程 更多精彩内容欢迎关注微信公众号