




在Redis中,哈希表不但是我们可以使用的几种基础数据结构之一,同时还是整个Redis数据存储结构的核心。究其根本,Redis是一种基于Key-Value的内存数据库,所有的用户数据,Redis在底层都是使用哈希表进行保存的。可以说,了解Redis中哈希表的实现方式,是了解Redis存储的一个关键。
Redis哈希表概述
基于链表的哈希表是实现哈希表的一个主流方式,除了Redis中的哈希表实现,*g++*中的unordered_map
也是使用基于链表的哈希表实现的, 但是两者之间还是有一些细微的差别,这在后续会进行介绍。
在src/dict.h头文件之中,首先定义了哈希表中的链表基本节点数据结构。
typedef struct dictEntry{ void *key; //用于存储Key union { void *val; //可以用来保存一段具体的内存二进制数据 uint64_t u64; //可以用来存储一个64位无符号整形数据 int64_t s64; //可以用来存储一个64位有符号整形数据 double d; //可以用来存储一个双精度浮点数据 } v; //使用union来保存value数据 struct dictEntry *next; //由于使用基于拉链的哈希表实现,next用于指向桶中下一个key-value对。} dictEntry;复制
在这个key-value的数据结构之中,value是使用一个联合体union
来表示的,通过这个联合体,Redis既可以使用一个64位整数作为value, 也可以使用一个双精度浮点数作为value,同时还可以使用一个任何一段内存作为value,而value之中也保存这段内存的指针。
基于这个哈希表的基本节点数据结构,Redis定义了自己的哈希表数据结构:
typedef struct dictht { dictEntry **table; //table是一个数组结构,其中的每个元素都是一个dictEntry指针 unsigned long size; //table中桶的数量 unsigned long sizemask; //table中桶数量的掩码 unsigned long used; //该哈希表之中,已经保存的*key-value*的数量} dictht;复制
根据dictht
给出的定义,我们可以知道这个哈希表在内存中的结构可以如下图所示:

在dictht
中这个sizemask
数据主要视为实现快速取余的用途,这个掩码被设定为size-1
的大小。这里体现了Redis哈希表与 g++ 中unordered_map
的一个不同之处,g++ 总是会选取一个素数作为桶的数量, 而在Redis之中,桶的数量一定是2的n次方个,那么当dictht.size
为16的时候,dictht.sizemask
对应而二进制形式变为1111
, 这样对于一个给定的哈希值h
使用h & sizemask
可以获得哈希值对size
的取余操作结果。根据余数,可以决定这个key-value
数据落在哪个哈希表的哪个桶中。
同时,src/dict.h头文件中,定义了一个结构体,存储基础哈希操作的函数指针,这里体现了Redis代码实现中的函数式编程的思想, 用户可以对指定的函数指针赋值自己定义的函数接口。
typedef struct dictType { uint64_t (*hashFunction)(const void *key); //通过给定key,计算对应的哈希值 void *(*keyDup)(void *privdata, const void *key); //用于复制key的函数指针 void *(*valDup)(void *privdata, const void *obj); //用于复制value的函数指针 int (*keyCompare)(void *privdata, const void *key1, const void *key2); //两个key的比较函数 void (*keyDestructor)(void *privdata, void *key); //用于处理key的释放 void (*valDestructor)(void *privdata, void *obj); //用于处理val的释放} dictType;复制
Redis为不同的哈希表给出了不同的dictType
,例如在src/server.c文件中,
/* Db->dict, key是sds动态字符串, vals则是Redis对象类型 */dictType dbDictType = { dictSdsHash, /* hash function */ NULL, /* key dup */ NULL, /* val dup */ dictSdsKeyCompare, /* key compare */ dictSdsDestructor, /* key destructor */ dictObjectDestructor /* val destructor */};复制
Redis会使用上述这组dictType
来描述Redis数据库中的键空间,server.db[j].dict = dictCreate(&dbDictType,NULL);
。
基于dictht
以及dictType
这两个数据结构,Redis定义最终的哈希表数据结构dict
:
typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; //重哈希索引,如果没有在进行中的重哈希,那么这个rehashidx的值为-1 unsigned long iterators; /* number of iterators currently running */} dict;复制
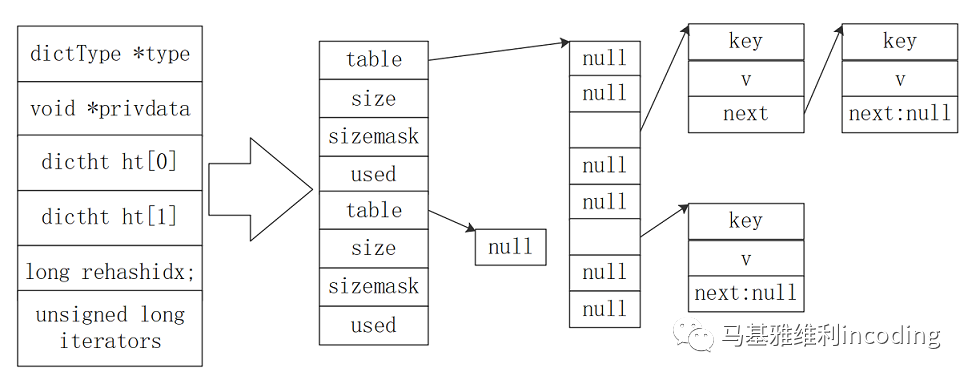
上面这张图,便是描述了Redis的哈希表在内存中的分布结构,我们可以注意到其中的一个特别设计之处, 也就是在dict
结构中会有两个底层的哈希表数据结构dict.ht[2]
, 这与*g++*中的unordered_map
的设计有着显著的不同,
class _Hashtable{ ... __bucket_type* _M_buckets; size_type _M_bucket_count; size_type _M_element_count; ...};template<class _Key, class _Tp, class _Hash = hash<_Key>, class _Pred = std::equal_to<_Key>, class _Alloc = std::allocator<std::pair<const _Key, _Tp> > >class unordered_map{ ... _Hashtable _M_h; ...};复制
从*g++*的unordered_map
源代码可以知道,它在内部只维护了一个底层哈希表数据结构。
为什么Redis的哈希表要有两个呢???
之所以Redis在dict
中使用两个hashtable,其主要用意是方便在进行ReHash操作时,进行数据转移。 Redis在执行重哈希操作时,不会一次性将所有的数据进行重哈希,而是采用一种增量的方式, 逐步地将数据转移到新的桶中。而这又是其与unordered_map
的不同之处,unordered_map
在进行重哈希的时候, 会一次性地将表中的所有元素移动到新的桶中,而不是增量进行的。究其原因,unordered_map
只是C++中存储数据的 手段之一,其有特定的应用场景,因此不需要增量地进行重哈希。而在Redis中,虽然官方给出了多种基础数据类型, 但是其在底层进行检索的时候,都是以哈希表进行存储的,同时Redis定义为是一种数据库,那么其在哈希表中所存储的数据 的量级要远远大于通用的C++程序,如果在哈希表中有大量的key-value数据的话,对所有数据进行重哈希操作, 会导致系统阻塞在重哈希操作中无法退出,而Redis本身对于核心数据的操作又是单线程的模式, 这将导致Redis无法对外提供服务。为解决这个问题,Redis在dict
中给出了保存了两个哈希表,在进行重哈希操作时, Redis会将第二个哈希表进行扩容或者缩容,然后定期将第一个哈希表中的数据重哈希到第二个哈希表中。而这时,保存在第一个哈希表中没有来得及进行重哈希的数据,对于客户端用户来说,依然是可用的。当第一个哈希表中全部数据重哈希结束后,Redis会把数据从第二个哈希表中转移至第一个哈希表中,结束重哈希操作。

上图便是Redis在对哈希表执行重哈希操作过程中,其在内存中的分布情况。在进行重哈希的过程中dict.rehashidx
字段 标记了第一个哈希表中下一次需要被重哈希的桶的索引,当重哈希结束后,这个字段会被设置为-1
。
而字段dict.iterators
则是关联在这个哈希表上的安全迭代器的数量,关于安全迭代器的内容,会在后续进行介绍。
Redis哈希表的基础底层操作
在src/dict.h头文件之中,Redis定义了一组用于完成基本底层操作的宏:
| 宏定义 | 具体含义 |
|---|---|
#define dictFreeVal(d, entry) | 使用dict中 type的 valDestructor来释放 entry节点的 v.val |
#define dictSetVal(d, entry, _val_) | 为entry中的 v.val进行赋值 |
#define dictSetSignedIntegerVal(entry, _val_) | 为entry中的 v.u64进行赋值 |
#define dictSetUnsignedIntegerVal(entry, _val_) | 为entry中的 v.s64进行赋值 |
#define dictSetDoubleVal(entry, _val_) | 为entry中的 v.d进行赋值 |
#define dictFreeKey(d, entry) | 使用dict中 type的 valDestructor来释放 entry节点的 key |
#define dictSetKey(d, entry, _key_) | 为entry中的 key进行赋值 |
#define dictCompareKeys(d, key1, key2) | 对key1和 key2进行比较 |
#define dictHashKey(d, key) | 为key计算其对应的哈希值 |
#define dictSlots(d) | 获取dict中桶的个数,由两个哈希表中的 size数据的加和组成 |
#define dictSize(d) | 获取dict中存储元素的个数,由两个哈希表中 used数据的加和组成 |
#define dictIsRehashing(d) | 判断dict是否处于重哈希过程中 |
