




上回说到一条查询语句 SQL 是怎样在 MySQL 服务端执行的。整体来看分两部分,server 端负责验证、解析、优化 SQL,而真正执行 SQL 是在存储引擎层。我们说的 InnoDB 就是常用的存储引擎的一种,其实还有其他的存储引擎,例如:MyISAM、Memory、TokuDB 等。那么我们为什么在实际生产环境中使用 InnoDB 呢?原因也不复杂,因为 InnoDB 支持事务与行级锁,并发场景下有良好的性能。
事务
说起事务要从四个方面入手:
A(Atomicity)原子性:一组语句要么全部执行,要么全部不执行;
C(Consistency)一致性:事务开始前和结束后,数据库的完整性约束没有被破坏;
I(Isolation)隔离性:同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰;
D(Durability)持久性:事务完成后,事务对数据库的所有更新将被保存到数据库。
事务这么复杂,它到底是怎么实现的呢?
还记得上篇开篇说的那些日志文件吗,尤其是 redo log 与 undo log,这些日志就是 InnoDB 实现事务的关键所在。
我们知道 MySQL 的数据是存储在磁盘上的,而磁盘的读写速度非常慢,所以 InnoDB 存储引擎进行了优化,读写操作全都基于缓存,也就是 buffer pool。通常先检查 buffer pool 中是否存在需要的数据页,如果不存在则从磁盘读取数据到 buffer pool 中,然后在做相应处理。虽然使用缓存带来了性能提升,但随之带来的就是数据的不一致问题,而这又与事务的要求相违背。如此看来,事务最重要的目的其实是为了满足一致性。那么 InnoDB 是如何保证事务的呢?
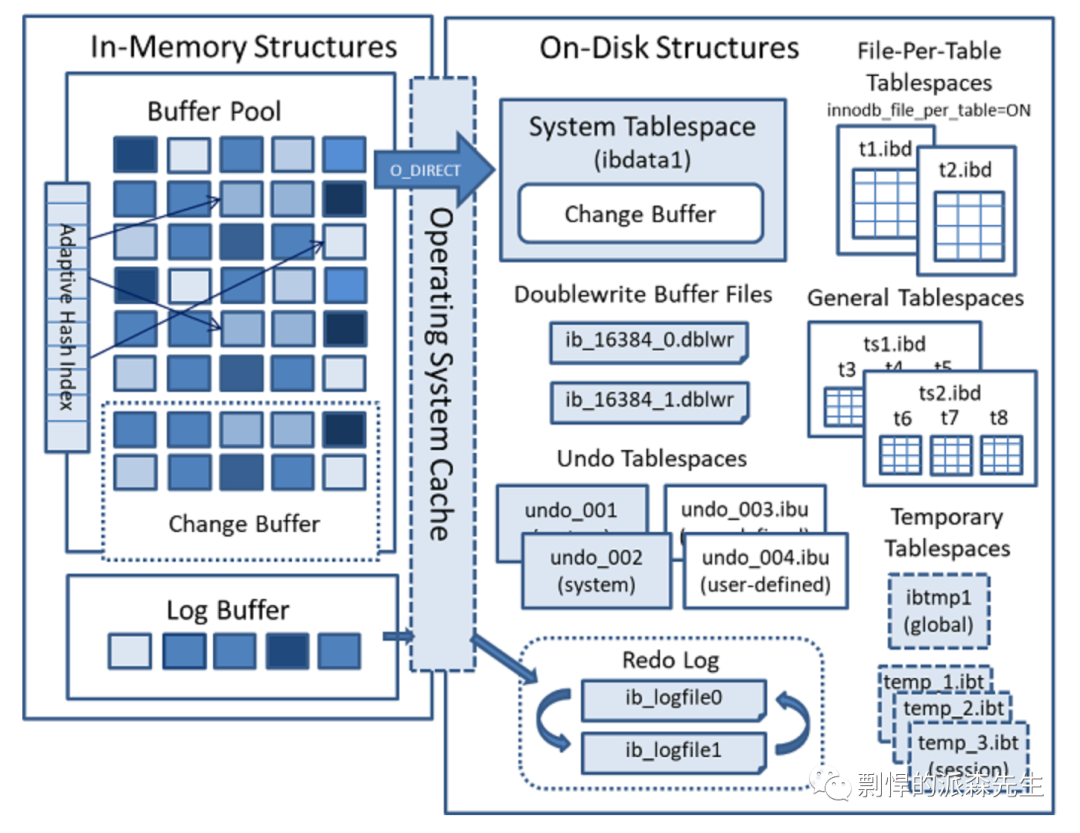
在 InnoDB 中,缓存刷盘的规则是基于 checkpoint 机制的,有多种情况可以触发 checkpoint。但不管怎样,checkpoint 触发后,都会将 buffer pool 中脏数据页和脏日志页都刷到磁盘。Redo log 机制用来保证日志文件的持久性,double write 机制用来数据文件的可靠性。
在 InnoDB 存储引擎内部,有两种 checkpoint,分别为:
Sharp checkpoint:发生在数据库关闭时,将所有的脏页都刷新回磁盘;
Fuzzy checkpoint:数据库在运行时使用,每次只刷新一部分脏页,而不是刷新所有的脏页回磁盘。
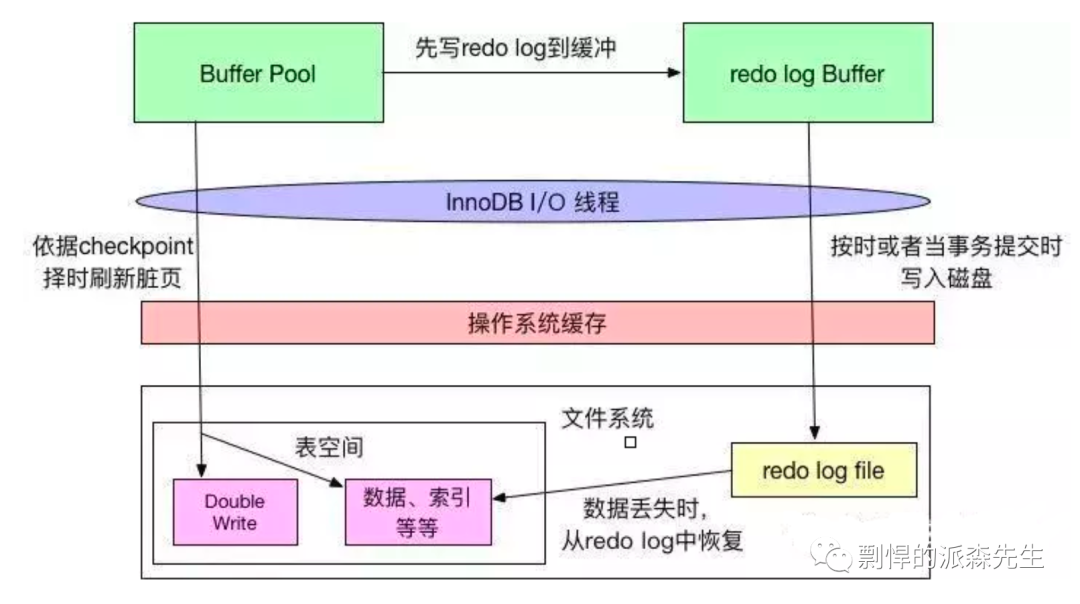
Redo log
Redo log 也就是重做日志,常见文件名为 ib_logfile0.log 与 ib_logfile1.log。通常这两个文件是固定大小的。Redo log 主要用来保证事务的持久性,以及故障恢复。
Redo log 由两部分组成:
内存中的重做日志缓冲(redo log buffer),易丢失,大小有限,默认事务提交会触发写入 redo log file;
重做日志文件(redo log file),持久的,基于 WAL 的预写日志,保证落盘的高性能与持久性;
主线程默认每秒刷新 redo log buffer 到 redo log file 中(同步 fsync 方式),但在事务提交时也可能刷新 buffer 到 file 中,这个由 innodb_flush_log_at_trx_commit 参数控制:
0 表示事务提交时不触发写磁盘,而是等待主线程每秒的刷新操作;
1 表示同步写磁盘,默认值;
2 表示异步写磁盘,即不能保证 commit 时一定会刷新重做日志缓冲到重做日志磁盘文件中。
由于 innodb_flush_log_at_trx_commit 默认值为 1,所以默认情况下,当事务 commit 时,必须先将该事务的所有日志从 buffer 中同步写入到 file 进行持久化,该事务的 commit 操作才算完成。
Redo log file 打开时没有使用 O_DIRECT 选项,因此数据会先写入文件系统缓存 page cache。为了确保重做日志写入磁盘,必须进行一次 fsync 操作,该操作的效率取决于磁盘的性能。O_DIRECT 标志位意味着任何读写操作都只在用户态地址空间和磁盘之间传送而不经过page cache。
Double write
当 buffer pool 中的数据页与磁盘中的数据不一致时产生脏页。把脏页数据更新到磁盘有如下触发时机:
MySQL 会有专门的后台线程,“抽空”将脏页刷新到磁盘;
Buffer pool 空间不足, 脏页将被淘汰从 buffer pool 中移除的时候;
Redo log file 写满的时候;
数据库正常关闭的时候。
InnoDB 采用 double write 的机制来保证数据页落盘的可靠性。Double write 由两部分组成,一部分是 double write buffer,有两块,每块大小为 1M;另一部分是物理磁盘上的共享表空间 ibdata 文件中连续的 128 个页,也是 2M。
在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是通过 memcpy 函数将脏页先复制到内存中的 double write buffer 区域,之后通过double write buffer 再分两次,每次 1MB 以 WAL 的方式顺序地写入共享表空间 ibdata 文件,然后马上调用 fsync 函数,同步磁盘,避免操作系统 page cache 带来的问题。在完成 double write 页的写入后,再将 double wirite buffer 中的页写入各个表空间文件中。
如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,InnoDB 存储引擎可以从共享表空间中的 double write 中找到该页的一个副本,将其复制到表空间文件中,然后再应用重做日志。
为什么要这样呢?这是因为一个数据页大小是 16K,而磁盘管理的最小的页是 4K,那么意味着在刷新一个数据页时,磁盘就要进行多次寻址然后再写入数据,而这个过程很漫长,大大增加了写入失败的可能性,而采用 double write 机制可以最大限度的保证可靠性。
Undo log
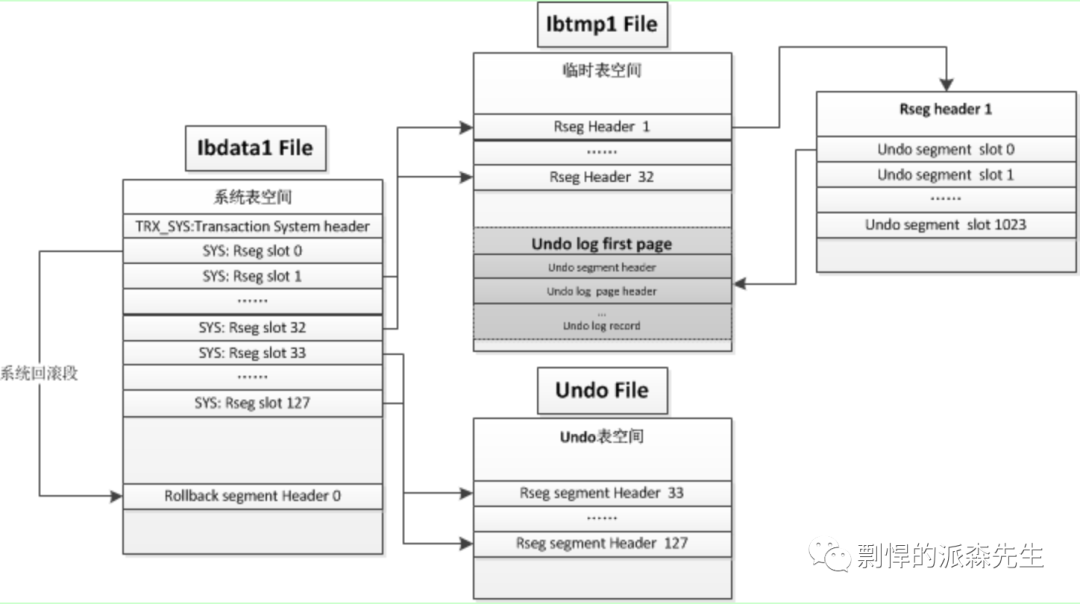
事务的原子性要求,如果事务失败,应该进行回滚。而 undo log 中记录了用于事务回滚所需要的数据。数据更新时不仅仅记录 redo log 这样的物理日志,也会记录 undo log 逻辑日志,可以认为是当前修改 SQL 的逆操作。
当执行 rollback 时,就可以从 undo log 中的逻辑记录读取到相应的内容并进行回滚。行记录版本控制也是通过 undo log 来实现的:当读取的某一行被其他事务锁定时,它可以从 undo log 中分析出该行记录以前的数据是什么,从而提供该行的历史版本数据,让用户实现非锁定一致性读取。
InnoDB 存储引擎对 undo log 的管理采用段的方式。Rollback segment 称为回滚段,每个回滚段中有 1024 个 undo log segment,每个 undo 操作记录占用一个 undo log segment。Undo log 默认存放在共享表空间中,也就是上文提到的 double writer 落盘的文件 ibdata。
根据行为的不同,undo log 分为两种:
insert undo log:insert 操作中产生的 undo log。 因为 insert 操作的记录只对事务本身可见,对于其它事务此记录是不可见的,所以 insert undo log 可以在事务提交后直接删除而不需要进行 purge 操作。
update undo log:update 或 delete 操作中产生的 undo log。 因为会对已经存在的记录产生影响,为了提供 MVCC 机制,因此 update undo log 不能在事务提交时就进行删除,而是将事务提交时放到入 history list 上,等待 purge 线程进行最后的删除操作。
隔离性
说起隔离性,不得不说隔离级别,以及为什么需要这些隔离级别,以及如何实现这些隔离级别。
简单说隔离级别解决的是可见性问题,当我们说隔离级别的时候,主要谈的是不同隔离级别下的读写问题。InnoDB 通过锁与 MVCC (Multi-Versioning Concurrent Control)实现四种隔离级别:
Read UnCommited
Read Commited:解决脏读
Repeatable Read:InnoDB(默认),解决脏读 、不可重复读,InnoDB 中也解决了幻读问题
Serializable:解决脏读、不可重复读和幻读
脏读 、不可重复读、幻读是个啥?
脏读:一个事务中访问到了另外一个事务未提交的数据;
不可重复读:一个事务读取多次,得到的记录内容不一致;
幻读:一个事务读取多次,得到的记录条数不一致。
RU 是没有隔离性的,Serializable 是无论读写都加锁。
RC vs. RR
RC
一致性读(Consistent reads):防脏读,但不可重复读,不加锁
锁定读(Locking reads):防脏读,但不可重复读,给索引上行锁
SELECT ... FOR SHARE/LOCK IN SHARE MODE
:共享锁SELECT ... FOR UPDATE
:排他锁
RR
一致性读:防脏读,防不可重复读,防幻读,不加锁
锁定读:防脏读,防不可重复读,防幻读
SELECT ... FOR SHARE/LOCK IN SHARE MODE
:共享锁SELECT ... FOR UPDATE
:排他锁使用唯一索引等值查询:给索引上行锁
范围查询:上 next-key locks
鉴于网上对于 RR 隔离级别是否能防止幻读存在很大分歧,特从官网摘抄原话。如有理解错误,请看官们指出。
原话:
The following list describes how MySQL supports the different transaction levels. The list goes from the most commonly used level to the least used.
REPEATABLE READThis is the default isolation level for
InnoDB
. Consistent reads within the same transaction read the snapshot established by the first read. This means that if you issue several plain (nonlocking)SELECT
statements within the same transaction, theseSELECT
statements are consistent also with respect to each other. See Section 15.7.2.3, “Consistent Nonlocking Reads”.For locking reads (
SELECT
withFOR UPDATE
orFOR SHARE
),UPDATE
, andDELETE
statements, locking depends on whether the statement uses a unique index with a unique search condition, or a range-type search condition.
For
UPDATE
orDELETE
statements,InnoDB
holds locks only for rows that it updates or deletes. Record locks for nonmatching rows are released after MySQL has evaluated theWHERE
condition. This greatly reduces the probability of deadlocks, but they can still happen.For
UPDATE
statements, if a row is already locked,InnoDB
performs a “semi-consistent” read, returning the latest committed version to MySQL so that MySQL can determine whether the row matches theWHERE
condition of theUPDATE
. If the row matches (must be updated), MySQL reads the row again and this timeInnoDB
either locks it or waits for a lock on it.For a unique index with a unique search condition,
InnoDB
locks only the index record found, not the gap before it.For other search conditions,
InnoDB
locks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into the gaps covered by the range. For information about gap locks and next-key locks, see Section 15.7.1, “InnoDB Locking”.
READ COMMITTEDEach consistent read, even within the same transaction, sets and reads its own fresh snapshot. For information about consistent reads, see Section 15.7.2.3, “Consistent Nonlocking Reads”.
For locking reads (
SELECT
withFOR UPDATE
orFOR SHARE
),UPDATE
statements, andDELETE
statements,InnoDB
locks only index records, not the gaps before them, and thus permits the free insertion of new records next to locked records. Gap locking is only used for foreign-key constraint checking and duplicate-key checking.Because gap locking is disabled, phantom problems may occur, as other sessions can insert new rows into the gaps. For information about phantoms, see Section 15.7.4, “Phantom Rows”.
Only row-based binary logging is supported with the
READ COMMITTED
isolation level. If you useREAD COMMITTED
withbinlog_format=MIXED
, the server automatically uses row-based logging.Using
READ COMMITTED
has additional effects:
还有
A consistent read means that
InnoDB
uses multi-versioning to present to a query a snapshot of the database at a point in time. The query sees the changes made by transactions that committed before that point of time, and no changes made by later or uncommitted transactions. The exception to this rule is that the query sees the changes made by earlier statements within the same transaction. This exception causes the following anomaly: If you update some rows in a table, aSELECT
sees the latest version of the updated rows, but it might also see older versions of any rows. If other sessions simultaneously update the same table, the anomaly means that you might see the table in a state that never existed in the database.If the transaction isolation level is
REPEATABLE READ
(the default level), all consistent reads within the same transaction read the snapshot established by the first such read in that transaction. You can get a fresher snapshot for your queries by committing the current transaction and after that issuing new queries.With
READ COMMITTED
isolation level, each consistent read within a transaction sets and reads its own fresh snapshot.Consistent read is the default mode in which
InnoDB
processesSELECT
statements inREAD COMMITTED
andREPEATABLE READ
isolation levels. A consistent read does not set any locks on the tables it accesses, and therefore other sessions are free to modify those tables at the same time a consistent read is being performed on the table.Suppose that you are running in the default
REPEATABLE READ
isolation level. When you issue a consistent read (that is, an ordinarySELECT
statement),InnoDB
gives your transaction a timepoint according to which your query sees the database. If another transaction deletes a row and commits after your timepoint was assigned, you do not see the row as having been deleted. Inserts and updates are treated similarly.
RC 与 RR 的锁定读通过锁来实现,一致性读通过 MVCC 机制实现。
锁
InnoDB 支持多粒度锁(multiple granularity locking),它允许行锁与表锁共存。
行级锁可以分为:行级共享锁(Shared)与行级排他锁(Exclusive)。InnoDB 的行级锁是通过锁定索引实现给的,换句话说,当一条 SQL 执行时不能使用到索引,那么此时就会升级为表锁。
另外还有意向锁(Intention),意向锁之间都是相互兼容的,因为意向锁表示的是一种意图,目的是为了表明某个事务正在锁定一行或者将要锁定一行。要想锁行,必然会经过库、表、页才能真正定位到行,所以此时应该给库、表、页上意图锁。
看下各种锁的兼容性:
| 锁兼容 | X | IX | S | IS |
|---|---|---|---|---|
| X | 冲突 | 冲突 | 冲突 | 冲突 |
| IX | 冲突 | 兼容 | 冲突 | 兼容 |
| S | 冲突 | 冲突 | 兼容 | 兼容 |
| IS | 冲突 | 兼容 | 兼容 | 兼容 |
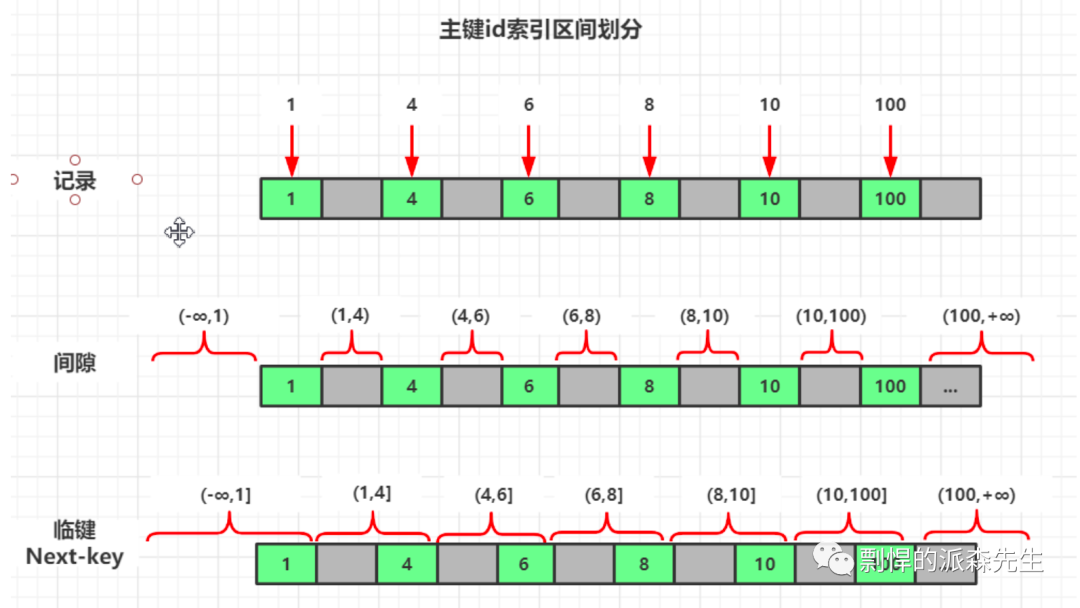
除了行锁表锁还有一种间隙锁(Gap Locks),间隙锁锁定的是索引记录之间的间隙,也可以是最后一个索引记录之前或之后的间隙,并不包括该索引记录本身;索引记录上的记录锁和索引记录之前的间隙上的间隙锁的组合称为 Next-Key Locks ,锁定的是一个范围,并且锁定记录本身。
MVCC
InnoDB 是一个多版本的存储引擎:它保留有关已更改行的旧版本的信息,以支持并发和回滚之类的事务功能。
这些信息存储在表空间中文件 ibdata 文件的回滚段区域。InnoDB 使用回滚段中的信息来执行事务回滚操作,也用于构建行记录的历史版本。回滚段中的日志分为插入日志和更新日志两种。插入日志仅在事务回滚时才需要,并且在事务提交后可以立即将其丢弃。更新日志只有在所有活跃事务都不需要这些信息时才会删除。
为实现 MVCC,InnoDB 为每一行数据添加三个隐藏字段。
DB_TRX_ID:6 字节,表示最后插入或更新该行的事务 ID;
DB_ROLL_PTR:7 字节,表示滚动指针,指向 undo log 的回滚段。在行记录更新后,指针指向更新前的记录信息;
DB_ROW_ID:6 字节,如果没有显示声明主键时,才添加该字段。
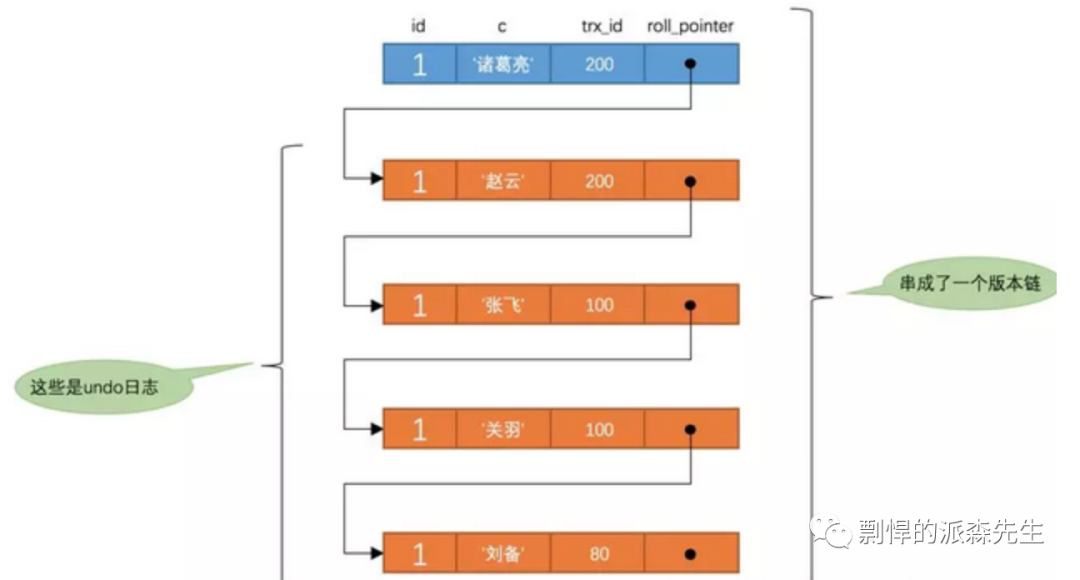
RC 和 RR 隔离级别利用 consistent read view(一致读视图)方式实现一致性读。所谓 consistent read view 就是在某一时刻给事务系统 trx_sys 生成快照,把当时 trx_sys 状态(包括活跃读写事务数组)m_ids 记录下来,之后的所有读操作根据其 trx_id 与生成快照时的 m_ids 作比较,以此判断 read view 对于事务的可见性。
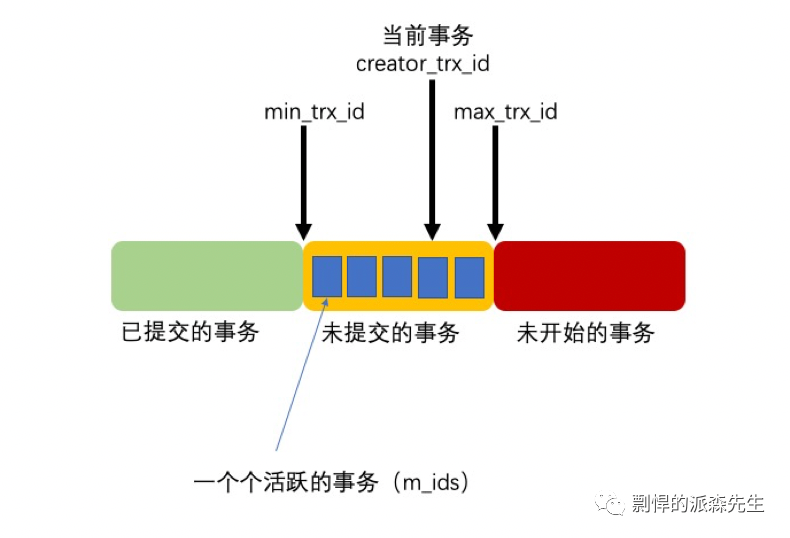
Read view 中主要包含4个比较重要的内容:
m_ids:表示在生成 read view 时当前系统中活跃的读写事务的事务id列表;
min_trx_id:表示在生成 read view 时当前系统中活跃的读写事务中最小的事务id,也就是 m_ids 中的最小值。
max_trx_id:表示生成 read view 时系统中应该分配给下一个事务的 id 值。
creator_trx_id:表示生成该 read view 的事务的事务 id。
有了这些信息,在访问某条记录时,只需要按照以下步骤判断记录的某个版本是否可见即可:
如果被访问版本的 trx_id 属性值与 read view 中的 creator_trx_id 值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问;
如果被访问版本的 trx_id 属性值小于 read view 中的 min_trx_id 值,表明生成该版本的事务在当前事务生成 read view 前已经提交,所以该版本可以被当前事务访问。
如果被访问版本的 trx_id 属性值大于 read view 中的 max_trx_id 值,表明生成该版本的事务在当前事务生成 read view 后才开启,所以该版本不可以被当前事务访问。
如果被访问版本的 trx_id 属性值在 read view 的 min_trx_id 和 max_trx_id 之间,那就需要判断一下 trx_id 是不是在活跃事务 m_ids 列表中。如果在,说明创建 read view 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 read view 时生成该版本的事务已经被提交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
RR 隔离级别和 RC 隔离级别的差别是创建 snapshot 时机不同。RR 隔离级别是在事务开始时刻,确切地说是第一次读操作创建 read view;RC 隔离级别则是每次读取数据都会创建 read view。这就说明了为什么 RC 只能防止脏读而不能防不可重读度与幻读,因为创建 read view 时机不一样。
总结
本文从事务的角度解释了一致性读与锁定读。MySQL InnoDB 的事务实现主要基于 redo log 与 undo log。其中 redo log 与 double write 机制实现了持久性,而 double write 落盘也是写的 undo log 文件。原子性与 MVCC 基于 undo log 实现。实现了原子性、隔离性与持久性,也就实现了数据的一致性,这才共同保证事务的有效性。
官网链接
事务:
https://dev.mysql.com/doc/refman/8.0/en/mysql-acid.html
锁:
https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
MVCC:
https://dev.mysql.com/doc/refman/8.0/en/innodb-multi-versioning.html
隔离级别:
https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
一致性读:
https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
锁定读:
https://dev.mysql.com/doc/refman/8.0/en/innodb-locking-reads.html
select 语句:
https://dev.mysql.com/doc/refman/8.0/en/select.html
