




在我们为线上 OLTP 业务选择 MySQL 存储引擎的时候,通常会从几个方面考虑:
事务支持(数据一致性)
性能(并发能力)
故障恢复(数据安全)
InnoDB 引擎无疑是在这几个方面表现非常出色的,这也就是为什么用 MySQL 数据库时通常都会选择 InnoDB 存储引擎的原因。前几篇文章介绍了 InnoDB 支持事务(ACID),一定程度满足高性能(支持行级锁)。本文重点介绍 InnoDB 如何实现 crash safe。
我们说数据故障恢复通常隐含的前提条件是对于已提交事务而言的,尚未提交的事务不在考虑范围内。InnoDB 的事务提交采用的是两阶段(two-phase commit)提交法,包括 prepare 阶段和 commit 阶段。当事务提交时,首先是 InnoDB 记录 redo log 日志,然后事务标记为 prepare,然后 server 层记录 binlog 日志,最后 InnoDB 标记事务为 commit,完成事务。为什么采用两阶段提交呢,主要还是为了满足主从复制的数据一致性。
下面分析一下不同阶段发生 crash 时,MySQL 对事务的处理:
当 MySQL 在新行记录写入 redo log 之前发生了 crash,因为 redo log 还没有写入,内存中的更新会丢失,此时事务没有提交,所以MySQL 再次重新启动之后,会将这个事务进行回滚。
当 MySQL 在新行记录写入了 redo log 之后发生了 crash,那么 redo log 目前是 prepare 阶段,而 binlog 没有写入,此时 MySQL 同样会进行事务回滚。
当 MySQL 在新行记录写入了 redo log 之后,binlog 也写入了,此时发生 crash,因为 MySQL 在恢复的时候,会做如下两个判断动作:
如果 redo log 里面的事务是完整的,也就是已经有了commit 标识,则直接提交;
如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:
a. 如果是,则提交事务;
b. 否则,回滚事务。
那么 MySQL 如何判断 binlog 的完整性呢?
如果 binlog 是 statement 模式的,最后面会出现一个 commit 的标识,如下:
use `test`/*!*/;SET TIMESTAMP=1590418900/*!*/;insert into test values (1,'zhangsan')/*!*/;# at 490#200525 23:01:40 server id 2025725 end_log_pos 521COMMIT/*!*/;复制
如果 binlog 是 row 模式的,最后面会出现一个 Xid,如下:
### UPDATE `mysql`.`ha_health_check`### WHERE### @1=1582266682672 /* LONGINT meta=0 nullable=1 is_null=0 */### @2='m' /* STRING(3) meta=65027 nullable=0 is_null=0 */### SET### @1=1582266698557 /* LONGINT meta=0 nullable=1 is_null=0 */### @2='m' /* STRING(3) meta=65027 nullable=0 is_null=0 */# at 790#200221 14:31:38 server id 3141372998 end_log_pos 821 CRC32 0xf63b387d Xid = 1289289427COMMIT/*!*/;# at 821#200221 14:31:44 server id 3141372998 end_log_pos 886 CRC32 0xc01e5aea GTID last_committed=2 sequence_number=3复制
InnoDB 的数据恢复是一个很复杂的过程,在其恢复过程中,需要 redo log、binlog、undo log 等参与,暂且把 InnoDB 的恢复过程划分为两个阶段:
第一阶段主要依赖于 redo log 的恢复;
第二阶段需要 binlog 和 undo log 的共同参与。
接下来,我们来具体了解下整个恢复的过程。
第一阶段
数据库启动后,InnoDB 会通过 redo log 找到最近一次 checkpoint 的位置,然后根据 checkpoint 相对应的 LSN 开始,获取需要重做的日志,接着解析获取的日志并且保存到一个哈希表中,最后通过遍历哈希表中的 redo log 信息,读取相关页进行恢复。
InnoDB 的 checkpoint 信息保存在日志文件中,即 ib_logfile0 的开始 2048 个字节中,checkpoint 有两个,交替更新。checkpoint 与日志文件的关系如下图:
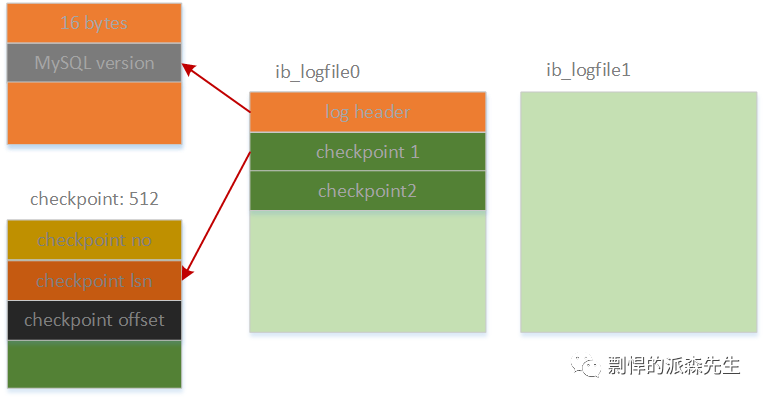
每个 checkpoint 默认大小为512字节,InnoDB 的 checkpoint 主要有三部分信息组成:
checkpoint no:checkpoint no 主要保存的是 checkpoint 号,因为 InnoDB 有两个 checkpoint,通过 checkpoint 号来判断哪个checkpoint 更新
checkpoint lsn:checkpoint lsn 主要记录了产生该 checkpoint 是 flush的 LSN,确保在该 LSN 前面的数据页都已经落盘,不再需要通过 redo log 进行恢复
checkpoint offset:checkpoint offset 主要记录了该 checkpoint 产生时,redo log 在 ib_logfile 中的偏移量,通过该 offset 位置就可以找到需要恢复的 redo log 开始位置。
通过以上 checkpoint 的信息,我们可以简单得到需要恢复的 redo log 的位置,然后通过顺序扫描该 redo log 来读取数据,比如我们通过 checkpoint 定位到开始恢复的 redo log 位置在 ib_logfile1 中的某个位置,那么整个 redo log 扫描的过程可能是这样的:
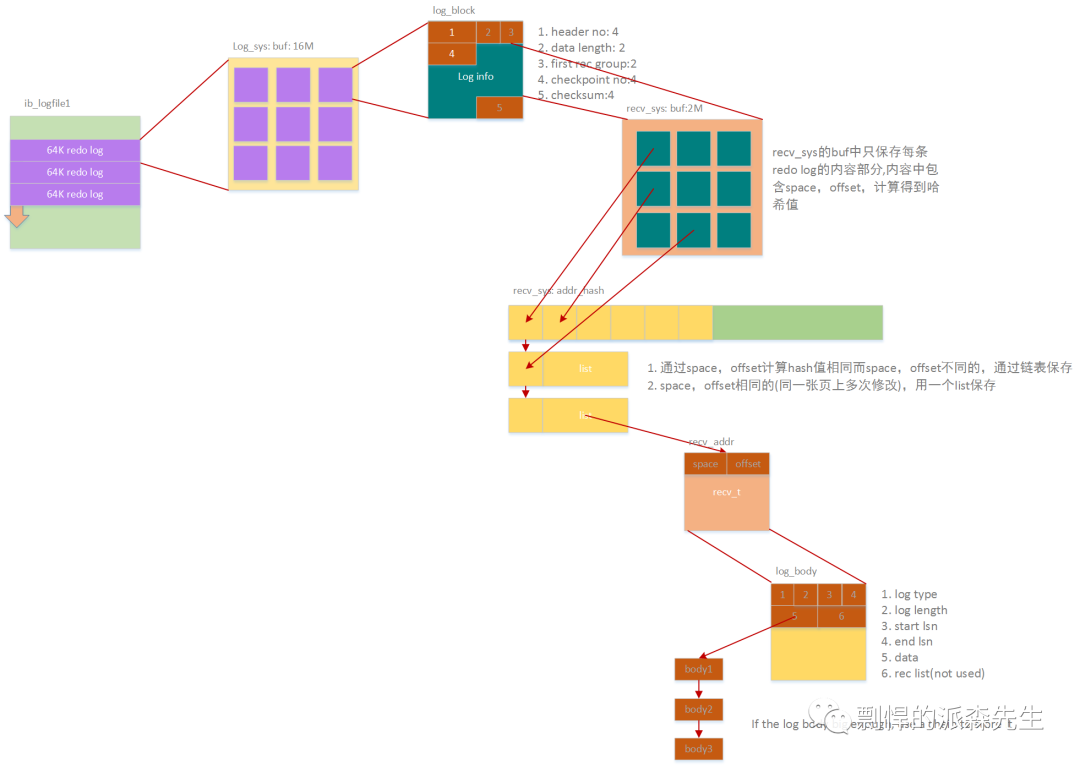
redo log 扫描过程
从 ib_logfile1 的指定位置开始读取 redo log,每次读取 4 * page_size 的大小,这里我们默认页面大小为 16K,所以每次读取 64K 的 redo log 到缓存中,redo lo g每条记录 (block) 的大小为 512 字节;
读取到缓存中的 redo log 通过解析、验证等一系列过程后,把 redo log 的内容部分保存到用于恢复的缓存,保存到恢复缓存中的每条信息主要包含两部分:(space, offset) 组成的位置信息和具体 redo log 的内容;
同时保存在恢复缓存中的 redo 信息会根据 (space, offset) 计算一个哈希值后保存到一个哈希表中。
Redo log 被保存到哈希表中之后,InnoDB 就可以开始进行数据恢复,只需要轮询哈希表中的每个节点获取 redo 信息,根据 (space, offset) 读取指定页面后进行日志覆盖。
Redo log 全部被解析并且 apply 完成,整个 InnoDB recovery 的第一阶段也就结束了。在该阶段中,所有已经被记录到 redo log 但是没有完成数据刷盘的记录都被重新落盘。然而,InnoDB 单靠 redo log 的恢复是不够的,这样还是有可能会丢失数据(或者说造成主从数据不一致)。因为在事务提交过程中,写 binlog 和写 redo log 提交是两个过程,写 binlog 在前而 redo 提交在后,如果 MySQL 写完 binlog 后,在 redo 提交之前发生了宕机,这样就会出现问题。那么 MySQL 又是如何保证在这样的情况下,数据还是一致的呢?这就需要进行第二阶段恢复。
第二阶段
在该阶段的恢复中,也被划分成两部分:
第一部分,根据 binlog 获取所有可能没有提交事务的 xid 列表;
第二部分,根据 undo 中的信息构造所有未提交事务链表;
最后通过上面两部分协调判断事务是否可以提交。
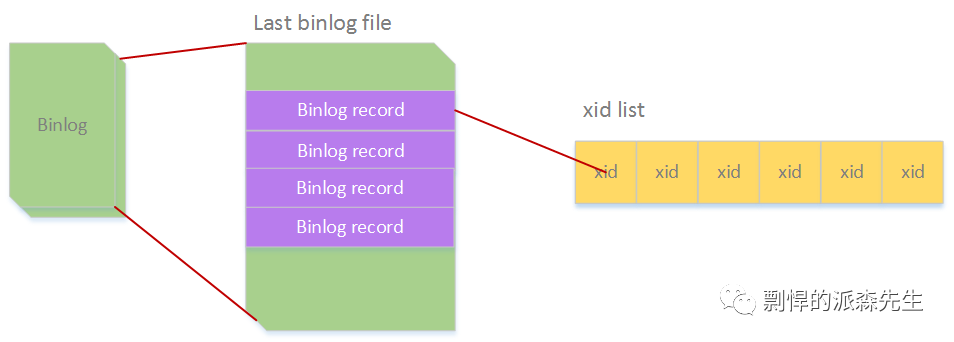
如上图中所示,MySQL 在第二阶段恢复的时候,先会去读取最后一个 binlog 文件的所有 event 信息,然后把 xid 保存到一个列表中,然后进行第二部分的恢复,如下:
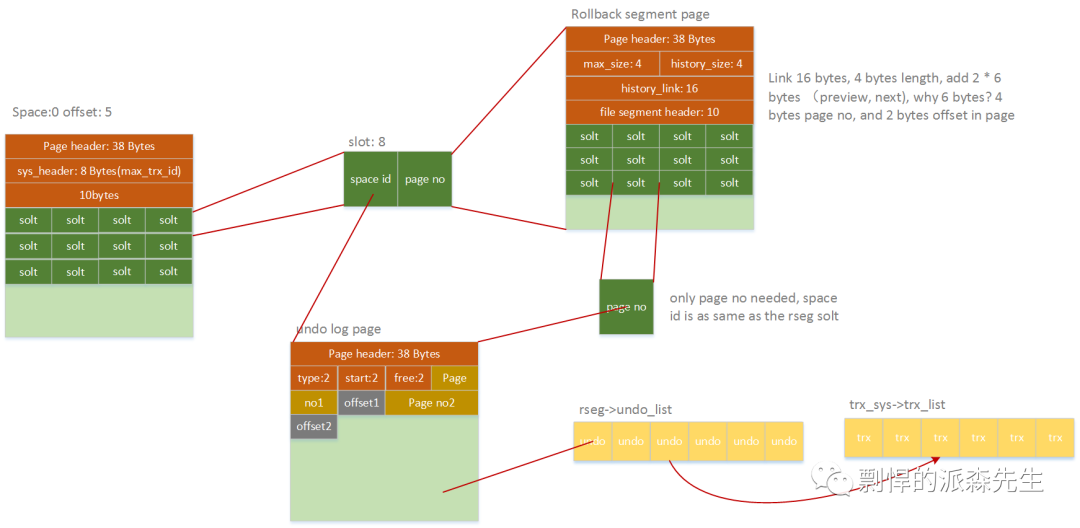
基于undo构造事务链表
我们知道,InnoDB 每个回滚段中保存了 undo log 的位置指针,通过扫描 undo 日志,可以构造出还未被提交的事务链表(存在于insert_undo_list 和 update_undo_list 中的事务都是未被提交的),所以通过起始页 (0, 5) 下的 slot 信息可以定位到回滚段,然后根据回滚段下的 undo 的 slot 定位到 undo 页,把所有的 undo 信息构建一个 undo_list,然后通过 undo_list 再创建未提交事务链表 trx_sys->trx_list。
基于上面两步, 我们已经构建了 xid 列表和未提交事务列表,那么在这些未提交事务列表中的事务,哪些需要被提交?哪些又该回滚?判断条件很简单:凡是 xid 在通过 binlog 构建的 xid 列表中存在的事务,都需要被提交。换句话说,所有已经记录 binlog 的事务,需要被提交,而剩下那些没有记录 binlog 的事务,则需要被回滚。
通过上述两个阶段的数据恢复,InnoDB 才最终完成整个恢复过程。
参考文档:
http://mysql.taobao.org/monthly/2015/04/01/
