

1



DeepSeek~R1,强化学习+知识蒸馏,比肩o1-2025.pdf
免费下载
计算机 / 行业专题报告 / 2025.01.22
请阅读最后一页的重要声明!
DeepSeek-R1:强化学习+知识蒸馏,比肩 o1
证券研究报告
投资评级:看好(维持)
最近 12 月市场表现
分析师
杨烨
SAC 证书编号:S0160522050001
yangye01@ctsec.com
相关报告
1. 《一文读懂美国 BIS 最新禁令》
2025-01-19
2. 《大模型系列报告(一):Transformer
架构的过去、现在和未来》 2025-01-
19
3. 《电力信息化研究框架:(一)总章》
2025-01-14
核心观点
❖ DeepSeek-R1 发布,对标 OpenAI o1 正式版。1 月 20 日,DeepSeek 正式
发布一系列 DeepSeek-R1 模型,包括 DeepSeek-R1-Zero、DeepSeek-R1 和
DeepSeek-R1-Distill 系列。DeepSeek-R1 模型推理能力优异,基准测试表现与
OpenAI-o1-1217 相当,且 API 服务定价远低于 OpenAI 同类产品。
❖ 大规模强化学习,激发大模型推理潜能:DeepSeek-R1-Zero 在技术路线上
实现了突破性创新,成为首个完全摒弃监督微调环节、完全依赖强化学习训练
的大语言模型,证明了无监督或弱监督学习方法在提升模型推理能力方面的
巨大潜力。在此基础上,DeepSeek-R1 对 R1-Zero 进行了改进。通过引入冷启
动数据,并历经推理导向强化学习、拒绝采样、监督微调以及全场景强化学习
的多阶段训练,充分发挥了强化学习的自学习和自进化能力。
❖ 知识蒸馏技术,让小模型也能“聪明”推理:DeepSeek 团队深入探索了
将 R1 的推理能力蒸馏到更小模型中的潜力,发现经过 R1 蒸馏的小模型在推
理能力上实现了显著提升,甚至超过了在这些小模型上直接进行强化学习的
效果,证明了 R1 学到的推理模式具有很强的通用性和可迁移性,能够通过蒸
馏有效传递给其他模型。这些结论为业界提供了新的启示:对小模型而言,蒸
馏优于直接强化学习,大模型学到的推理模式在蒸馏中得到了有效传递。
❖ DeepSeek-R1 高性价比 API 定价,极具商业化落地潜力: DeepSeek-R1
API 服务定价为每百万输入 tokens 1 元(缓存命中)/4 元(缓存未命中),每
百万输出 tokens 16 元,远低于可比大模型 API 服务。DeepSeek-R1 的高性价
比 API 定价有助于开发者在使用后加速模型的功能迭代,从而解决目前模型
存在的不足。
❖ 强化学习与知识蒸馏,DeepSeek 引领大小模型创新之路:对于大模型,
DeepSeek-R1-Zero 展示的无 SFT 的强化学习技术为大模型开发者提供了一种
新的训练范式,即通过强化学习来激发模型的内在潜力,从而在多个领域实现
更高效、更精准的推理能力。对于小模型,DeepSeek-R1-Distill 系列通过知识
蒸馏技术,成功将大模型的推理能力传递给小模型,实现了小模型在推理任务
上的显著提升,引领了小模型的发展方向。
❖ 投资建议:建议重点关注基础设施领域的公司,如英伟达、海光信息、寒武
纪、协创数据、英维克、中科曙光、浪潮信息、润泽科技、欧陆通、曙光数创、
申菱环境、东阳光等,同时持续关注全球各大模型厂商、学界的创新进展。
❖ 风险提示:技术迭代不及预期的风险;商业化落地不及预期的风险;政策支
持不及预期风险;全球宏观经济风险。
-18%
-5%
9%
22%
36%
49%
计算机 沪深300 上证指数

谨请参阅尾页重要声明及财通证券股票和行业评级标准
2
行业专题报告/证券研究报告
1 DeepSeek-R1 发布,对标 OpenAI o1 正式版 ...................................................................................... 3
2 大规模强化学习:激发大模型推理潜能 ............................................................................................... 4
2.1 DeepSeek-R1-Zero:以强化学习完全取代监管微调 ...................................................................... 4
2.2 DeepSeek-R1:引入冷启动与多阶段训练 ....................................................................................... 5
3 知识蒸馏技术:让小模型也能“聪明”推理 ....................................................................................... 7
4 DeepSeek-R1 高性价比 API 定价,极具商业化落地潜力 .................................................................. 9
5 总结和启示:强化学习与知识蒸馏,DeepSeek 引领 LLM 创新之路 ............................................ 10
6 投资建议 ................................................................................................................................................. 11
7 风险提示 ................................................................................................................................................. 11
图 1. DeepSeek 发布 DeepSeek-R1 模型 ....................................................................................................... 3
图 2. DeepSeek-R1 与 OpenAI 同类产品的基准测试比较 .......................................................................... 3
图 3. 随着 RL 训练推进,DeepSeek-R1-Zero 的 AIME 2024 基准测试成绩稳定且持续提升 .............. 4
图 4. DeepSeek-R1-Zero 与 OpenAI 的 o1 模型的测试成绩比较 ............................................................... 5
图 5. DeepSeek-R1-Zero 中间版本的“顿悟现象” .................................................................................... 5
图 6. DeepSeek-R1 的基准测试成绩在多个维度超越 V3 以及 OpenAI、Anthropic 的主流模型 .......... 7
图 7. DeepSeek-R1 蒸馏模型 .......................................................................................................................... 8
图 8. QwQ-32B-Preview 与经过强化学习和 R1 蒸馏 Qwen-32B 模型的基准测试成绩对比 .................. 8
图 9. DeepSeek-R1-Distill 系列小模型的基准测试成绩 .............................................................................. 9
图 10. DeepSeek-R1 与 OpenAI 同类产品的 API 价格比较 ..................................................................... 10
图 11. DeepSeek-R1 深度思考能力示例 ...................................................................................................... 11
内容目录
图表目录
XVRVmOoPoQtMpPtPsQsNzR6MaO9PoMnNmOqNkPpPmNkPmOoQ9PmNpOuOmNuMxNmMuN
谨请参阅尾页重要声明及财通证券股票和行业评级标准
3
行业专题报告/证券研究报告
1 DeepSeek-R1 发布,对标 OpenAI o1 正式版
DeepSeek-R1 正式发布。1 月 20 日,DeepSeek 正式发布了一系列 DeepSeek-R1 模
型,并上传 R1 系列的技术报告和各种信息。DeepSeek 此次共发布三组模型:
⚫ DeepSeek-R1-Zero:大规模使用强化学习(RL)技术,没有任何监督微调(SFT);
⚫ DeepSeek-R1:在强化学习前融入冷启动数据,多阶段训练;
⚫ DeepSeek-R1-Distill 系列:DeepSeek-R1 中蒸馏推理能力到小型密集模型,参
数规模分别为 1.5B、7B、8B、14B、32B 和 70B。
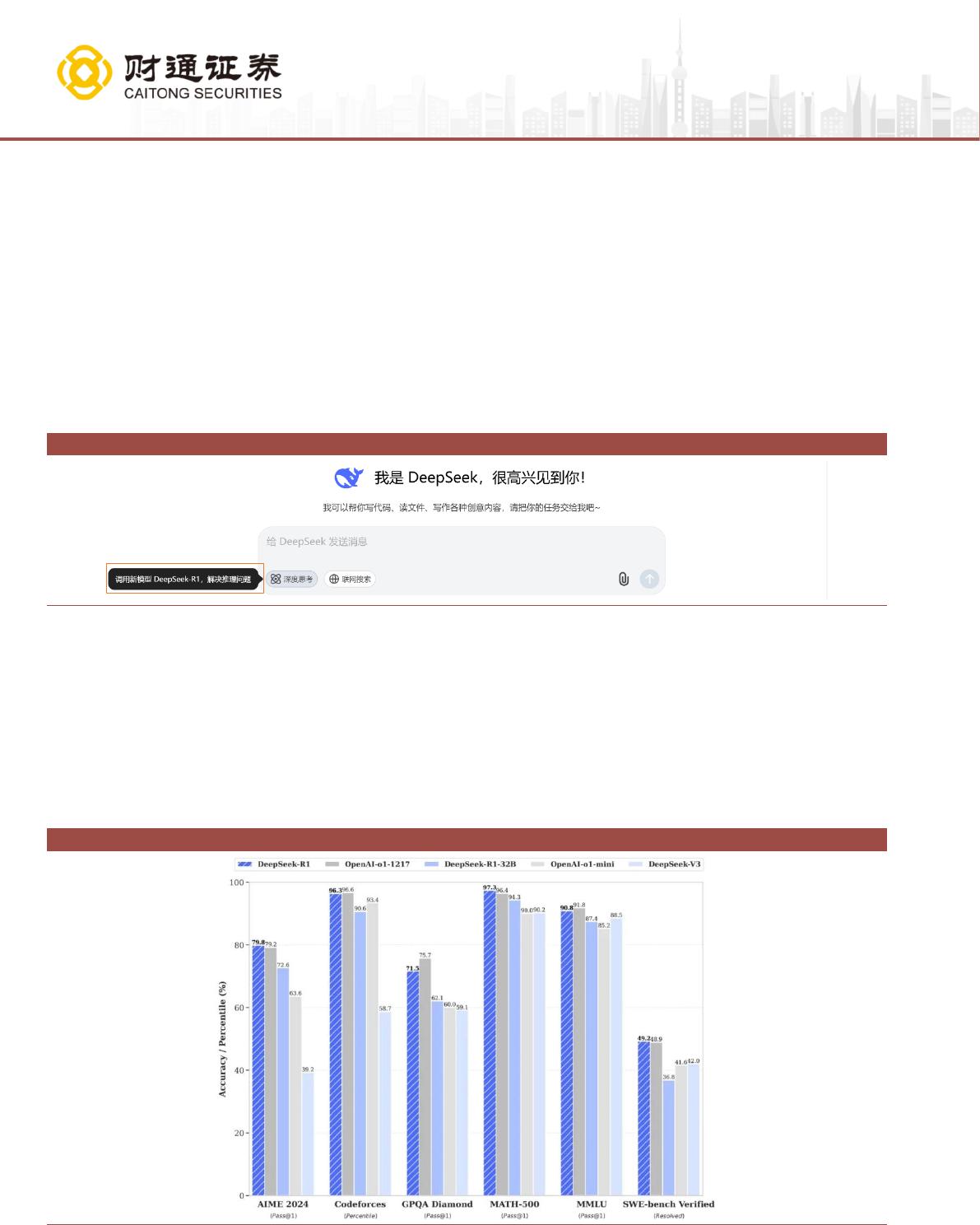
图1. DeepSeek 发布 DeepSeek-R1 模型
数据来源:DeepSeek 官网,财通证券研究所
DeepSeek-R1 模型推理能力优异,比肩 OpenAI o1 正式版。DeepSeek-R1 在 AIME
2024 上获得了 79.8%的成绩,略高于 OpenAI-o1-1217。在 MATH-500 上,它获得
了 97.3%的惊人成绩,表现与 OpenAI-o1-1217 相当,并明显优于其他模型。在编
码相关的任务中,DeepSeek-R1 在代码竞赛任务中表现出专家水平,在 Codeforces
上获得了 2029Elo 评级,在竞赛中表现优于 96.3%的人类参与者。对于工程相关
的任务,DeepSeek-R1 的表现略优于 OpenAI-o1-1217。
图2. DeepSeek-R1 与 OpenAI 同类产品的基准测试比较
数据来源:DeepSeek 官方,财通证券研究所
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传
下载排行榜
1
2
centos7下oracle11.2.0.4 rac安装详细图文(虚拟机模拟多路径).docx
3
白鳝-DBAIOPS:国产化替换浪潮进行时,信创数据库该如何选型?.pdf
4
PostgreSQL 缓存命中率低?可以这么做.doc
5
李飞-AI 引领的企业级智能分析架构演进与行业实践.pdf
6
达梦数据2024年年度报告.pdf
7
刘杰-江苏广电:从Oracle+Hadoop到TiDB,数据中台、实时数仓运维0负担.pdf
8
晋鑫宇_AI Agent 赋能社交媒体-构建未来社交生态的核心驱动力.pdf
9
刘晓国-基于 Elasticsearch 创建企业 AI 搜索应用实践.pdf
10
Sunny duan-大模型安全挑战与实践:构建 AI 时代的安全防线.pdf

文档被以下合辑收录
相关文档
评论