




multi-model-data_EDBT.pdf
免费下载

Multi-model Data Management: What’s New and What’s
Next?
Jiaheng Lu
Department of Computer Science
University of Helsinki, Finland
jiaheng.lu@helsinki.fi
Irena Holubová
∗
Department of Software Engineering
Charles University, Czech Republic
holubova@ksi.mff.cuni.cz
ABSTRACT
As more businesses realized that data, in all forms and sizes,
is critical to making the best possible decisions, we see the
continued growth of systems that support massive volume of
non-relational or unstructured forms of data. Nothing shows
the picture more starkly than the Gartner Magic quadrant
for operational database management systems, which as-
sumes that, by 2017, all leading operational DBMSs will of-
fer multiple data models, relational and NoSQL, in a single
DBMS platform. Having a single data platform for man-
aging both well-structured data and NoSQL data is bene-
ficial to users; this approach reduces significantly integra-
tion, migration, development, maintenance, and operational
issues. Therefore, a challenging research work is how to
develop efficient consolidated single data management plat-
form covering both relational data and NoSQL to reduce
integration issues, simplify operations, and eliminate migra-
tion issues. In this tutorial, we review the previous work on
multi-model data management and provide the insights on
the research challenges and directions for future work. The
slides and more materials of this tutorial can be found at
http://udbms.cs.helsinki.fi/?tutorials/edbt2017.
1. INTRODUCTION
In recent years the term big data has become a phe-
nomenon that breaks down borders of many technologies
and approaches that have so far been acknowledged as ma-
ture and robust for any conceivable application. One of
the most challenging issues is the “Variety” of the data. It
may be presented in various types and formats – structured,
semi-structured and unstructured – and produced by differ-
ent sources, and hence natively have various models.
To address the Variety challenge, probably the first type of
respective specific database management systems (DBMS)
are NoSQL databases [34] which can be further classified
1
to
∗
Supported by the M
ˇ
SMT
ˇ
CR grant PROGRES.
1
http://nosql-database.org/
Copyright is with the authors. Published in Proc. 20th International Con-
ference on Extending Database Technology (EDBT), March 21-24, 2017 -
Venice, Italy: ISBN 978-3-89318-073-8, on OpenProceedings.org. Distri-
bution of this paper is permitted under the terms of the Creative Commons
license CC-by-nc-nd 4.0.
soft (e.g., object or XML DBMSs), and core (e.g., key/value,
document, column, or graph DBMSs). From another point
of view we can classify them to single-model and multi-
model. The latter type enables to store and process struc-
turally different data, i.e. data with distinct models, which
corresponds to the Variety aspect of big data. This approach
can be considered as an opposite idea to the “One Size Does
Not Fit All” argument [39]. However, it can be also under-
stood as a way of re-architecting traditional database mod-
els, namely the relational model, to handle new database
requirements that were not present during its establishment
decades ago [24]. Nothing shows the picture more starkly
than the Gartner Magic quadrant for operational database
management systems [18], which assumes that, by 2017, all
leading operational DBMSs will offer multiple data models,
relational and NoSQL, in a single DBMS platform.
In this tutorial, we review the previous work on multi-
model data management and give insights on the research
challenges and opportunities. First, we show that the idea
of multi-model DBMSs is not a brand new approach. It can
be traced back to Object-Relational Data Management Sys-
tems (ORDBMS) in the early 1990s and in a more broader
scope even to federated and integrated DBMSs in the early
1980s. An ORDBMS system can manage different types of
data such as relational, object, text and spatial by plugging
domain specific data types, functions and index implementa-
tions into the DBMS kernels. For instance, PostgreSQL [6]
can store relational, spatial and XML data. Recently, we
can observe a new trend among NoSQL databases in the
support of multiple data models against a single, integrated
backend, while meeting the growing requirements for scal-
ability and performance. For example, OrientDB [7] is a
graph database extended to support multi-model queries,
while ArangoDB [10] is moving from purely document model
to the support of also key-value, graph and JSON data.
Second, we dive in three key aspects of technology in a
multi-model database system including (1) storage strategies
for multi-model data; (2) query languages accessing data
across multiple models; and (3) query evaluation and its
optimization in the context of multiple data models.
Finally, we provide comparison of features of the existing
multi-model DBMSs and we discuss related open problems
and remaining challenges.
To the best of our knowledge this is the first tutorial to dis-
cuss the state-of-the-art research works and industrial trends
in the context of multi-model data management. Recent tu-
torials related to the big data world include SQL-on-Hadoop
Systems [12], open-source on big data [16], knowledge bases
in big data analytics [40], or big time-series data manage-
ment [35], i.e., different aspects of big data challenges.
2. COVERED TOPICS
2.1 Background, History and Classification
In the first part of the tutorial we first provide a mo-
tivating example of a multi-model application and briefly
describe most common data models used in the world of
multi-model DBMSs (mainly key/value, relational, JSON,
XML, and graph). Next, we focus on their history and clas-
sification.
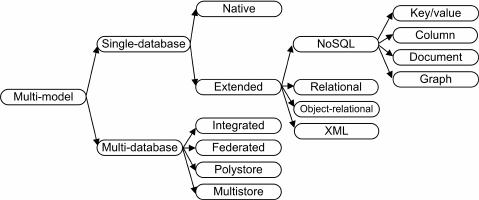
The world of multi-model DBMSs can be divided into
single-database and multi-database (see Figure 1), depend-
ing on whether the multiple models are handled in a single
DBMS or there exist a number of cooperating or centrally
managed DBMSs, each handling own data model(s).
Figure 1: Classification of multi-model data man-
agement systems
The first approaches towards multi-model multi-database
data management can be seen in integrated DBMSs [37] and
federated DBMSs [20, 36]. Both types of systems can be
characterized as a meta-DBMS consisting of a collection of
(possibly) heterogeneous DBMSs which can differ in data
models, constraints, query languages, and/or transaction
management. The data integration is usually based on the
idea of mediators [43]. The main difference is that in fed-
erated systems the DBMSs are autonomous and cooperate.
Thus federated databases provide a compromise between no
integration (where the users must explicitly interface with
multiple autonomous DBMSs) and total integration (where
the users can access data through a single global interface
but cannot directly access a DBMS as a local user) [36].
Recently there has appeared a successor of federated data-
bases – so-called polystore systems [38]. The key represen-
tative, system BigDAWG [17], also enables users to pose
declarative queries that span several DBMSs. However, it
consists of islands of information, i.e. collections of DBMSs
accessed with a single query language (e.g., relational or ar-
ray). Cross-island queries are supported using casting (e.g.,
tables to arrays or vice versa).
Another recent related approach from the area of big data
analytics represent so-called multistore systems [23, 44]. For
example system MISO [23] involves two types of data stores
– a parallel relational data warehouse and a system for mas-
sive data storage and analysis (namely HDFS with Apache
Hive). The aim is to combine their capabilities in order to
gain more efficient query processing.
Multi-model single-database DBMSs can also be further
classified. Probably the most natural classification is ac-
cording their origin [2] (see Figure 1). Similarly to XML
databases, we can distinguish native and extended DBMSs
depending on whether the support for multiple models was
the initial feature of the system, or it was added later. In
the latter case we can find representatives amongst all four
core types of NoSQL databases as well as traditional DBMS.
2.2 Overview and Comparison
In the second part of the tutorial we take a closer look
at particular multi-model single-database DBMSs from the
point of view of three key aspects of a database system.
The first database challenge is to develop a strategy to
store distinct data models. Approaches used in the ex-
isting multi-model DBMSs can be classified according to
the combination of used models. The main group (systems
such as, e.g., PostgreSQL or Microsoft SQL Server [9]) is
naturally represented by the (object-)relational model ex-
tended towards other data models, such as JSON, XML etc.
From the set of NoSQL databases we can observe the ten-
dency towards multi-model data management among col-
umn stores [4], key/value stores [11], or graph databases [7].
And there are also representatives of native hierarchical data
stores [5] which support other types of data models.
The second database challenge is a query language capa-
ble of accessing and combining data having distinct models.
Naturally, having a single language for managing queries
over both (semi-)structured and NoSQL data is convenient
to users. And again, in general, this is not a new fea-
ture of a query language, as we can see, e.g., in the case
of the SQL/XML [21] extension of SQL. Most of the cur-
rent NoSQL multi-model databases across the spectrum of
storage strategies [6, 4, 7] support an SQL-like language.
However, as we will show, despite this approach is natural
and user-friendly, there are significant differences as well as
persisting limitations. There also exist XML or JSON query
language extensions towards other data models (e.g., Mark-
Logic’s XPath for JSON [3]), as well as specific languages
like, e.g., SQL++[31], JSONiq [33], or FSD domain-specific
language [24]. In a more broader scope paper [32] identifies
a subset of SQL for access to NoSQL systems or paper [13]
evaluates the possibilities of using declarative structures in
NoSQL data processing. We also discuss other techniques,
like, e.g., [14, 32, 41].
The third challenge corresponds to query evaluation and
optimization. As expected, the world of multi-model DBMSs
exploits and extends verified database approaches such as in-
dices (B+ tree, inverted, range, spatial, full text, etc.), views
and materialization, hashing etc. In this part of the tutorial
we overview and compare the query optimization technolo-
gies used in the previously discussed systems. We also intro-
duce the related area of benchmarking multi-model database
systems. As more and more platforms are proposed to deal
with multi-model data, it becomes important to have bench-
marks specific for this next generation of database systems.
We mention several systems for benchmarking big data sys-
tems including YCSB [15], TPCx-BB [19], Bigframe [22],
and UniBench [25].
We conclude this part with comparison of features of the
state-of-the-art systems in the form of system-feature ma-
trices and a timeline demonstrating their evolution.
2.3 Open Problems and Challenges
In the last part of the tutorial we focus on open problems
that must be addressed to ensure the success of multi-model
DBMSs. The key areas to be discussed involve:
• Unified query processing and index structures,
• Multi-model main memory structure,
• Multi-model schema extraction, design, and optimiza-
tion, especially in the context of schema-less DBMSs,
• Evolution management and model extensibility,
• Benchmarking and standardization.
In each of these areas we first briefly overview the solutions
in the world of single-model DBMSs as well as eventually ex-
isting (partial) solutions among multi-model DBMSs. Then
we explain the related problems in the context of multi-
model databases, eventually with existing preliminary solu-
tions. We assume that this part will raise questions to be
discussed in the end of the tutorial.
3. TUTORIAL ORGANIZATION
The tutorial is planned for 1.5 hours and will have the
following structure:
Motivation (5’). We motivate the need for multi-model
data management by several examples in the era of big data.
History and classification (10’). We introduce the his-
tory and classification of multi-model databases, including
ORDBMS [9], NoSQL databases [7, 10] and Polyglot per-
sistence [38, 43].
Multi-model data storage (10’). We introduce vari-
ous methods to store multi-model data, including object-
relational model, graph model, document model and native
hierarchical model.
Multi-model data query languages (15’). We compare
languages for multi-model data processing, such as AQL [10],
SQL++ [31], OrientDB SQL [7], and SQL/XML [21].
Multi-model query processing (15’). We overview the
multi-model extensions of traditional query processing ap-
praoches and indexes, such as B+ tree [1, 30], inverted in-
dex [8], schema discovery [42, 24], and cross-model query
processing [10, 7].
Multi-model database benchmarking (15’). We in-
troduce the previous and on-going benchmark systems for
multi-model data, such as TPCx-BB [19], Bigframe [22],
YCSB [15], or UniBench [25].
Open problem and challenges (20’). We conclude with
a discussion of open problems and challenges for database
research in the area of multi-model data management [29].
4. GOALS OF THE TUTORIAL
4.1 Learning Outcomes
The main learning outcomes of this tutorial are as follows:
• Motivation, classification and historical evolution of
multi-model DBMSs.
• An overview of technologies and algorithms used by
the current multi-model DBMSs including storing, query
languages, and query optimization.
• Comparison of features of current multi-model DBMSs.
• A discussion of research challenges and open problems
of multi-model data management.
4.2 Intended Audience
This tutorial is intended for a wide scope of audience,
e.g. for developers and architects to get insights from the
emerging industrial trends and its connections to scientific
research, for stakeholders to make wise and informed de-
cisions on investments in multi-model DBMS products, for
motivated researchers and developers to select new topics
and contribute their expertise on multi-model data, and, of
course, for new developers and students to quickly gain a
comprehensive picture and understand the new trends and
the state-of-art techniques in this field.
Basic knowledge in relational and NoSQL databases is
sufficient to follow the tutorial. Some background in semi-
structured and graph query optimization would be useful,
but is not necessary.
5. SHORT BIBLIOGRAPHIES
Jiaheng Lu is an Associate Professor at the University
of Helsinki, Finland. He received Ph.D. degree at the Na-
tional University of Singapore in 2007. He did two-year Post-
doctoral research at the University of California, Irvine. His
main research interests lie in the big data management and
database systems, and specifically in the challenge of effi-
cient data processing from real-life, massive data repository
and Web. He has published more than sixty journal and
conference papers. He has extensive experiences of the in-
dustrial cooperations with IBM, Microsoft and Huawei for
the projects of NoSQL databases and performance tuning
on distributed systems. He has published several books,
on XML [27], Hadoop [28] and NoSQL databases [26]. His
book [28] on Hadoop is one of the top-10 best-selling books
in the category of computer software in China in 2013.
Irena Holubov´a is an Associate Professor at the Charles
University, Prague, Czech Republic, where she received Ph.D.
degree in 2007. Her current main research interests include
big data management and NoSQL databases, big data gen-
erators and benchmarking, evolution and change manage-
ment of database applications, analysis of real-world data,
and schema inference. She has published more than 80 con-
ference and journal papers; her works gained 4 awards. She
has also published 2 books on XML technologies and NoSQL
databases. She serves as an independent expert for evalua-
tion and monitoring of EU FP7 and H2020 projects.
6. REFERENCES
[1] Improving Secondary Index Write Performance in 1.2.
DataStax, Inc., 2013.
[2] Neither Fish Nor Fowl: the Rise of Multi-Model
Databases. The 451 Group, 2013.
[3] Application Developer’s Guide – Chapter 18 Working
With JSON. MarkLogic Corporation, 2016.
[4] Cassandra: Manage Massive Amounts of Data, Fast,
without Losing Sleep. The Apache Software
Foundation, 2016.
[5] MarkLogic: The World’s Best Database for Integrating
Data From Silos. MarkLogic Corporation, 2016.
[6] The Official Site for PostgreSQL, the World’s Most
Advanced Open Source Database. The PostgreSQL
Global Development Group, 2016.
[7] OrientDB – a 2nd Generation Distributed Graph
Database. OrientDB, 2016.
of 4
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。

下载排行榜
1
2
白鳝-DBAIOPS:国产化替换浪潮进行时,信创数据库该如何选型?.pdf
3
centos7下oracle11.2.0.4 rac安装详细图文(虚拟机模拟多路径).docx
4
PostgreSQL 缓存命中率低?可以这么做.doc
5
李飞-AI 引领的企业级智能分析架构演进与行业实践.pdf
6
达梦数据2024年年度报告.pdf
7
刘杰-江苏广电:从Oracle+Hadoop到TiDB,数据中台、实时数仓运维0负担.pdf
8
Sunny duan-大模型安全挑战与实践:构建 AI 时代的安全防线.pdf
9
王璟尧_脱敏_从数据到决策.pdf
10
AI 开发工具的过去现在和将来-施乔.pdf

相关文档
评论