




pg_bulkload 是 PostgreSQL 的一个高速数据加载工具,相对于 copy 命令。最大的优势是速度。在 pg_bulkload 的直接模式下,它将跳过共享缓冲区和 WAL 缓冲区,直接写入文件。它还包括数据恢复功能,可在导入失败时进行恢复。
GitHub:https://github.com/ossc-db/pg_bulkload
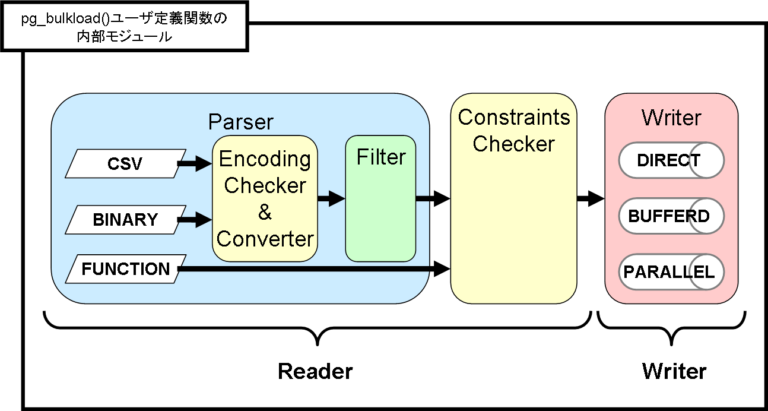
pg_bulkload 主要包括两个模块:reader 和 writer。读取器负责读取文件和解析元组,写入器负责将解析后的元组写入输出源。
环境
- PostgreSQL 版本:12.3 稳定
- pg_bulkload 版本:3.1.17
- 数据库名称:bldemo,用户:postgres
安装
在测试环境编译的时候发现需要提前安装以下组件:
- gcc
- openssl-devel
然后就可以正常安装了:
$ cd pg_bulkload
$ make USE_PGXS=1
$ su
$ make USE_PGXS=1 install
复制然后,有两种方法可以将函数注册到数据库中:
1.执行SQL文件
[root@localhost pg_bulkload-3.1.17]# find / -name pg_bulkload.sql find: ‘/run/user/1000/gvfs’: Permission denied /root/pg_bulkload-3.1.17/lib/pg_bulkload.sql /opt/HighGo4.5.6-see/share/postgresql/extension/pg_bulkload.sql # Here the two pg_bulkload.sql files is the same复制
pg_bulkload.sql 的内容如下:
/*
* pg_bulkload.sql
*
* Copyright (c) 2007-2021, NIPPON TELEGRAPH AND TELEPHONE CORPORATION
*/
-- Adjust this setting to control where the objects get created.
BEGIN;
CREATE SCHEMA pgbulkload;
CREATE FUNCTION pgbulkload.pg_bulkload(
IN options text[],
OUT skip bigint,
OUT count bigint,
OUT parse_errors bigint,
OUT duplicate_new bigint,
OUT duplicate_old bigint,
OUT system_time float8,
OUT user_time float8,
OUT duration float8
)
AS '$libdir/pg_bulkload', 'pg_bulkload' LANGUAGE C VOLATILE STRICT;
COMMIT;
复制如果直接创建,会报错:
[root@localhost pg_bulkload-3.1.17]# psql -U bulkload -d bldemo -f /opt/postgres/share/postgresql/extension/pg_bulkload.sql
BEGIN
CREATE SCHEMA
psql:/opt/postgres/share/postgresql/extension/pg_bulkload.sql:23: ERROR: permission denied for language c
ROLLBACK
复制出现上述问题时,需要使用管理员用户执行’update pg_language set lanpltrusted = true where oid = 13;’ 在数据库中。
然后就可以正常创建函数了:
[root@localhost pg_bulkload-3.1.17]# psql -U postgres -d bldemo -f /opt/HighGo4.5.6-see/share/postgresql/extension/pg_bulkload.sql
BEGIN
CREATE SCHEMA
CREATE FUNCTION
COMMIT
复制2.在数据库中创建扩展
bldemo=# create extension pg_bulkload;
CREATE EXTENSION
复制导入数据
在参考文档中,它使用了’seq 100000| awk ‘{print $0″|lottu”}’ > tbl_lottu_output.txt’ 生成数据,这里我们使用了 ‘dstat –outpub dstat.csv’。
创建表的SQL语句:
create table dstat(usr numeric, sys numeric, idl numeric, wai numeric, hiq numeric, siq numeric, read numeric, writ numeric, recv numeric, send numeric, "in" numeric, "out" numeric, "int" numeric, csw numeric);
复制1.直接导入数据:
[root@localhost ~]# pg_bulkload -i dstat.csv -O dstat -l dstat.log -P dstat_bad.txt -o "TYPE=CSV" -o "DELIMITER=," -d bldemo -U postgres
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
1522 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
复制导入前清理表数据
bldemo=> select count(*) from dstat ;
count
-------
1522
(1 row)
bldemo=> copy dstat from '/root/dstat.csv' with csv header;
ERROR: must be sysdba or a member of the pg_read_server_files role to COPY from a file
HINT: Anyone can COPY to stdout or from stdin. psql's \copy command also works for anyone.
bldemo=> \copy dstat from '/root/dstat.csv' with csv
COPY 1522
bldemo=> select count(*) from dstat ;
count
-------
3044
(1 row)
复制[root@localhost ~]# pg_bulkload -i dstat.csv -O dstat -l dstat.log -P dstat_bad.txt -o "TYPE=CSV" -o "DELIMITER=," -o "TRUNCATE=YES" -d bldemo -U postgres
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
1522 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
复制bldemo=> select count(*) from dstat ;
count
-------
1522
(1 row)
复制2.使用控制文件导入数据
新建控制文件:
INPUT = /root/dstat.csv
PARSE_BADFILE = /root/dstat_bad.txt
LOGFILE = /root/dstat.log
LIMIT = INFINITE
PARSE_ERRORS = 0
CHECK_CONSTRAINTS = NO
TYPE = CSV
SKIP = 0
DELIMITER = ,
QUOTE = "\""
ESCAPE = "\""
OUTPUT = public.dstat
MULTI_PROCESS = NO
VERBOSE = YES
WRITER = DIRECT
DUPLICATE_BADFILE = /opt/postgres/data/pg_bulkload/20210414110538_bldemo_public_dstat.dup.csv
DUPLICATE_ERRORS = 0
ON_DUPLICATE_KEEP = NEW
TRUNCATE = NO
复制导入数据:
bldemo=> select count(*) from dstat ;
count
-------
1522
(1 row)
复制[root@localhost ~]# pg_bulkload /root/dstat.ctl -d bldemo -U postgres
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
1522 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
复制bldemo=> select count(*) from dstat ;
count
-------
3044
(1 row)
复制结语
这是pg_bulkload文档中给出的文档,现在我们已经学会了如何使用pg_bulkload,享受吧!
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
玩一玩系列——玩玩pg_mooncake(PostgreSQL的高性能列存新贵)
小满未满、
519次阅读
2025-03-03 17:18:03
王炸!OGG 23ai 终于支持从PostgreSQL备库抽取数据了
曹海峰
390次阅读
2025-03-09 12:54:06
玩一玩系列——玩玩login_hook(一款即将停止维护的PostgreSQL登录插件)
小满未满、
372次阅读
2025-03-08 18:19:28
明明想执行的SQL是DELETE、UPDATE,但为什么看到的是SELECT(FDW的实现原理解析)
小满未满、
349次阅读
2025-03-19 23:11:26
PostgreSQL初/中/高级认证考试(3.15)通过考生公示
开源软件联盟PostgreSQL分会
300次阅读
2025-03-20 09:50:36
IvorySQL 4.4 发布 - 基于 PostgreSQL 17.4,增强平台支持
通讯员
191次阅读
2025-03-20 15:31:04
套壳论
梧桐
183次阅读
2025-03-09 10:58:17
命名不规范,事后泪两行
xiongcc
173次阅读
2025-03-13 14:26:08
版本发布| IvorySQL 4.4 发布
IvorySQL开源数据库社区
114次阅读
2025-03-13 09:52:33
宝藏PEV,助力你成为SQL优化高手
xiongcc
107次阅读
2025-03-09 23:34:23



