





基于Hive Connector的openLooKeng Connector 创建复用机制剖析
本文作者
程一舰 中国光大银行总行信息科技部
前言
openLooKeng作为一种跨多源数据的联邦计算引擎,天然的支持第三方数据源Connector的开发。如何进行简单的Connector的开发这里就不具体介绍了,具体可以参考自带的example示例。最近由于业务需要,需要对Hive Connector进行改造以支持我们的场景。为了避免对社区原生Hive Connector的侵入,我通过复用并自定义的方式创建了一个新的Mpp Connector。这里就以此为例,谈一谈这其中的机制。
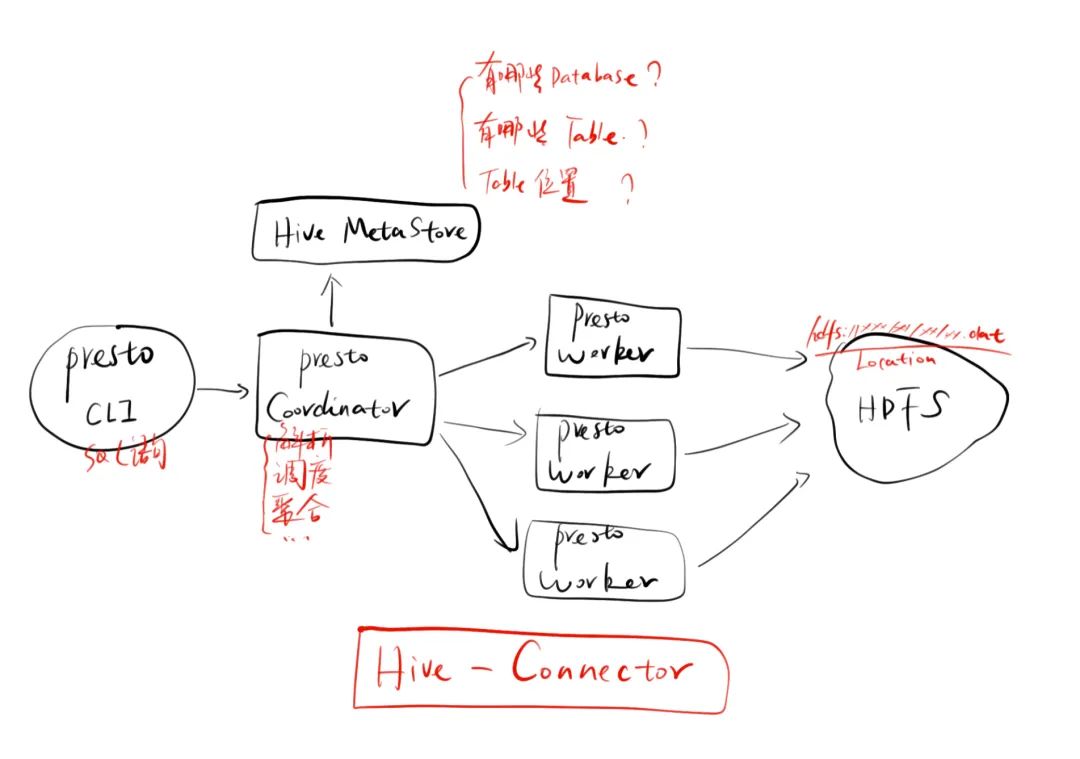
1.执行逻辑
上图是一个Hive Connector的整体执行逻辑,一条查询语句到了openLooKeng,会通过Coordinator进行解析,然后通过Thrift接口访问Hive的Metastore获取相关的元数据信息,这其中包括有哪些数据库,每个库里有哪些表以及表的数据位置及字段等信息。拿到这些信息后就会通过调度任务去HDFS上的具体位置拉取数据,最后将数据返回Coordinator进行聚合并返回。这整个过程最重要的就是获取元数据和拉取数据两个过程。话又说远了,如何创建一个新的Connector并复用Hive Connector的功能呢?
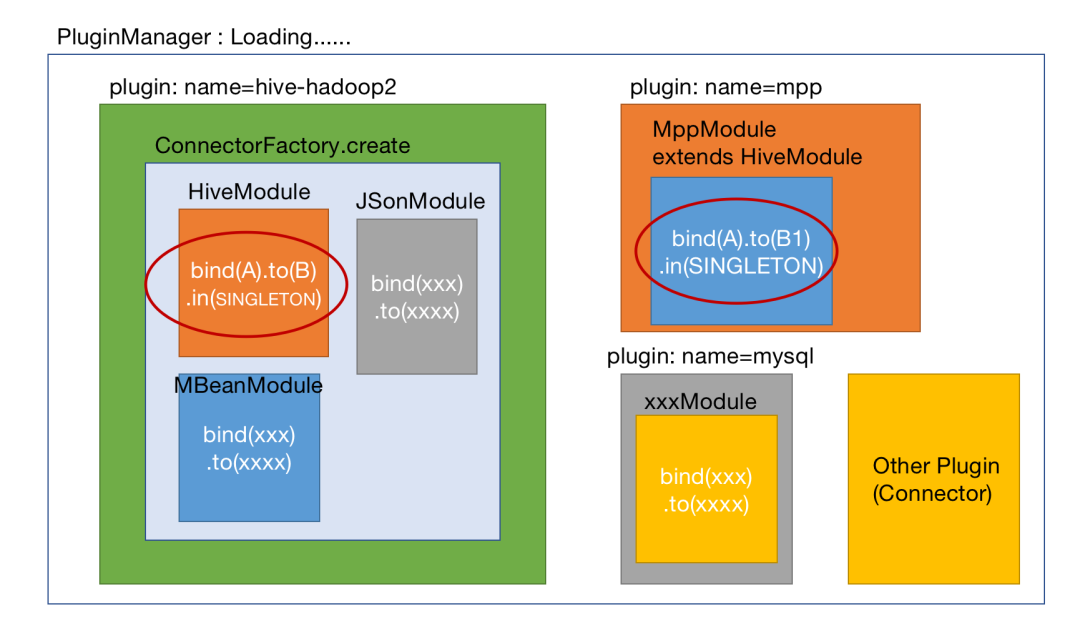
2.Plugin加载机制
上图是我用手画的一个大体的加载机制的加载图,可能不是特别的准确但是不妨碍说事儿。openLooKeng引擎在编译后,我们可以看到下图这样的结构
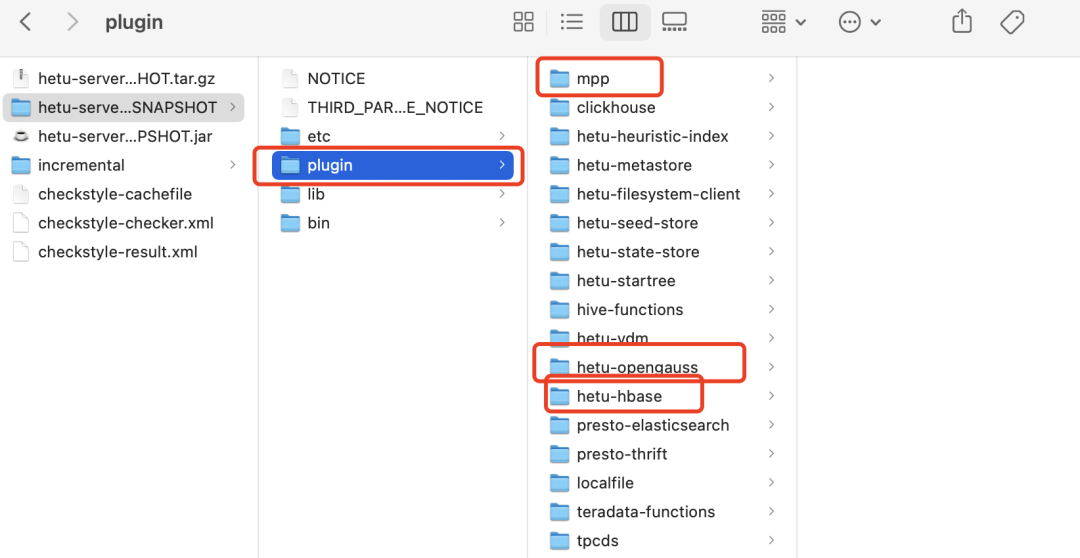
所有的Connector都在plugin目录里,当Presto引擎启动后,会通过PluginManager来对每个Connector进行加载,如加载图所示。当具体进行某个Connector加载的时候,就会访问该Connector的Plugin实现,在这里会定义Connector的名字,例如hive-hadoop2,mysql,oracle,clickhouse等。然后,会通过调用这里的ConnectorFactory来进行Connector实例的生成。
在openLooKeng中,对于一个Connector的具体实现也做了一些规定,有些接口是必须实现的。
(具体可点此参考:源码学习(二)--presto Connector 机制)
比如ConnectorMetadata、SplitManager等,这些具体的实现都需要包含在Connector中。所以ConnectorFactory进行创建Connector实例的时候,需要把这些都包含进去。所以我们可以看到加载图中,有不同颜色的Module,这些不同颜色的Module就是根据主题来划分的一些接口的实现。
Module是Google提供的一种注入框架Guice的一个接口,在这里面你可以对接口和实现类进行绑定(关联),比如接口ConnectorMetadata,你具体的实现类为HiveConnectorMetadata,在这里你可以通过binder.bind(ConnectorMetadata.class).to(HiveConnectorMetadata.calss).in(Scopes.SINGLETON)来进行描述。
3.自定义Connector
其实通过上面的描述,我们大概已经看到了几个关键的接口(或类)了:Plugin/ConnectorFactory/Module,那接下来我们看下如何创建一个新的Connector并实现复用。
(1)创建新模块
首先,我们先创建一个新的模块,起名为presto-mpp,指定父类为presto-root。然后,在hetu-server的src/main/provisio/hetu.xml中添加如下的内容,用来制定打包路径信息。

再然后,确保在父目录下的pom.xml中添加了模块。

有了以上,就创建好了一个新的Connector了,但是此时如果编译,会告诉你该实现的接口都还没实现,所以接下来我们就要实现或复用这些必须的接口。
(2)实现或复用接口
我们先来看一个最“究极”的复用,就是我们平时用的Hive Connector,如果你留意了会发现,我们平时用的Hive Connector在配置文件里其实是这么配置的:
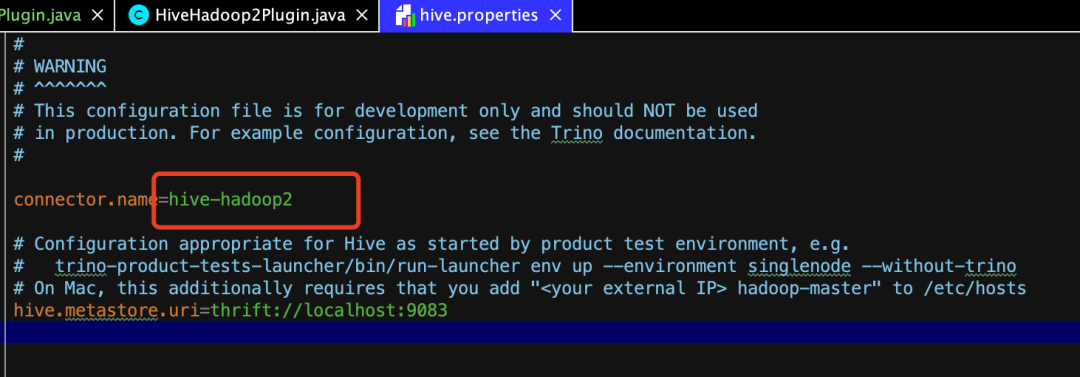
没错,就是hive-hadoop2,所以其实这个Connector是由下图所示的presto-hive-hadoop2来提供的。
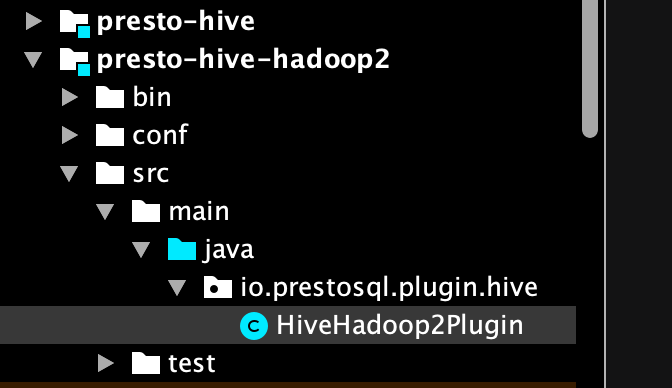
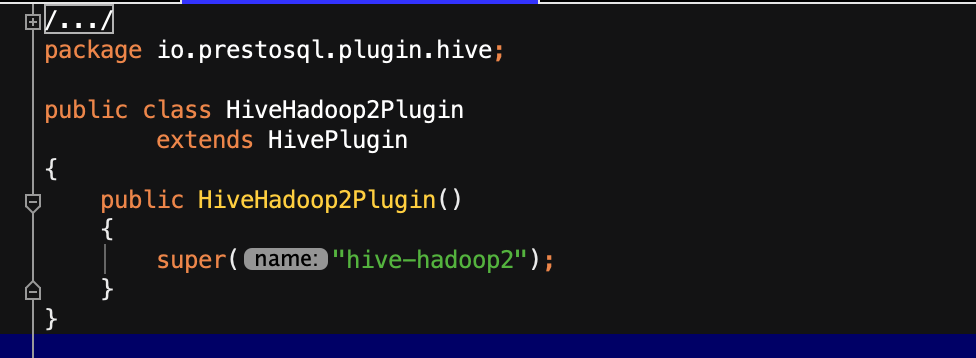
再继续看他的代码,只有这么一行有效内容,就是super("hive-hadoop2"),没错,他就自己完成了一件事,定义这个connector的名字,那其他所有的工作是谁来做的呢?我们可以看到,他继承了HivePlugin,所以,其他所有的工作都是靠presto-hive模块来完成的。
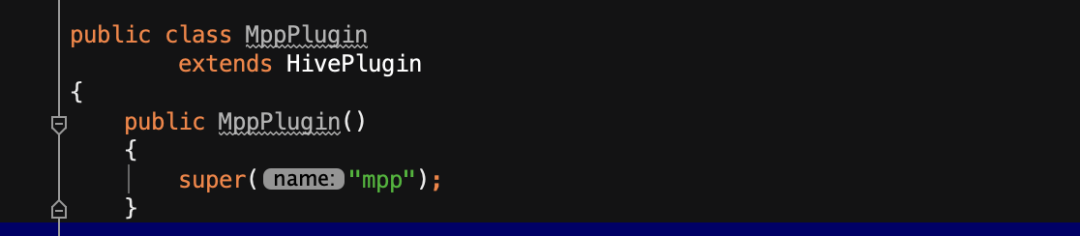
那到这里我们就恍然大悟了,我直接自定义一个,我也可以创建一个类Hive Connector了,比如下图,我就轻轻松松创建了一个mpp的connector,实现了读取Hive表的所有功能。
如果到这里就结束了,那他就只是个hive connector而已。如果你想要自定义里面的一些逻辑该怎么办呢?比如我想重新定义里面的数据分片逻辑?那我们就要重写这个逻辑了。
下面我们以重写数据分片逻辑为例,讲一下如何添加自定义功能。
(3)自定义分片逻辑
我们先看一下Hive的分片逻辑实现是在哪个类里?通过功能我们也大体能搜到这个相关类,就是HiveSplitManager.java,这个类中的getSplits方法就定义了如何去读取hive表的数据文件,有哪些partition,需要分成多少个split等。加入我们想自定义分片逻辑,我们应该怎么做呢?
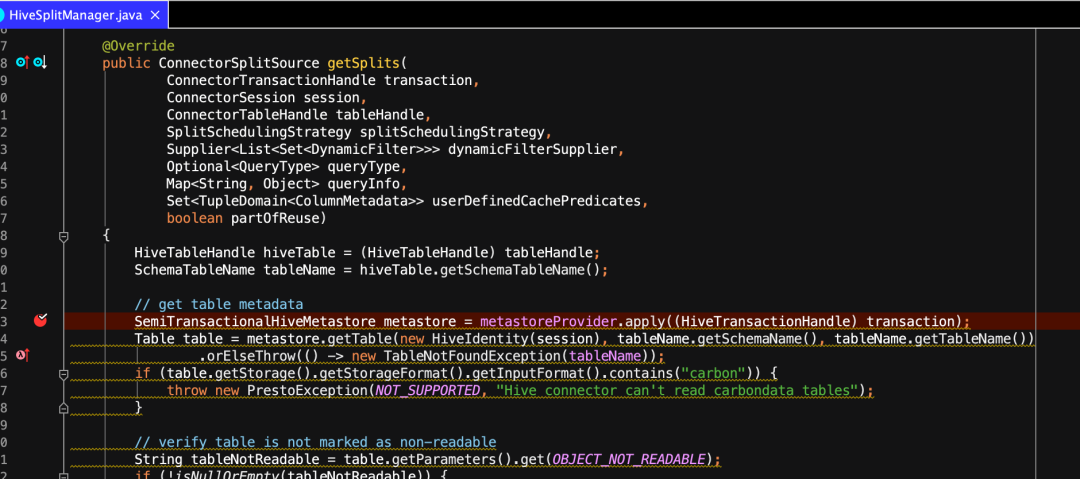
我们可以自己创建一个MppSplitManager.java,一种方式是实现ConnectorSplitManager接口,但是为了求同存异,即复用之前hive已存在的功能,又添加自定义的逻辑,我们就可以继承HiveSplitManager这个类,然后重写getSplits方法。
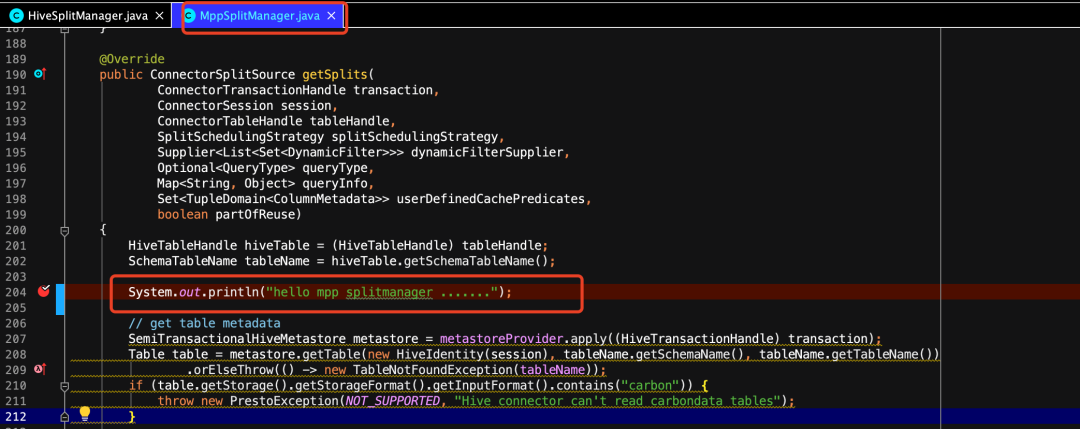
这里我只是简单的增加了一个自定义输出,如果我们有其他的逻辑可以尽情在这里添加即可,比如你可以通过tableName拿到schemaName和tableName,如果你检测到tableName是一些白名单的表,可以对这些表做一些特定的处理,等等等等。
那这样就完了么?如果这样编译完成,依然不会生效,因为引擎并没有对你写的这个类进行实例化并绑定到MppConnector的ConnectorSplitManager实现中,这是你要通过MppModule来绑定你的这个类的实现,这样引擎在进行plugin加载的时候,就会采用你的这个实现了,如下所示。
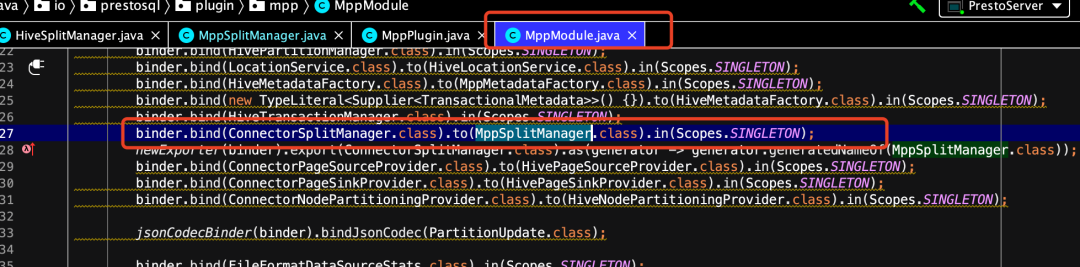
4.总结
以上我们就完成了新建一个Connector并复用已有Connector的功能。当然了,如果你想自定义Hive Connector的Metadata信息,你也可以按照相同的方法来重新实现HiveMetadata。这样我们其实就把Hive Connector变成了JDBC系列Connector了,JDBC系列的Mysql、Oracle等都是通过类似的方式去实现的。这一块的实现案例我放在Gitee上我fork的openLooKeng的hetu-core代码的mppdev分支了。
https://gitee.com/doubledue/hetu-core/tree/mppdev/
更多的内部机制,我们以后有机会继续介绍。
