




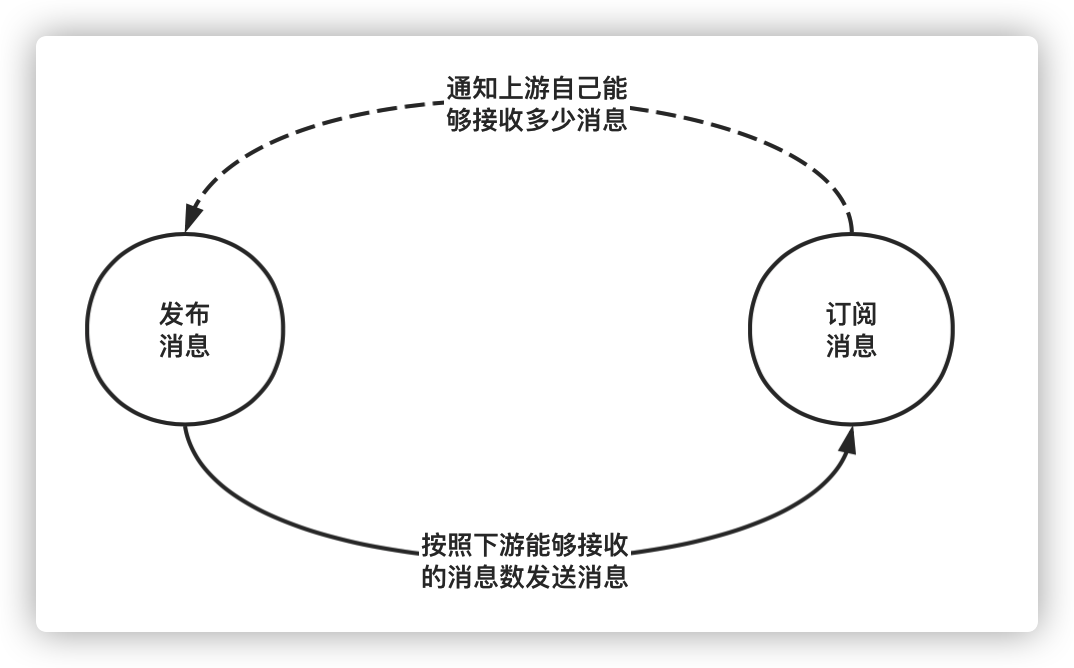
一、反压机制简介
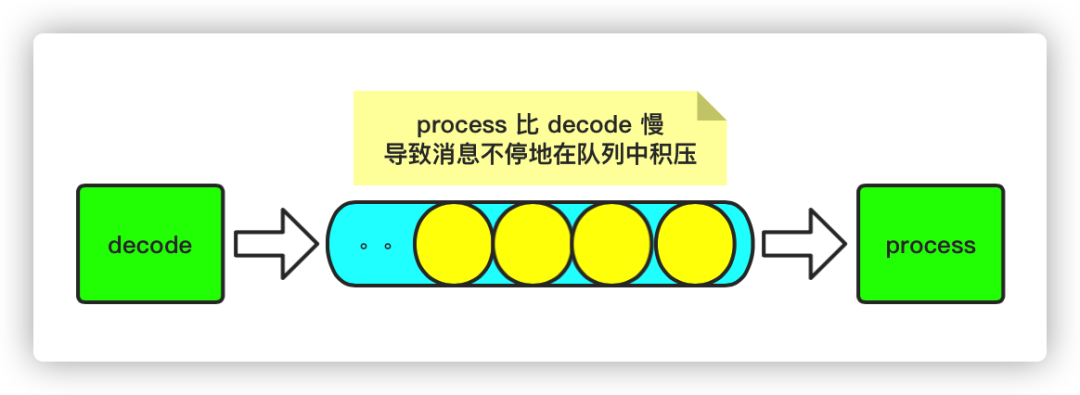
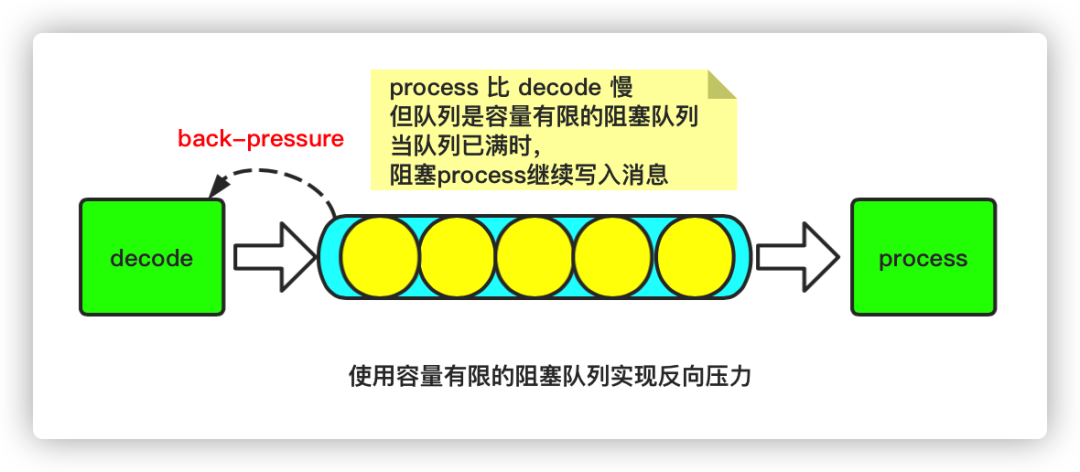
其一是,执行器的任务队列,它的容量必须是有限的。(队列有容量限制)
其二是,当执行器的任务队列已经满了时,就阻止上游继续提交新的任务,直到任务队列重新有新的空间可用为止。(队列是阻塞的)
二、PID算法简介
将需要控制的物理量带到目标附近(比如48℃) “预见”这个量的变化趋势(热水器余热会继续提高水温) 消除因为散热、阻力等因素造成的静态误差
当两者差距不大时,只需 "稍微加热" 即可 当两者差距较大时,就让热水器 "开足马力" ,尽快加热到目标值附近
对于P,已经控制和目标温度接近了,只需稍微加热即可 对于D,加热和散热速率一致,温度没有波动,并不需要D进行调节
val untilOffsets = clamp(latestOffsets())复制
返回每个分区最大的 offset 用于动态发现新加入的分区
/*** Returns the latest (highest) available offsets, taking new partitions into account.* 1.获取每个分区的最大offset* 2.用于动态感知新加入的分区*/protected def latestOffsets(): Map[TopicPartition, Long] = {...}复制
//限制每个分区处理的最大消息条数不超过kafka分区里的最大offsetprotected def clamp(offsets: Map[TopicPartition, Long]): Map[TopicPartition, Long] = {maxMessagesPerPartition(offsets).map { mmp =>mmp.map { case (tp, messages) =>//Kafka每个分区的最大offsetval uo = offsets(tp)//限制每个分区可以消费的最大offset不超过实际的最大offsettp -> Math.min(currentOffsets(tp) + messages, uo)}}.getOrElse(offsets)}复制
protected[streaming] def maxMessagesPerPartition(offsets: Map[TopicPartition, Long]): Option[Map[TopicPartition, Long]] = {//预估的消费Rateval estimatedRateLimit = rateController.map { x => {//获取最后一次PID计算器算出的Rate,是一个消息数量val lr = x.getLatestRate()//如果没有Rate,直接返回spark.streaming.kafka.maxRatePerPartition参数设置的最大rateif (lr > 0) lr else initialRate}}// calculate a per-partition rate limit based on current lag//根据当前延迟计算每个分区的速率限制(TopicPartition,Double)val effectiveRateLimitPerPartition = estimatedRateLimit.filter(_ > 0) match {case Some(rate) =>//获取每个分区还未消费的数据量,即最大offset-当前消费offset的值val lagPerPartition = offsets.map { case (tp, offset) =>tp -> Math.max(offset - currentOffsets(tp), 0)}//计算所有分区未消费的数据总量val totalLag = lagPerPartition.values.sumlagPerPartition.map { case (tp, lag) =>//每个分区消费的最大条数val maxRateLimitPerPartition = ppc.maxRatePerPartition(tp)//计算反压速率:单个分区未消费的数据量/所有分区未消费数据量总和 * 比率val backpressureRate = lag totalLag.toDouble * rate//确定该分区消费的反压速率://如果设置了spark.streaming.kafka.maxRatePerPartition > 0,计算的最大rate不能超过该值。//如果没有设置,则直接采用反压速率backpressureRatetp -> (if (maxRateLimitPerPartition > 0) {Math.min(backpressureRate, maxRateLimitPerPartition)} else backpressureRate)}case None => offsets.map { case (tp, offset) => tp -> ppc.maxRatePerPartition(tp).toDouble }}if (effectiveRateLimitPerPartition.values.sum > 0) {//每个计算批次的时间间隔,单位秒val secsPerBatch = context.graph.batchDuration.milliseconds.toDouble 1000Some(effectiveRateLimitPerPartition.map {//每个分区的限制比率*时间区间就是本批次消费的数据量case (tp, limit) => tp -> Math.max((secsPerBatch * limit).toLong,ppc.minRatePerPartition(tp))})} else {None}}复制
计算每个分区滞后消费的数据量:lagPerPartition 计算所有分区滞后消费的总数据量:totalLag 计算每个分区反压的速率:backpressureRate = lag totalLag.toDouble * rate,这里的rate就是之前通过PID计算器算出的Rate,即 rateLimit 变量的值 如果设置了spark.streaming.kafka.maxRatePerPartition > 0,计算的最大rate不能超过该值。如果没有设置,则直接采用反压速率backpressureRate 将计算批次batch的时间间隔转化为s,并且乘以前面算出的速率,得到每个分区本次消费的数据量。
则每个分区直接返回 spark.streaming.kafka.maxRatePerPartition 参数设置的最大rate
override protected[streaming] val rateController: Option[RateController] = {if (RateController.isBackPressureEnabled(ssc.conf)) {Some(new DirectKafkaRateController(id,RateEstimator.create(ssc.conf, context.graph.batchDuration)))} else {None}}复制
PIDRateEstimator是获取当前这个结束的batch的数据,然后估计下一个batch的rate(注意,下一个batch并不一定跟当前结束的batch是连续两个batch,可能会有积压未处理的batch) PID计算出的速率是针对所有分区的,而不是单个分区
time -> 处理结束时间 batchCompleted.batchInfo.processingEndTime numElements -> 消息数elements.get(streamUID).map(_.numRecords) processingDelay ->处理时间 batchCompleted.batchInfo.processingDelay schedulingDelay -> 调度延迟 batchCompleted.batchInfo.schedulingDelay
/**** @param time 这个batch处理结束的时间* @param numElements 这个batch处理的消息条数* @param processingDelay 这个job在实际计算阶段花的时间(不算调度延迟)* @param schedulingDelay 这个job花在调度队列里的时间* @return*/def compute(time: Long, // in millisecondsnumElements: Long,processingDelay: Long, // in millisecondsschedulingDelay: Long // in milliseconds): Option[Double] = {this.synchronized {if (time > latestTime && numElements > 0 && processingDelay > 0) {//计算批次的实际处理时间间隔,单位秒val delaySinceUpdate = (time - latestTime).toDouble 1000//实际处理速度val processingRate = numElements.toDouble processingDelay * 1000//计算误差:预估处理速度-实际的处理速度,这个结果就是PID中P系数要乘的值//latestRate是PID为刚刚结束的batch,在生成这个batch时预估的处理速度//processingRate 是刚刚结束的batch实际的处理速度val error = latestRate - processingRate//计算积分:调度延时 * 每秒处理的速率 批次间隔,得到的值可以认为是之后每秒要多消费多少数据才可以弥补延时带来的时间误差val historicalError = schedulingDelay.toDouble * processingRate batchIntervalMillis//计算微分:val dError = (error - latestError) delaySinceUpdate//计算新的速率:proportional为修正系数val newRate = (latestRate - proportional * error -integral * historicalError -derivative * dError).max(minRate)//更新latestTimelatestTime = time//如果是第一次使用PID计算if (firstRun) {latestRate = processingRatelatestError = 0DfirstRun = falselogTrace("First run, rate estimation skipped")None} else {//更新latestRatelatestRate = newRate//更新latestErrorlatestError = errorlogTrace(s"New rate = $newRate")Some(newRate)}} else {logTrace("Rate estimation skipped")None}}复制
该方法有以下几个关键步骤:
计算速率差值:预估处理速度 - 实际的处理速度,这个结果就是PID中P系数要乘的值
val error = latestRate - processingRate复制
计算积分:调度延时 * 每秒处理的速率 批次间隔,得到的值可以认为是之后每秒要多消费多少数据才可以弥补延时带来的时间误差
val historicalError = schedulingDelay.toDouble * processingRate batchIntervalMillis复制
计算微分:
val dError = (error - latestError) / delaySinceUpdate复制
计算新的速率:可以看到,这里就用到了上面算出的三个系数
val newRate = (latestRate - proportional * error -integral * historicalError -derivative * dError).max(minRate)复制
那么,什么时候 error 为 0,什么时候 PID 的输出为 0 呢?
当 latestRate = processingRate 时,error 为 0,即预估的速率和实际的速率一致。由于latestRate实际上等于numElements / batchDuration,因为numElements是上次生成job时根据这个latestRate(也就是当时的estimatedRate)算出来的,而 processingRate = numElements / processingDelay,所以可以得到,当 processingDelay = batchDuration 时,error 为 0.
当 error 为 0 时,PID 的输出不一定为 0.因为要考虑历史误差,这里刚结束的batch可能并非生成后就立即被执行,而是在调度队列里排了一会队,所以还是需要考虑 schedulingDelay。
当PID输出为0时,newRate 就等于 latestRate,此时系统达到了稳定状态,error=0,historicalError=0 且 dError= 0。此时意味着:
没有 schedulingDelay,意味着job等待被调度的时间为0. 如果没有累积的未执行的job,那么schedulingDelay 大致等于0.
error为零,意味着 batchDuration 等于processingDelay
dError为零,在 error 等于 0 时,意味着上一次计算的 error 也为零。
这就是backpressure想要系统达到的状态。
开启反压:spark.streaming.backpressure.enabled=true设置每秒从kafka分区中拉取的最大数据条数spark.streaming.kafka.maxRatePerPartition=xxxx启用反压机制时每个接收器接收第一批数据的初始最大速率spark.streaming.backpressure.initialRate可以估算的最低速率。默认值为 100,只能设置为0或者大于0的数spark.streaming.backpressure.pid.minRate错误积累的响应权重,具有抑制作用(有效阻尼)。默认值为 0.2只能设置为0或者大于0的数spark.streaming.backpressure.pid.integral对错误趋势的响应权重。这可能会引起 batch size 的波动,可以帮助快速增加/减少容量。默认值为0.0,只能设置为0或者大于0的数spark.streaming.backpressure.pid.derived用于响应错误的权重。默认值为1.0,只能设置为0或者大于0的数spark.streaming.backpressure.pid.proportional复制
评论

 0 点赞
0 点赞