




今天被问到一个问题,通过 left join 对两个表做关联查询,结果中数据量为何比左表的数据量少?按理说数据量应该和左表保持一致呀。看了一下 SQL,大概逻辑如下:
selecta.XX,...,b.XXfrom aleft join bon a.id=b.object_idwhere a.data_date=20210323and b.data_date=20210323复制
create table dept(dept_id int not null AUTO_INCREMENT PRIMARY KEY comment '部门编号',dept_name varchar(10) not null default '' comment '部门名称') comment '部门表';create table emp(id int not null AUTO_INCREMENT PRIMARY KEY comment '员工编号',name varchar(10) not null default '' comment '姓名',dept_id int not null default 0 comment '所在部门编号') comment '员⼯表';insert into dept values (1,'财务部'),(2,'销售部'),(3,'研发部'),(4,'后勤部');insert into emp values (1,'张三',2),(2,'李四',2),(3,'王五',3),(4,'赵六',0),(5,'旺财',0);复制
当执行如下语句时,结果如下图:
select a.*,b.* from emp a left join dept bon a.dept_id =b.dept_id复制
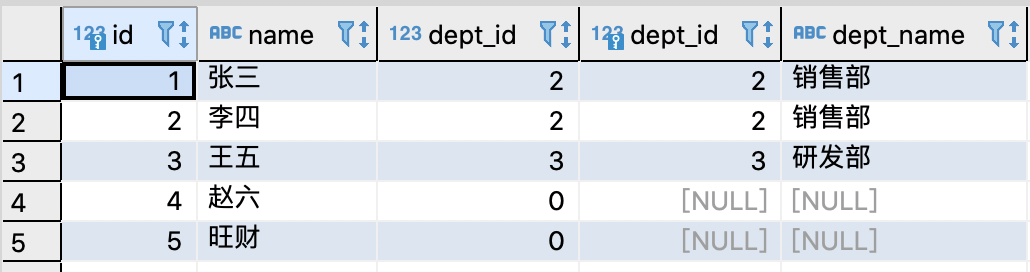
如果加上 ' and a.dept_id = 2 ',结果如下:
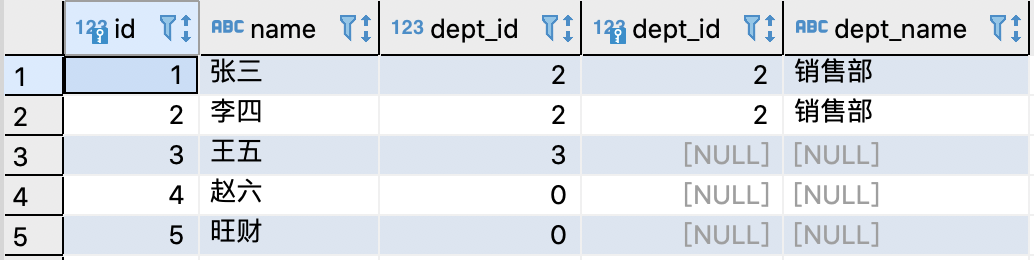
可见结果还是以左表为准,只是右边除了 dept_id = 2 的数据,其余都用 NULL 补齐了

此时结果就比左表数据要少了。
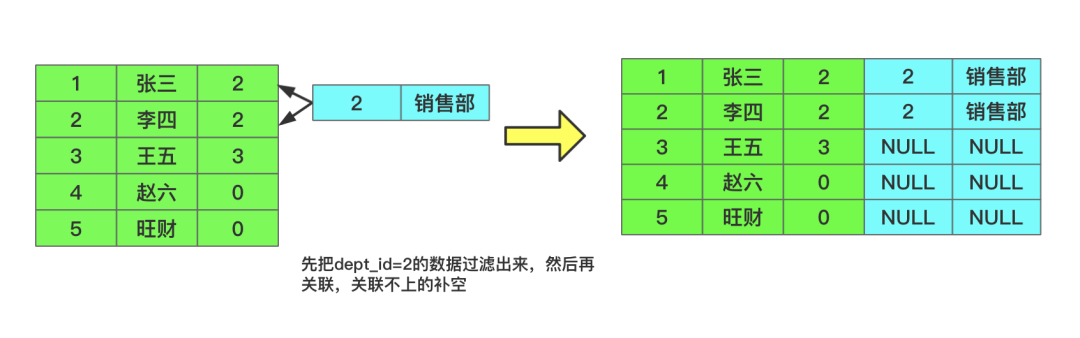
通过 where 过滤的原理如下:

文章转载自大数据记事本,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
Mr.Cui

1年前
评论
 1
1
1年前
1 评论
11 0

1年前
评论
0👍
1年前
点赞 评论
chengang
1年前
评论
1这个其实用show warnings 看。可以看到优化器已经给你改写成了inner join
1年前
1 评论
胡敏

1年前
评论
1既然不能阻止皱纹爬上额头,便阻止皱纹爬上心头吧。
1年前
1 评论
筱悦星辰

2年前
评论
1既然不能阻止皱纹爬上额头,便阻止皱纹爬上心头吧。
2年前
1 评论
helloword

2年前
评论
1不错不错
2年前
1 评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
2474次阅读
2025-04-09 15:33:27
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1141次阅读
2025-04-27 16:53:22
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
820次阅读
2025-04-10 15:35:48
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
649次阅读
2025-04-30 15:24:06
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
568次阅读
2025-04-11 09:38:42
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
549次阅读
2025-04-10 12:32:35
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
530次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
456次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
453次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
441次阅读
2025-04-30 12:17:50
