




Linux中的HugePage对数据库服务来说为什么如此重要:以PG为例
用户经常因为OOM killer造成数据库崩溃问题来找我们寻求帮助。Out Of Memory killer会杀死PG进程,并且是我们遇到的数据库崩溃问题中首要原因。主机内存不足的原因可能有多种,最常见的有:
1) 主机上内存调整不佳
2) work_mem值全局指定过高(实例级别)。用户经常低估这种设置带来的影响
3) 连接数过高。用户忽略了一个事实,即使非活动连接也可以保留大量内存分配
4) 在同一台机器上共同托管的其他程序的资源消耗。
尽管我们曾协助调优主机和数据库,但很少花时间解释HugePage的重要性,并用数据证明它的合理性。多亏了我的朋友及同事Fernando进行反复实验,这次我忍不住这么做了。
问题
让我用一个可测试和可重复的案例解释这个问题。如果有人想以自己的方式测试案例,这可能会有所帮助。
测试环境
测试机配40个CPU内核(80个vCPU)和192GB内存。我不想用太多连接使这个服务器过载,所以只使用了80个连接进行测试。透明HugePage(THP)已禁用,此处不过多解释为什么将THP用于数据库服务器不是一个好主意。
为持有相对持久的连接,使用pgBouncer进行80个连接。以下是其配置:
[databases]sbtest2 = host=localhost port=5432 dbname=sbtest2[pgbouncer]listen_port = 6432listen_addr = *auth_type = md5auth_file = /etc/pgbouncer/userlist.txtlogfile = /tmp/pgbouncer.logpidfile = /tmp/pgbouncer.pidadmin_users = postgresdefault_pool_size=100min_pool_size=80server_lifetime=432000复制
正如我们看到的,server_lifetime参数指定一个较高的值,从而不破坏池化器到PG的连接。下面是PG的参数:
logging_collector = 'on'max_connections = '1000'work_mem = '32MB'checkpoint_timeout = '30min'checkpoint_completion_target = '0.92'shared_buffers = '138GB'shared_preload_libraries = 'pg_stat_statements'复制
使用sysbench进行测试负载:
sysbench /usr/share/sysbench/oltp_point_select.lua --db-driver=pgsql --pgsql-host=localhost --pgsql-port=6432 --pgsql-db=sbtest2 --pgsql-user=postgres --pgsql-password=vagrant --threads=80 --report-interval=1 --tables=100 --table-size=37000000 prepare
然后:
sysbench /usr/share/sysbench/oltp_point_select.lua --db-driver=pgsql --pgsql-host=localhost --pgsql-port=6432 --pgsql-db=sbtest2 --pgsql-user=postgres --pgsql-password=vagrant --threads=80 --report-interval=1 --time=86400 --tables=80 --table-size=37000000 run
第一个prepare阶段使用一个写负载,第二个是只读负载。
此处不专注解释HugePage背后的理论和概念,而是专注于影响分析。参考https://lwn.net/Articles/717293/和https://blog.anarazel.de/2020/10/07/measuring-the-memory-overhead-of-a-postgres-connection/理解一些概念。
测试观察
测试期间使用free命令检查内存消耗。在使用行规内存页池时,消耗量从非常低的值开始。但它一直在稳步增长。“可用”内存以更快的速度耗尽。
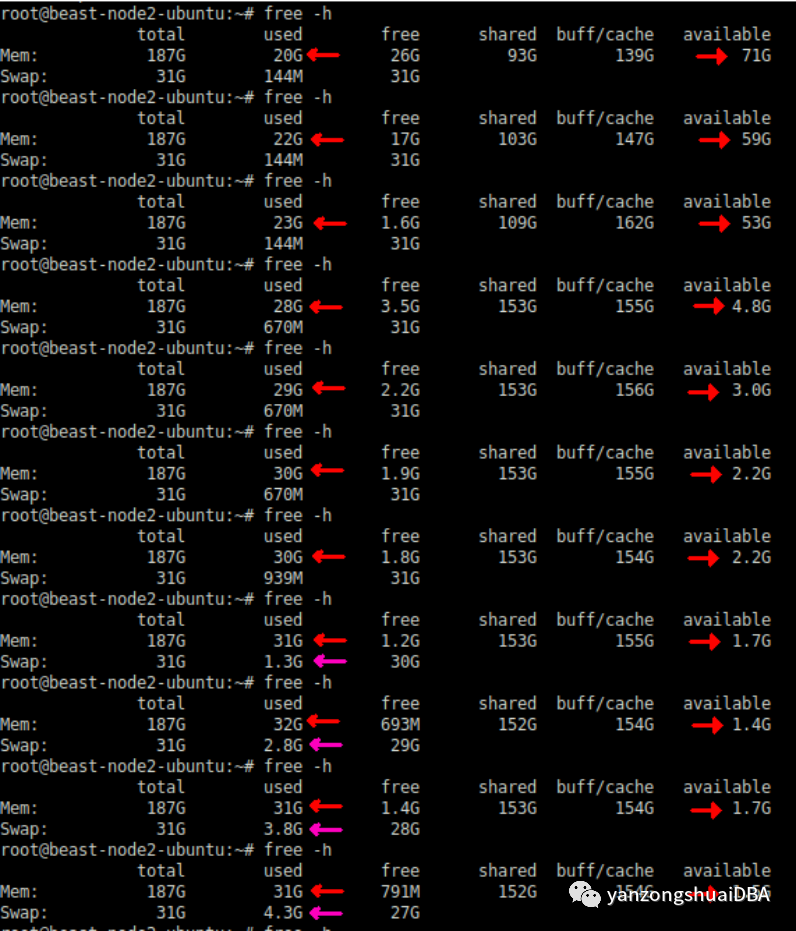
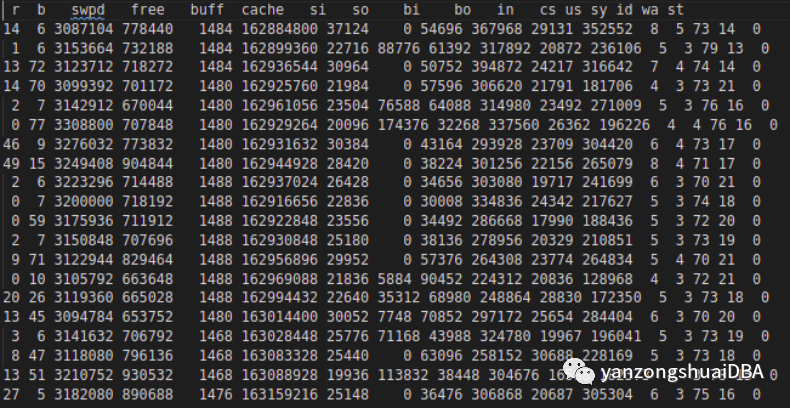
最后他开始使用swap。使用vmstat采集swap活动:
/proc/meminfo的信息显示总页表大小从最初的45MB增长到25+GB
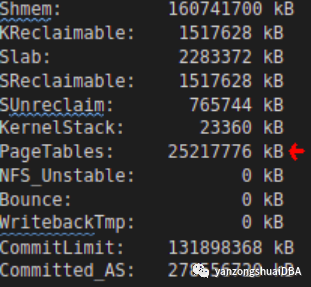
这不仅是内存浪费,也是一个巨大的开销,会影响程序和操作系统的整体执行。这个是80多个PG进程的Total of Lower PageTable entries 大小。
同样可以通过检查每个PG进程来验证。以下是一个示例:

这个值*80(个连接)大概是25GB,即PageTable总大小。由于此综合基准测试通过所有连接发送几乎相近的工作负载,因此所有单个进程的值都和上面获取的值非常接近。
下面的shell命令可以用于检查Pss(单个进程在系统总内存种实际使用量的比例)。由于PG使用共享内存,因此专注Rss没有意义。
for PID in $(pgrep "postgres|postmaster") ; do awk '/Pss/ {PSS+=$2} END{getline cmd < "/proc/'$PID'/cmdline"; sub("\0", " ", cmd);printf "%.0f --> %s (%s)\n", PSS, cmd, '$PID'}' /proc/$PID/smaps ; done|sort -n复制
如果没有 Pss 信息,就没有简单的方法来了解每个进程的内存职责。
在一个相当大的DML负载的数据库系统种,PG的后台进程如Checkpointer、Background Writer 或 Autovaccum worker将接触共享内存中更多页面,对于这些进程相应的Pss会更高。
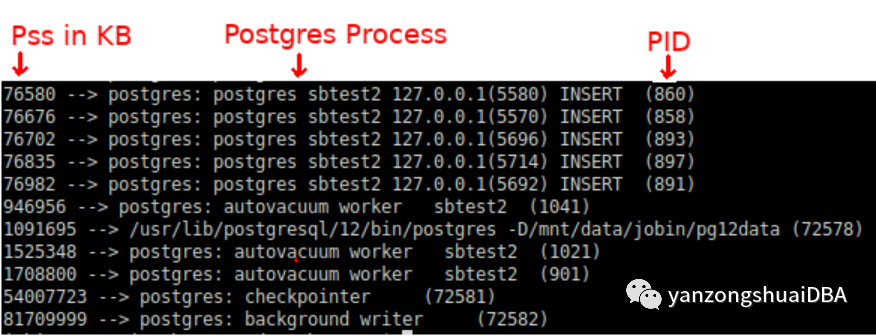
这里应该可以解释为什么Checkpointer, Background worker,甚至 Postmaster进程成为OOM Killer的目标。正如上面看到的,他们承担这共享内存的最大责任。
经过几个小时的执行,单个会话接触了更多共享内存页面。Pss值重排,由于其他会话分担责任,因此checkpointer负负责的更少:
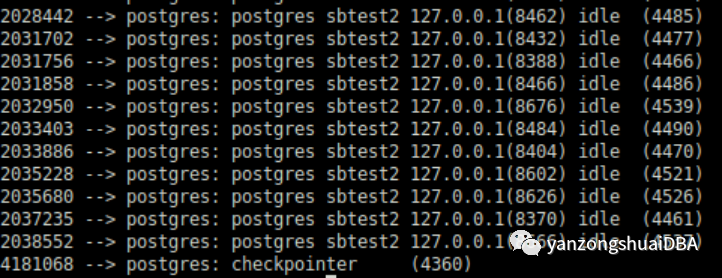
但是,checkpointer保留了最高的份额。
由于每个会话都完成几乎相同工作,这种测试是一种特定的负载模式。这不是一个典型的应用程序负载的一个很好的近似值。我们通常看到 checkpointer和background writers承担主要责任。
解决方案:启用HugePage
这种臃肿的页表和相关问题的解决方案是使用HugePages。可以通过查看PG进程的VmPeak来计算出应该为HugePage分配多少内存。例如若4357是PG的PID:
grep ^VmPeak /proc/4357/statusVmPeak: 148392404 kB复制
这里给出了需要的内存大小。将其转换2MB的页面得到大页个数:
postgres=# select 148392404/1024/2;?column?----------72457(1 row)复制
在/etc/sysctl.conf中指定这个值到vm.nr_hugepages:
vm.nr_hugepages = 72457
现在关闭PG实例并执行:
sysctl -p
验证是否创建了请求数量的大页:
grep ^Huge /proc/meminfoHugePages_Total: 72457HugePages_Free: 72457HugePages_Rsvd: 0HugePages_Surp: 0Hugepagesize: 2048 kBHugetlb: 148391936 kB复制
如果这个阶段启动PG,可以看到分配了HugePages_Rsvd :
$ grep ^Huge /proc/meminfoHugePages_Total: 72457HugePages_Free: 70919HugePages_Rsvd: 70833HugePages_Surp: 0Hugepagesize: 2048 kBHugetlb: 148391936 kB复制
如果一切正常,我们更愿意PG始终使用HugePage,而不是等到以后出现问题/崩溃。
postgres=# ALTER SYSTEM SET huge_pages = on;复制
需要重启使之生效。
使用HugePage “ON”进行测试
在PG启动前创建好HugePages。PG只是分配并使用他们。所以启动前后free结果不会有变化。如果他们已经可用,PG会将其共享内存分配到这些HugePage中。PG的shared_buffers是共享内存的最大占用者。
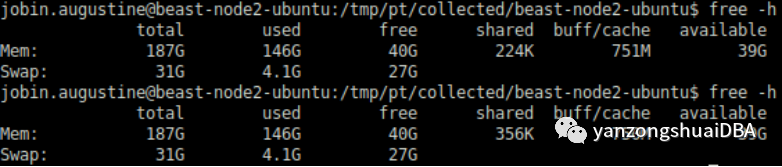
上图中第一个free -h是PG启动前结果,第二个free -h是启动后。正如看到的,没有明显变化。
我做了同样的测试,运行几个小时,没有任何变化。即使经过数小时运行,唯一明显变化的是将“空闲”内存转移到文件系统缓存。这是预期的,也是我们相应实现的。正如下图所示,总的“可用”内存几乎保持不变。
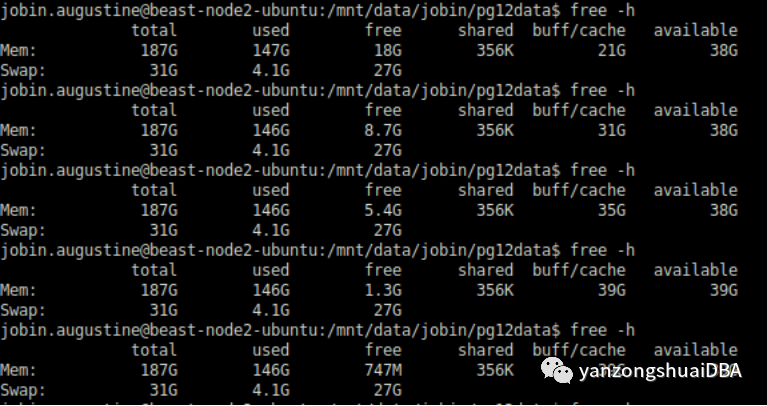
总页表大小几乎保持不变:

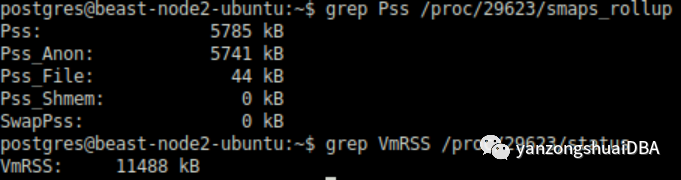
此时看到,HuagePages仅为61MB,而不是之前的25+GB。每个会话的Pss也大幅减少:
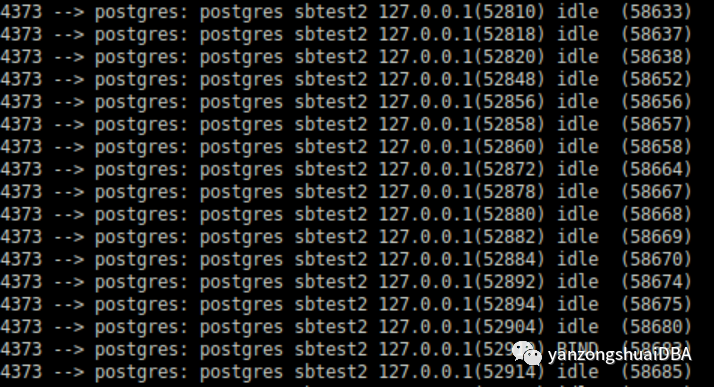
我们可以看到最大的优势是 CheckPointer 或 Background Writer不再占几个GB的RAM。仅有几MB的消耗,显然他们不再是OOM Killer的的候选受害者。
结论
本文讨论了Linux HugePage如何潜在地从OOM Killer和相关崩溃中拯救数据库服务。可以看到有2个改进:
1) 整体内存消耗大幅减少。如果没有HugePages,服务器几乎耗尽内存(可用内存完全耗完,开始swap)。然而一旦切换到HugePages,会有38-39GB的可用内存。节省很大
2) 启用HugePages后,PG后台进程不会占用大量共享内存。所以他们不会轻易地成为OOM Killer的受害者
如果系统处于OOM的边缘,这些改进可能会挽救系统。但并不是说用于保护数据库免受所有OOM的影响。
HugePages最初于2002年用到Linux内核,用于解决需要处理大量内存的数据库系统需求。可以看到整个设计目标仍然有效。
使用HugePages的其他间接好处:
1) HugePages永远不会被换掉。当PG共享缓冲区在HugePages中时,它可以产生更一致和可预测的性能。将在另一篇文章中讨论。
2) Linux使用多级页面查找方法。HugePages使用来自中间层的直接指向页面的指针实现的(2MB的大页面将直接在PMD级别找到,没有中间的PTE页面)。地址转换也相当简单。由于这是数据库中高频操作,所以收益成倍增加。
注意:本文中讨论的HugePages是关于固定大小(2MB)的巨页。此外,作为旁注,我想提一下,多年来透明 HugePages (THP)有很多改进,允许应用程序使用 HugePages 而无需任何代码修改。THP 通常被认为是通用工作负载的常规 HugePages (hugetlbfs) 的替代品。但是,不鼓励在数据库系统上使用 THP,因为它会导致内存碎片和延迟增加。我想在另一篇文章中讨论这个主题,只是想提到这些不是 PostgreSQL 特定的问题,而是影响每个数据库系统。例如:
1) Oracle 建议禁用 TPH。参考
https://docs.oracle.com/en/database/oracle/oracle-database/19/ladbi/disabling-transparent-hugepages.html#GUID-02E9147D-D565-4AF8-B12A-8E6E9F74BEEA
2) MongoDB 建议禁用 THP。参考
https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/
3) “众所周知,对于某些 Linux 版本的某些用户,THP 会导致 PostgreSQL 性能下降。” 参考https://www.postgresql.org/docs/current/runtime-config-resource.html
原文
https://www.percona.com/blog/why-linux-hugepages-are-super-important-for-database-servers-a-case-with-postgresql/





