




点亮Star⭐️支持我们: https://github.com/apache/seatunnel

#01 安装
Java 运行环境jdk8 下载解压seatunnel
修改配置,配置需要用到的插件
config/plugin_config复制
更新安装插件
sh bin/install-plugin.sh 2.3.2复制
#02 功能说明
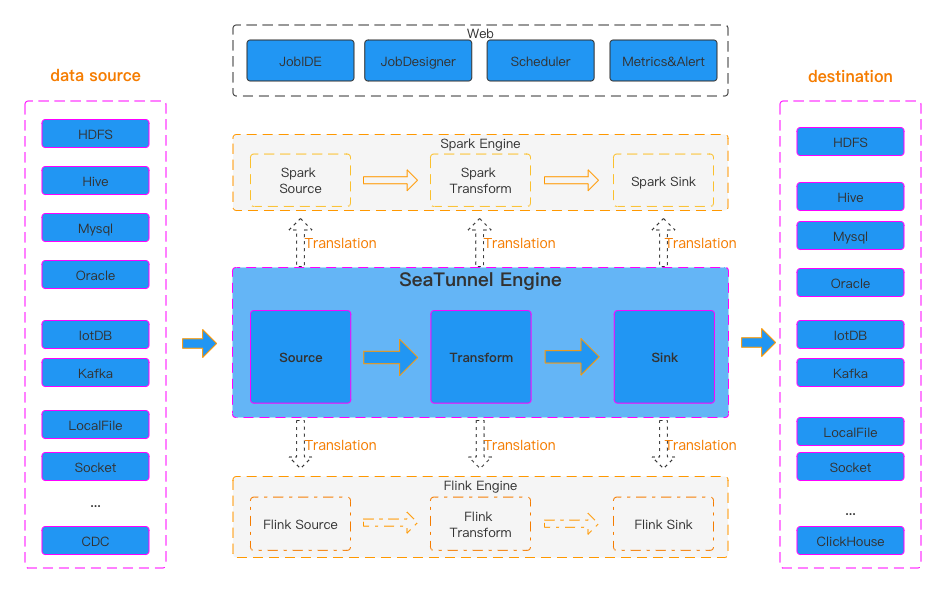
#03 功能数据同步应用
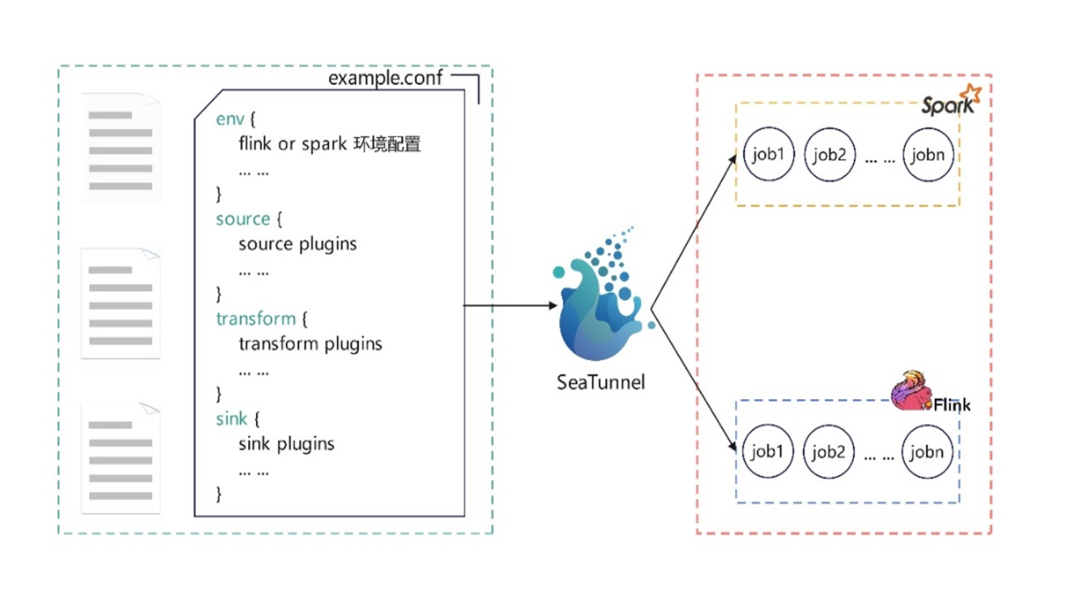
启动Zeta集群
停用Zeta集群
数据导入Csv->Starrocks
env {execution.parallelism = 2job.mode = "BATCH"checkpoint.interval = 10000}source {LocalFile {delimiter = ","schema {fields {id = intname = stringage = stringstatus = int}}path = "/data/seatunnel/demo1"file_format_type = "csv"}}sink {StarRocks {nodeUrls = ["192.0.0.2:8030"]base-url = "jdbc:mysql://192.0.0.2:9030"username = rootpassword = "*****"database = "dataplat"table = "t_jdbc_test"batch_max_rows = 10schema {fields {id = intname = stringage = stringstatus = int}}}}复制
./bin/seatunnel.sh --config ./config/v2.batch.config.sr -e local复制
./bin/seatunnel.sh --config ./config/v2.batch.config.sr -e cluster复制
数据同步Kafka->Starrocks
复制
env {# You can set SeaTunnel environment configuration hereexecution.parallelism = 2job.mode = "BATCH"checkpoint.interval = 10000#execution.checkpoint.interval = 10000#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint "}source {Kafka {result_table_name = "kafka_test"schema = {fields {id = intname = stringage = stringstatus = int}}format = textfield_delimiter = "#"topic = "topic3"bootstrap.servers = "192.0.0.1:9092"kafka.config = {client.id = client_1auto.offset.reset = "earliest"enable.auto.commit = "false"}}}sink {StarRocks {nodeUrls = ["192.0.0.2:8030"]base-url = "jdbc:mysql://192.0.0.2:9030"username = rootpassword = "******************"database = "dataplat"table = "t_jdbc_test"batch_max_rows = 10schema {fields {id = intname = stringage = stringstatus = int}}}}复制
bin/start-seatunnel-flink-15-connector-v2.sh -c config/v2.batch.config.sr.kafka复制
bin/start-seatunnel-flink-15-connector-v2.sh -m 192.1.1.3:8081 -c config/v2.batch.config.sr.kafka复制
bin/start-seatunnel-spark-3-connector-v2.sh --master local --deploy-mode client -c config/v2.batch.config.sr.kafka复制
bin/start-seatunnel-spark-3-connector-v2.sh -m spark://192.1.1.3:7077 -c --deploy-mode client config/v2.batch.config.sr.kafka复制
#04 seatunnel-web 安装
首先需要安装DS
"Security" -> "Tenant Manage" -> "Create Tenant"Create Project for SeaTunnel WebCreate Token for SeaTunnel Web复制
安装web
cd seatunnel-web-mainsh build.sh codeunzip apache-seatunnel-web-incubating-1.0.0-SNAPSHOT.zip编辑 seatunnel_server_env.sh 配置mysql元数据信息 sh init_sql.sh编辑数据库连接和ds连接: /data/seatunnel-web-main/conf/application.yml启动 sh bin/seatunnel-backend-daemon.sh start
Apache SeaTunnel
精彩推荐
点击阅读原文,点亮Star⭐️!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
史诗级革新 | Apache Flink 2.0 正式发布
严少安
133次阅读
2025-03-25 00:55:05
Apache Iceberg 解析,一文了解Iceberg定义、应用及未来发展
镜舟科技
32次阅读
2025-03-26 22:25:28
写Oracle表耗时25分钟缩短到23秒——SeaTunnel性能优化
SeaTunnel
23次阅读
2025-03-05 11:08:39
如何通过 Apache SeaTunnel 实现 MySQL 到 OceanBase的数据迁移同步
SeaTunnel
21次阅读
2025-03-20 09:50:27
Apache Doris vs Elasticsearch:深入对比分析
数据微光
19次阅读
2025-03-24 09:42:38
2025年开源世界:系好安全带,颠覆即将来临!
海豚调度
17次阅读
2025-03-13 09:51:52
@大数据工程师 Apache SeaTunnel Community Call 会议通知
SeaTunnel
16次阅读
2025-03-12 10:23:07
【用户投稿】手把手基于Apache SeaTunnel从PostgreSQL同步到Doris
SeaTunnel
14次阅读
2025-03-13 09:51:51
Doris 数据库更新指南:高效与灵活的完美结合
数据极客圈
13次阅读
2025-03-28 15:02:42
【用户投稿】Apache SeaTunnel脚本升级及参数调优实战
SeaTunnel
12次阅读
2025-03-21 10:33:43



