




近期主机文件系统故障,且主机侧无法修复文件系统只能重做。主机实例也因长期宕停 gcware 的状态从 close 变成了 offline。综合以上因素需要在原主机做备机替换。
关于 gcware 的状态从 close 变成了 offline 的原因,根据这次现场遇到的情况只能推断可能是 close 的时间太长,或者文件系统重做导致的。
确认备机替换后,需要将备机替换的主机 gcware 状态设置为 unavailable 状态,此状态主机无法恢复只能做备机替换。同时设置为此状态后集群 event 不会再增长。
gcadmin setnodestate 1.1.1.1 unavailable
然后再删除 event,命令后面的 ip 必须是 gcadmin 看到的 ip
gcadmin rmddlevent 2 ip
gcadmin rmdmlevent 2 ip
gcadmin rmdmlstorageevent 2 ip
以上的步骤建议提前做如果 event 过多的话,删除会很长时间。这边 ddl 和 dml 一共十几万 删了四五个小时。
再到 gc 节点的 gcinstall 目录下执行命令
./replace.py --host = 备机 ip --rootPwd='root 用户密码' --dbRootPwd='数据库 gbase 用户密码' --overwrite --sync_coordi_metadata_timeout=60 --retry_times=1 --parallel_pack=1
做备机替换期间需要注意一下几个问题
一:replace.py 工具执行期间,不要有连接进入数据库进行 ddl 和 dml 操作。如果有需及时清理。该工具执行一段时间后集群会进入只读模式,此时无需再做操作用户连接无法执行 ddl 和 dml 的 sql 语句。
二:集群所有主机的 root 密码需一致。
三:备机的主机用户 gbase 需要可以以 su – 的方式切换为 root 用户
我在做的过程中就遇到了第三个问题报错提示没有 opt_prepare 文件夹

实际上工具会切换到 root 用户创建此文件夹,再将此文件夹的属主改为 gbase。
还有一个问题
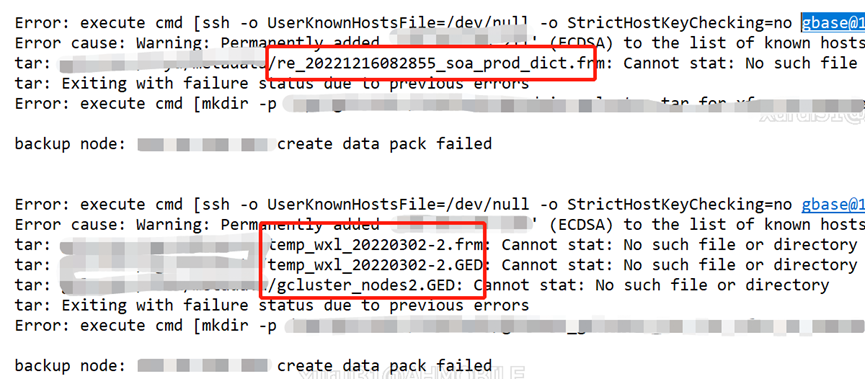
在执行的过程中可能会遇到图中的报错,先在数据库层面 drop 看有无相应的表,如果能 drop 最好像 temp 开头和 gcluster_nodes2 都是可以 drop 的。
而 re_开头的提示没有这张表这个时候就要在文件系统层面删除 rm -rf

使用 c3 工具 gc 和 gn,所有的数据库,metadata 和 sys_tablespace 都要删。
同时建议只删提示的,可能会多次提示。
以上问题的排除后再执行 replace.py 工具应该就可以了,一个小时以内备机替换应该就可以完成。完成后数据库就可以正常使用,数据库会自动同步数据。如果使用了正在同步的表,可能会导致同步卡住。或者等待数据同步完成表才能正常使用。数据同步时间视数据量决定。
查看同步进度的方式
gcadmin showdmlstorageevent
看 event count 的数量
如果在数据同步时提示备机替换所在的表分片不存在报错,等数据同步完再此重建表就可以了。
Ps:
我在用上述方法做完备机替换后在 v86 版本可能会遇到有表报错缺少故障主机的分片,重建后还不行 (应该是 bug)。有个解决办法但是我没做过,就不写出来误人子弟了,如果你遇到了没法办法解决可以加我 qq1501659021 用这个方法试下。



