




收到业务侧反馈有一个存储过程无法执行在启动一分钟左右,会报错。

如图所示报错信息 could not temporarily connect to one or more segments
翻译过来是 “暂时无法连接到一个或多个段”,段在这里就是实例。
第一反应是不是有实例宕了,gpstate -e 查看数据库状态。
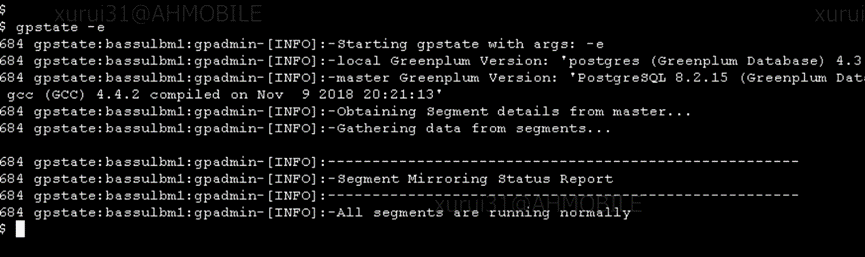
一切正常,没有实例宕停的情况出现。但是报错信息除了告诉我们无法连接到某个实例之外,也没有什么有用的信息。(其实,有一个提示很重要但是当时没有在意,那就是 “line 105”)
看下数据库日志,并询问业务一些信息,如是否是新上线的调度,insert select 所涉及的表有多大,是只有这一个调度无法执行还是所有的都无法执行。
得到以下几点信息:
一:调度是之前上线的,突然无法执行。
二:涉及的表数据略大具体多少不清楚,但是同样的数据量,同样的调度在另一套只有 10 台主机备库是可以正常跑过的。
三:只有这一个调度有问题。
数据库日志如下:

报错内容与前台给的差不多。百度谷歌也没有搜到有用的消息。
此时看集群资源使用率在三四十左右,且此调度数据量较大。建议业务减少关联表,并在资源空闲时执行调度测试。
同时看下是否是连接数过多的原因。此参数在 master 上最大是 250,在 segment 上最大是 750。

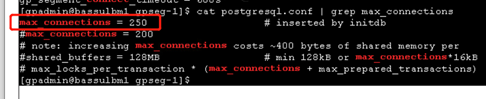
Segment 主机实例的连接数。
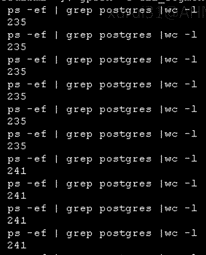
Master 主机的连接数

看来跟连接数没什么关系,业务侧也回复,在资源使用空闲时执行还是报错。并且他们不方便改存储过程,希望我侧尽力解决这个问题。
好吧,再看一下报错信息,有个”line 105”。将存储过程导出,看看 105 行是什么。
psql -c “\df+ functionname” > ~/function.txt
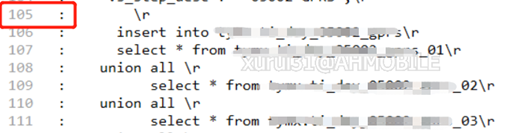
一共 union all 24 张表,后面没有截全。
这应该是提示从这里开始报错的。此时还没有想到什么办法,一边请教原厂售后,另一边想看下这些表的数据量和表结构。于是 select count(1) from tablename;
将 24 张表 count 一遍发现了异常。
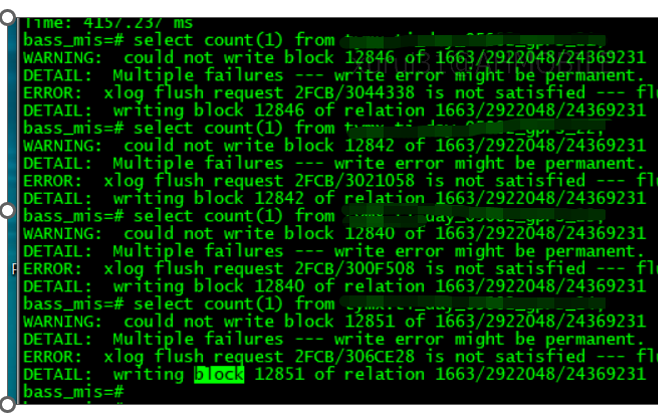
这几张表都报了数据块错误,会不会是因为这个错误导致调度执行不了?
手动处理了一下,具体步骤略,如果不会处理这个错误可以重建表解决。
处理完验证没有问题,再此联系业务测试,还是不行。此时陷入了僵局,似乎没有什么办法解决了。
原厂售后工程师也回复,看下 segment 节点有没有 panic,一般这样的报错是 segment 有 panic 导致连接突然中断。并且表示生产库的版本遇到这样的问题没有什么解决办法,只能绕过。
看下 segment 的数据库日志。

还是有数据块报错,但是 count 表是正常的。找一下这个数据块属于那张表。

这张表是 heap 表,并且常规方法无法处理。联系业务侧重建并测试。
重建后再次执行成功。
注:如果是使用 gptransfer 和 copy 函数将表导入数据库,就有可能发生数据块错误。自建表不会。



