




如果将 Mysql 的整体架构简单的概括一下,可以分为四个部分。
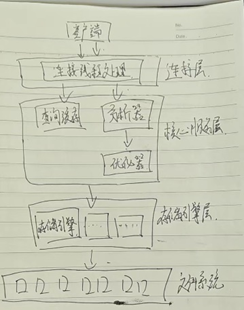
连接层:连接层负责接受各种程序或者客户端的连接,身份验证等等。
核心服务层:核心服务层通常叫 sql layer 在这里会对接受到的连接操作进行权限的判断,解析 sql 并通过优化器进行优化,同时还会做一个操作 “query cache”。query cache 是一种缓存机制会将经常查询使用到的数据缓存到内存中当再有操作使用到这些数据时会直接从内存中取用,不需要再进行查询优化,也无需与存储引擎做交互。从而提高 Mysql 的执行速度。但是 qc 一般只建议在只读环境中开启,如果是频繁读写的环境因为每次更改都会刷新数据反而会造成效率下降。
存储引擎层:这层的功能比较简单就是将数据存储到磁盘上。并且提供对数据的访问接口。有多种存储引擎可以选择比较有代表性的 InnoDB、MyISAM、Memory 等等。用户可以根据表的使用需求针对性的选择不同的存储引擎。
数据存储层:主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
下面请出一张经典的图,详细的解释下模块的用处。
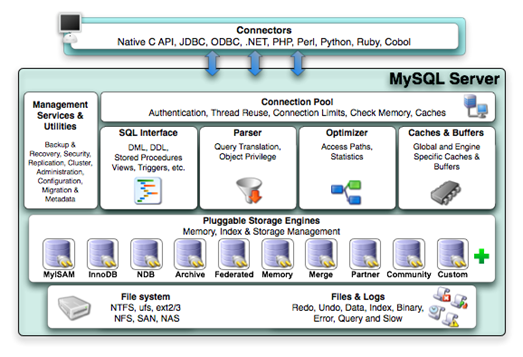
连接层:可以看到跟上面说的一样,有 native c api,jdbc,python 等连接 mysql。
连接池:负责管理客户端和数据库的连接,每一个连接都有一个线程管理。有了这个模块可以提升连接过多时的性能。
缓存:就是上文说的 qc 当数据库收到一个查询时会先到 qc 看有没有执行过这个 sql,如果执行过语句及其结果会以 key-value 对的形式存储在内存中。key 是查询的语句,value 是查询的结果。有的话就会直接返回客户端。没有的话就会按照常规的操作执行。这个概念大概了解下就行生产一般不会开启,并且 8.0 版本之后取消了这个功能。
解析器:更像是 “检查器”,这里会检查你执行的 sql。比如 sql 语法有没有写错,写错了就会报语法错误。使用的字段有没有写错,写错的话就会报错不存在等等。
优化器:优化器就是当 sql 中使用到的表有多个索引的时候决定应该使用什么索引,但是注意优化器只是根据规则判断,个别时候这个判断可能并不是最好的。可以使用
- use index : 建议 MySQL 使用哪一个索引完成此次查询(仅仅是建议,mysql 内部还会再次进行评估)。
- ignore index : 忽略指定的索引。
- force index : 强制使用索引。
这几个关键词来灵活运用。
除了索引的选择还有多表连接时的连接顺序。在条件查询时进行优化处理。
执行器:完成上面的步骤就会进入到执行的步骤,先判断用户有没有对表的相应权限,有的话再根据表所定义的存储引擎调用对应的存储引擎。
存储引擎层:就像上图那样 mysql 支持多种存储引擎,用户根据自己的需求使用就行了。
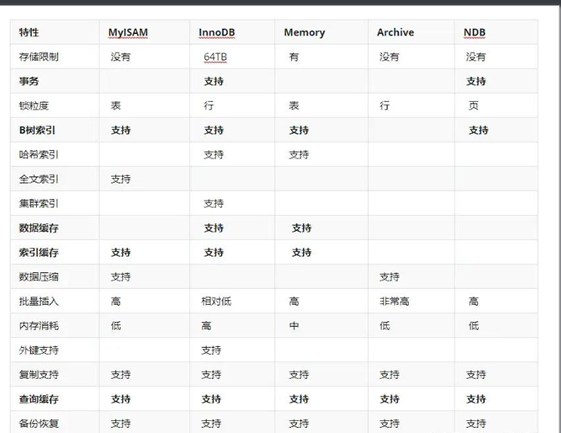
上图时不同存储引擎之间的区别,可以大概了解一下。
系统文件存储层:系统文件存储层是将数据库的数据和日志存储在系统的文件中,同时完成与存储引擎的之间的交互,是物理意义上的存储层。存放的文件有比如数据文件、日志文件、pid 文件、配置文件等。



