




3.3 master为集群的MasterURL+部署模式为Client时
Client部署模式时,在提交点启动应用程序,因此对应driver端也在提交节点。此时,"spark.driver.extraClassPath"路径对应提交节点的路径。Executor则由调度分配到其他执行节点,此时"spark.executor.extraClassPath"对应的路径应是针对实际分配执行executor的节点(不是提交节点!)。
3.3.1 配置属性方式
属于:集群中jar包部署+ 配置属性的方式
通过前面的测试与分析,应该可以知道配置属性的方式只是将所需jar包放入类加载时查找的路径中,而对应的jar包需要人为去部署。
对应在分布式集群环境下,相关的JVM进程可能在各个节点上启动,包括driver和executor进程。因此当某个节点启动某类进程时,需要保证已经手动在该节点上,对应于配置属性所设置的路径下,已经存在或部署了所需的jar包。
进一步地,通常由资源调度器负责分配节点,运行进程,因此为了保证分配的节点上的进程能成功加载所需类,应该在集群的所有节点上部署所需jar包。
优点:一次部署多次使用
缺点:jar包冲突
3.3.1.1 测试1
1. 启动命令:
$SPARK_HOME/bin/spark-submit --master spark://masternode:7078 \
--conf"spark.executor.extraClassPath"="$SPARK_HOME/thirdlib/ojdbc14.jar"\
--conf"spark.driver.extraClassPath"="$SPARK_HOME/thirdlib/ojdbc14.jar" \
--conf "spark.ui.port"=4071 \
--class com.mb.TestJarwithOracle \
/tmp/test/SparkTest.jar
2. 测试说明:
a) 通过--conf 命令行选项,设置Driver与Executor端的classpath配置属性。
b) 在Driver端的classpath路径下放置所需的jar包。
c) 在Executor端的classpath路径下删除所需的jar包。
补充:这里放置或删除jar包,可以简单通过修改对应配置属性的路径来模拟。
3. 测试结果:
a) Driver端与Oracle的操作:由于设置了classpath路径,同时该路径下放置了所需的jar包,因此操作成功,直接查看driver的终端输出日志。
b) Executor端与Oracle的操作:虽然设置了classpath路径,但该路径下没有放置所需的jar包,因此操作失败,错误信息如下所示(查看4040-默认端口-的executor页面,找到对应的stderr日志信息):
3.3.1.2 测试2
1. 启动命令:
$SPARK_HOME/bin/spark-submit --master spark://masternode:7078 \
--conf"spark.executor.extraClassPath"="$SPARK_HOME/thirdlib/ojdbc14.jar"\
--conf"spark.driver.extraClassPath"="$SPARK_HOME/thirdlib/ojdbc14.jar" \
--conf "spark.ui.port"=4071 \
--class com.mb.TestJarwithOracle \
/tmp/test/SparkTest.jar
2. 测试说明:
a) 通过--conf 命令行选项,设置Driver与Executor端的classpath配置属性。
b) 在Executor端的classpath路径下放置所需的jar包。
c) 在Driver端的classpath路径下删除所需的jar包。
3. 测试结果:
a) Executor端与Oracle的操作:由于设置了classpath路径,同时该路径下放置了所需的jar包,因此操作成功。
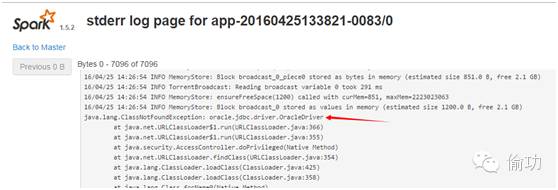
b) Driver 端与Oracle的操作:虽然设置了classpath路径,但该路径下没有放置所需的jar包,因此操作失败,直接查看终端的错误信息,如下所示:
java.lang.ClassNotFoundException:oracle.jdbc.driver.OracleDriver
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:191)
atcom.mb.TestJarwithOracle$.deleteRecodes(TestJarwithOracle.scala:38)
at com.mb.TestJarwithOracle$.main(TestJarwithOracle.scala:27)
at com.mb.TestJarwithOracle.main(TestJarwithOracle.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
atsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
atsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
atorg.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:674)
atorg.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:120)
atorg.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
补充说明:Driver端捕捉了异常,因此Executor可以继续执行。
3.3.1.3 扩展1
在classpath对应的这两个配置属性中,使用不同路径的结果是不同的,比如前面测试案例中的配置属性对应路径修改为hdfs文件系统路径时,driver端的驱动类加载会抛出异常,命令如下:
$SPARK_HOME/bin/spark-submit --master spark://nodemaster:7078 \
--deploy-mode client \
--driver-memory 2g \
--driver-cores 1 \
--total-executor-cores 2 \
--executor-memory 4g \
--conf "spark.ui.port"=4081 \
--conf "spark.executor.extraClassPath"="hdfs://nodemaster:8020/tmp/sptest/ojdbc14.jar"\
--conf "spark.driver.extraClassPath"="hdfs://nodemaster:8020/tmp/sptest/ojdbc14.jar" \
--classcom.mb.TestJarwithOracle \
/tmp/test/Spark15.jar
简单理解:
1. Driver端classpath相关的配置:在启动应用程序(Driver)时作为JVM的Options使用,此时只能识别本地路径,使用hdfs文件系统路径的话,无法识别,因此类加载会失败。
2. Executor端classpath相关的配置:会根据指定的路径去下载jar包,hdfs等文件系统以及被封装,因此可以下载到本地——对应默认在work路径的app目录中,然后添加到仅的classpath路径下,因此可以识别hdfs等文件系统的路径。
3.3.1.4 扩展2
由于之前有人提过几次类似的问题,再此顺便给出简单说明。
异常日志如下所示:
16/04/26 11:35:58 ERROR util.SparkUncaughtExceptionHandler:Uncaught exception in thread Thread[appclient-registration-retry-thread,5,main]
java.util.concurrent.RejectedExecutionException:Task java.util.concurrent.FutureTask@6946dc9c rejected fromjava.util.concurrent.ThreadPoolExecutor@2b3dbbc3[Running, pool size = 1, activethreads = 1, queued tasks = 0, completed tasks = 0]
atjava.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2048)
atjava.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:821)
atjava.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1372)
atjava.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:110)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$tryRegisterAllMasters$1.apply(AppClient.scala:96)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$tryRegisterAllMasters$1.apply(AppClient.scala:95)
atscala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
atscala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
atscala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:108)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
atscala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:108)
at org.apache.spark.deploy.client.AppClient$ClientEndpoint.tryRegisterAllMasters(AppClient.scala:95)
at org.apache.spark.deploy.client.AppClient$ClientEndpoint.org$apache$spark$deploy$client$AppClient$ClientEndpoint$$registerWithMaster(AppClient.scala:121)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint$$anon$2$$anonfun$run$1.apply$mcV$sp(AppClient.scala:132)
at org.apache.spark.util.Utils$.tryOrExit(Utils.scala:1119)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint$$anon$2.run(AppClient.scala:124)
atjava.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304)
atjava.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)
atjava.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
atjava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
atjava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/04/26 11:35:58 INFOstorage.DiskBlockManager: Shutdown hook called
16/04/26 11:35:58 INFO util.ShutdownHookManager:Shutdown hook called
仅根据异常无法判断具体错误信息,需要跟踪其堆栈信息。根据堆栈信息,可以知道是AppClient(代表应用程序客户端)中的ClientEndpoint(RPC通讯终端)尝试注册到Master时被拒绝——此时,检查提交应用程序时使用的Master URL是否正确即可。
经测试验证,当使用错误的Master URL时,会抛出以上异常信息。
3.3.2 自动上传jar包方式
当部署模式为CLIENT时,应用程序(对应Driver)会将childMainClass设置为传入的mainClass,然后启动JVM进程,对应代码如下所示:
if (deployMode == CLIENT) {
childMainClass = args.mainClass
if(isUserJar(args.primaryResource)) {
childClasspath += args.primaryResource
}
if(args.jars != null) { childClasspath ++= args.jars.split(",") }
if(args.childArgs != null) { childArgs ++= args.childArgs }
}
在client模式,直接启动应用程序的主类,同时,将主类的jar包和添加的jars包(如果在参数中设置的话)都添加到运行时的classpath中。即当前的driver的classpath会自动包含--jars 设置的jar包。
同时,driver通过启动的http服务上传该jar包,executor在执行时下载该jar包,同时放置到executor进程的classpath路径。
因此,--jars相当于:
1. 通过"spark.driver.extraClassPath"配置driver 端。
2. 通过"spark.executor.extraClassPath"配置executor端,同时将指定的jar包上传到http 服务,并下载到executor端的该配置路径下。

