




前言
最近做了不少 SQL 优化相关的工作,也将梁大师的《收获,不止 SQL 优化》啃了几遍,全书脉络清晰,由浅入深,层层递进,虽是针对 Oracle 的书籍,但笔者还是从此书中收获了不少。
借此契机,这两天我也理了一个针对 PostgreSQL 的优化思维脑图,借鉴了书中的思路,并加上了一些我个人的理解与经验,打算分为上中下三篇连载。
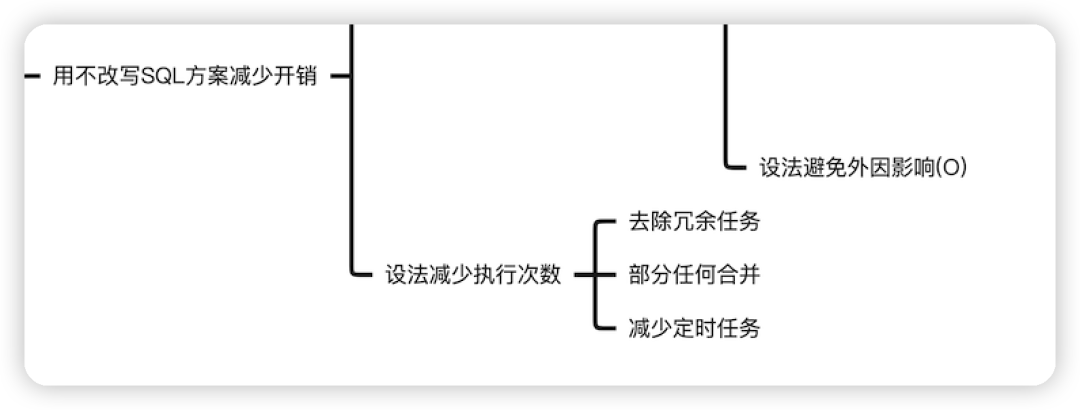
不改写SQL方案减少开销
首先是如何减少 SQL 响应时间,参照梁大师的思路,我将此主题划分为两个大模块
设法减少开销 设法增大吞吐量
设法减少开销,顾名思义,减少单次 SQL 消耗时长与资源,假如一条 SQL 跑了 2 ms,但是这条 SQL 会运行成千上万次,假如我们能够优化至 1ms ,那么可以减少多少逻辑读?多少物理读?1000 次就可以将性能提升 1 秒。减少单次访问开销又可细分为减少访问路径与尽可能局部扫描。
减少访问路径
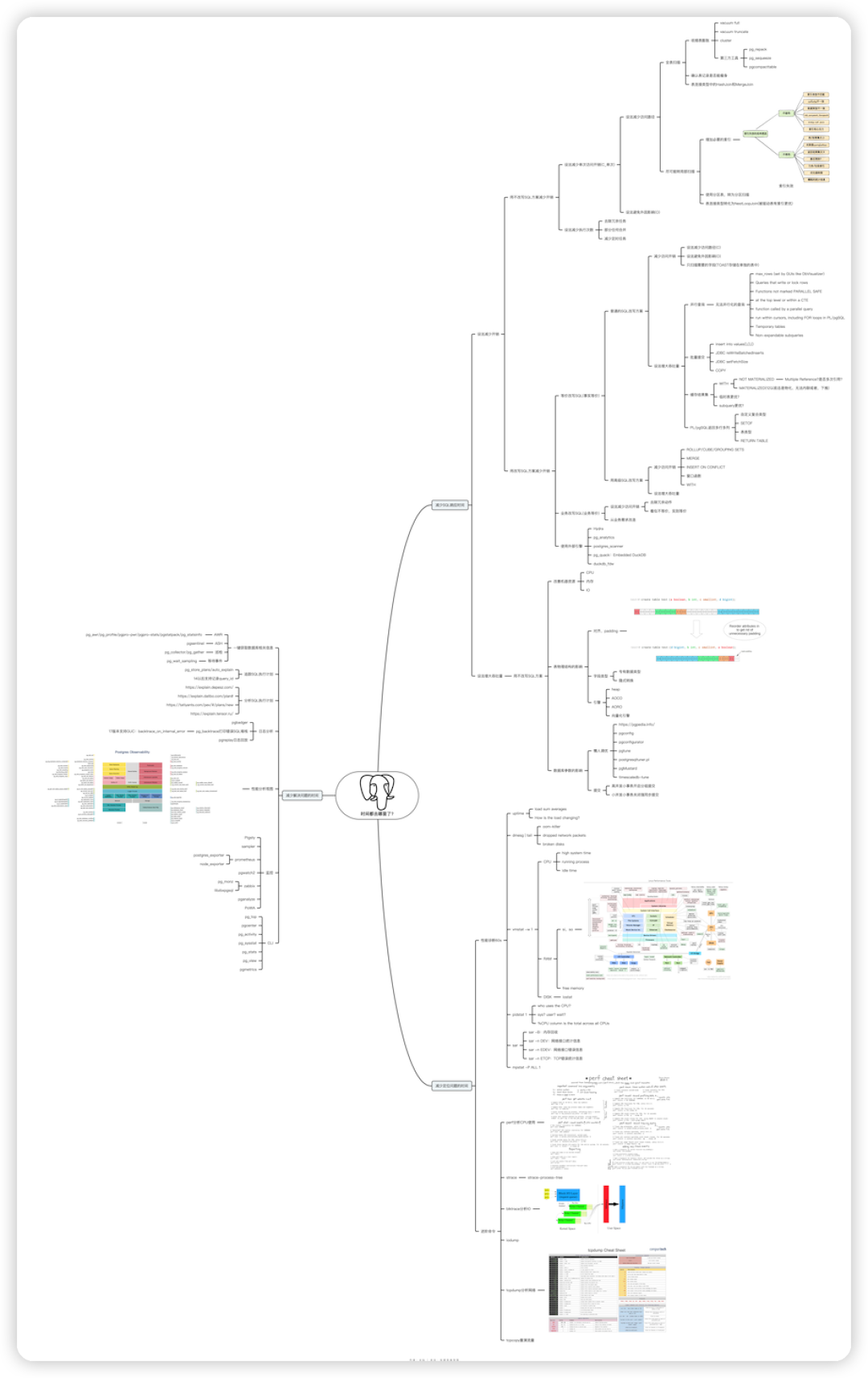
首先是全表扫描,碰到这种情况,我们往往束手无策,这就取决于硬件的算力,要么采用 GP 之类的分布式数据库,多个打一个的思想并行计算。但是我们还是有一些优化手段可以做,比如收缩表膨胀,扫描过程中,死元组需要根据可见性规则进行过滤,其次膨胀还会致使缓冲区效率下降,IO 带宽增大等等。
这里要注意 MergeJoin 的陷阱,伪代码如下
while row1 is not Null and row2 is not Null:
while row1 >= row2:
if row1 == row2:
Add_to_result(row1, row2)
Row2++
Row1++复制
让我们看个例子,以最新的 17 为例 (参照德哥的例子):
postgres=# create table tbl1 (id int, info text);
CREATE TABLE
postgres=# create table tbl2 (id int, info text);
CREATE TABLE
postgres=# insert into tbl1 select generate_series(1,10000000),'test';
INSERT 0 10000000
postgres=# insert into tbl2 select * from tbl1;
INSERT 0 10000000
postgres=# create index idx_tbl1 on tbl1(id);
CREATE INDEX
postgres=# create index idx_tbl2 on tbl2(id);
CREATE INDEX
postgres=# explain analyze select count(*) from tbl1 join tbl2 on (tbl1.id=tbl2.id) where tbl1.id between 2000000 and 2090000;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
-------------------------
Aggregate (cost=288722.08..288722.09 rows=1 width=8) (actual time=672.354..672.355 rows=1 loops=1)
-> Merge Join (cost=1.07..288503.06 rows=87611 width=0) (actual time=586.723..663.777 rows=90001 loops=1)
Merge Cond: (tbl1.id = tbl2.id)
-> Index Only Scan using idx_tbl1 on tbl1 (cost=0.43..2716.66 rows=87611 width=4) (actual time=0.036..19.625 row
s=90001 loops=1)
Index Cond: ((id >= 2000000) AND (id <= 2090000))
Heap Fetches: 0
-> Index Only Scan using idx_tbl2 on tbl2 (cost=0.43..259691.06 rows=10000175 width=4) (actual time=0.017..417.9
17 rows=2090001 loops=1)
Heap Fetches: 0
Planning Time: 0.385 ms
Execution Time: 672.405 ms
(10 rows)
postgres=# explain analyze select count(*) from tbl1 join tbl2 on (tbl1.id=tbl2.id) where tbl1.id between 2000000 and 2090000 and tbl2.id between 2000000 and 2090000;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
-----------------
Aggregate (cost=5846.73..5846.74 rows=1 width=8) (actual time=90.054..90.055 rows=1 loops=1)
-> Merge Join (cost=1.07..5844.83 rows=759 width=0) (actual time=0.078..80.991 rows=90001 loops=1)
Merge Cond: (tbl1.id = tbl2.id)
-> Index Only Scan using idx_tbl1 on tbl1 (cost=0.43..2716.66 rows=87611 width=4) (actual time=0.041..19.892 row
s=90001 loops=1)
Index Cond: ((id >= 2000000) AND (id <= 2090000))
Heap Fetches: 0
-> Index Only Scan using idx_tbl2 on tbl2 (cost=0.43..2685.20 rows=86638 width=4) (actual time=0.033..20.129 row
s=90001 loops=1)
Index Cond: ((id >= 2000000) AND (id <= 2090000))
Heap Fetches: 0
Planning Time: 0.415 ms
Execution Time: 90.138 ms
(11 rows)复制
这两个 SQL 是等价的,但是如果其中一个 SQL 不包含过滤条件的话 (第一种写法),MergeJoin 会从索引开头全部扫描,直到超过匹配范围,这个实际扫描的 rows 就可以看出,所以要小心 MergeJoin 的这个陷阱,我在 GP7 里面测了一下,GP 会自动优化,相比之效,PostgreSQL 的优化器就要稍显笨了一些。
转化为局部扫描,很好理解
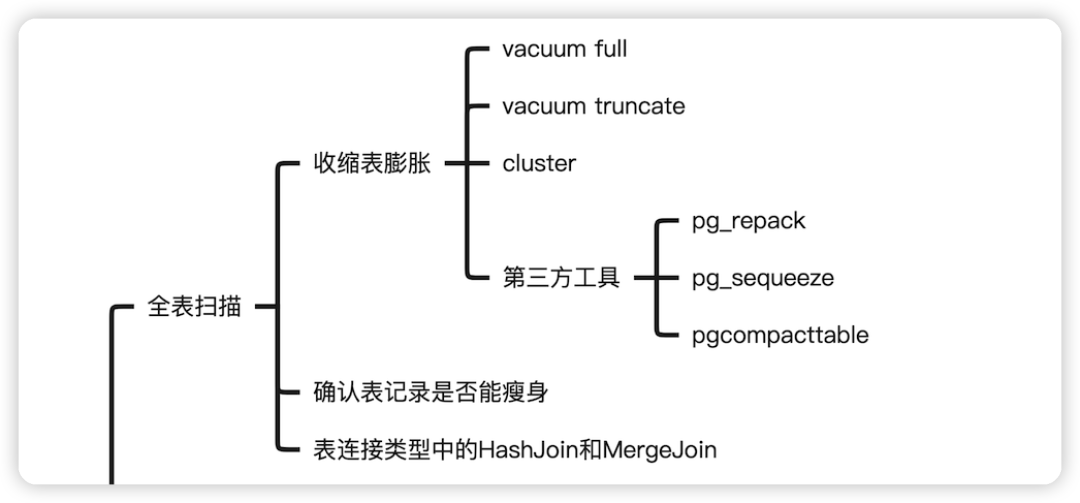
增加必要的索引,通过索引扫描;主要是当心索引失效的各种场景 转化为分区表,通过裁剪,转化为分区扫描,其实分区表的思想还可以进一步延伸,比如所有数据都冗余存储在一张表中,我们完全可以将数据分为热、温、冷,进行剥离开,减少扫描的数据量。
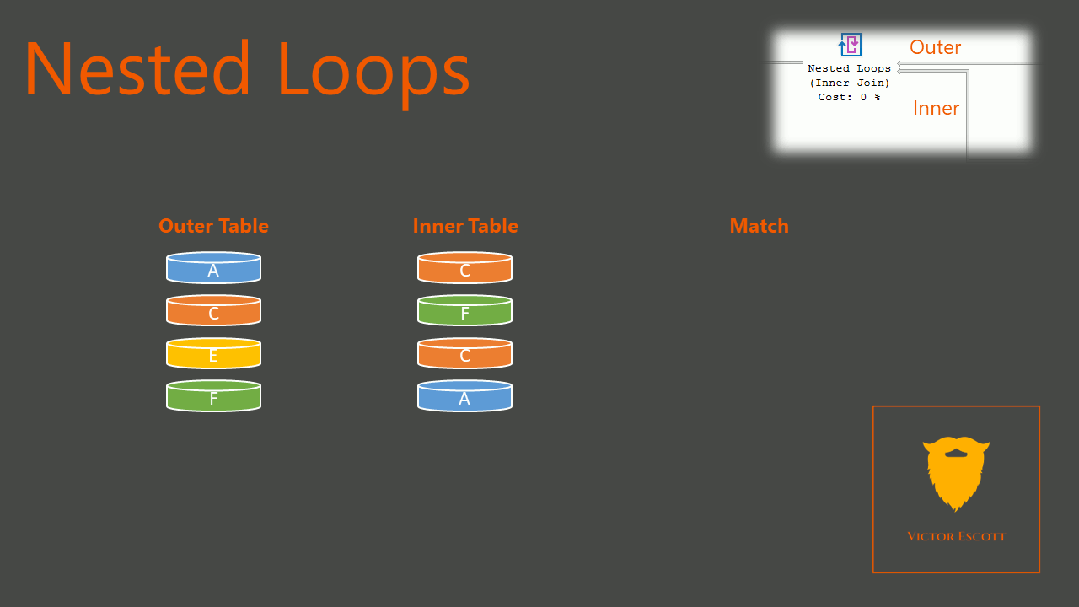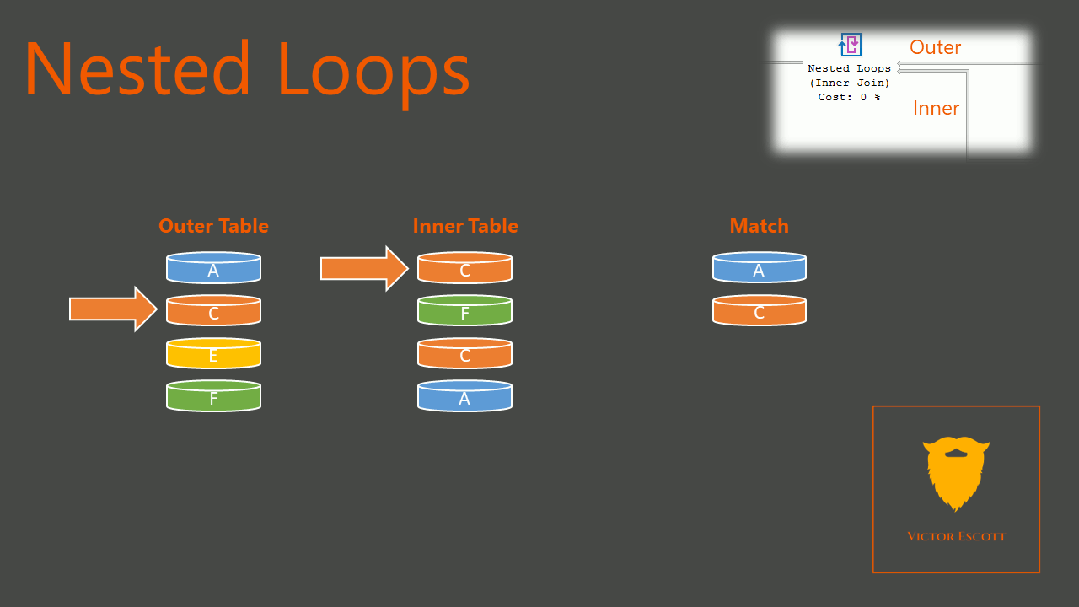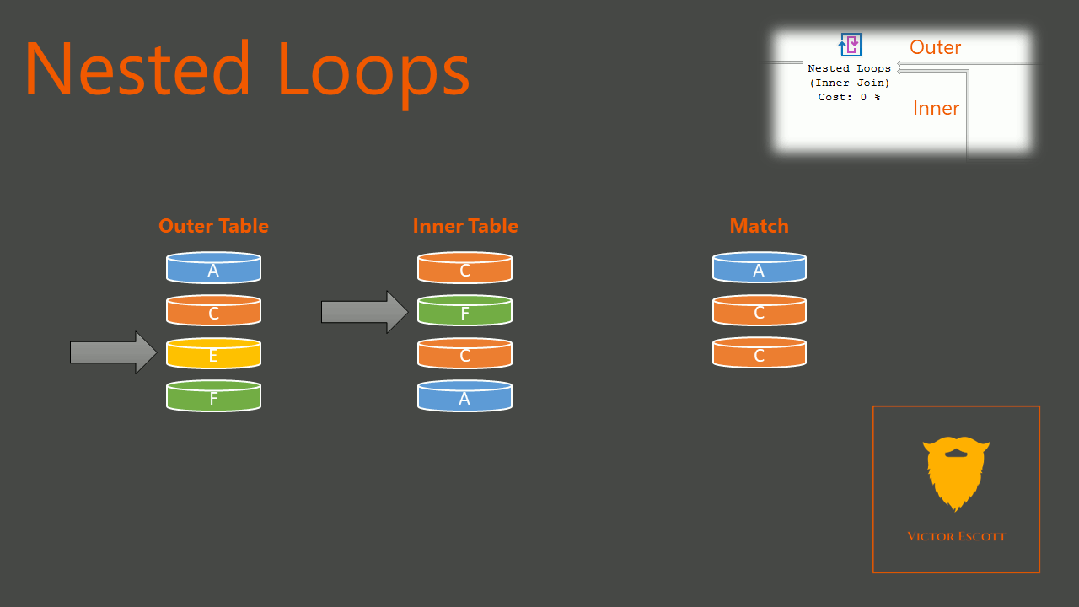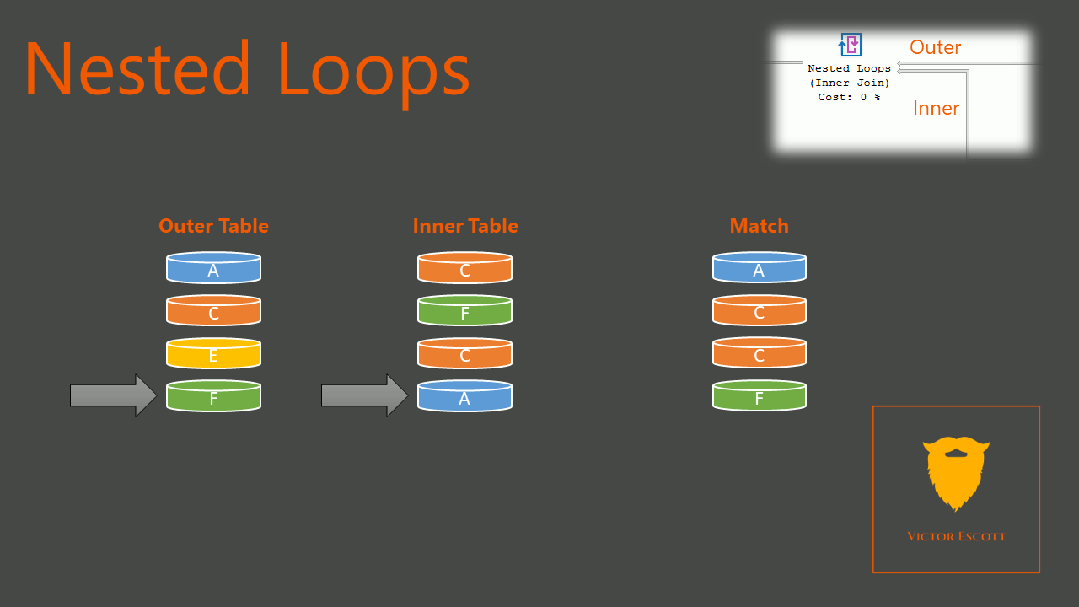
如果是多表关联,NestLoop,其伪算法是
For row1 in table1:
For row2 in table2:
If (row1 == row2):
Add_ to_result(row1, row2)复制
复杂度是 O(M*N),不过,如果被驱动表有索引的话,那么我们就可以通过索引,精确定位内表中的数据,从而"减少"对内表的扫描。
设法减少执行次数
这个思想很好理解,减少一些不必要的 SQL,比如去除冗余任务,部分任务合并,减少定时任务的执行等等。我之前就曾遇到过,明明不需要的已经淘汰的业务,还会每天半夜在数据库中跑一堆定时任务。
改写SQL方案减少开销
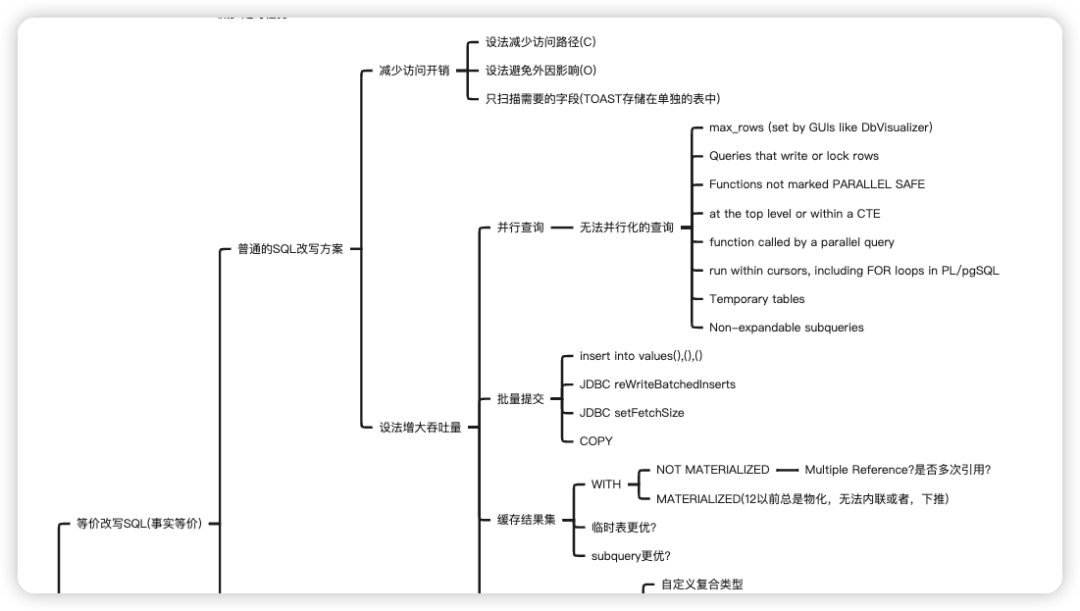
作为 DBA,我也不爱改写 SQL,但是有时依旧需要我们去改写 SQL 才可以进一步优化。改写 SQL 又可分为
事实等价,不如通俗地理解为 SQL 返回的结果一模一样 业务等价,业务上能实现同样功能
首先是耳熟能详的禁止 select *,不需要的字段就不要去取,其危害不言而喻:无法走 index only scan,还会增加 IO 带宽,这两点基本都能想到,还有一点是 TOAST 的影响,千万不要忘了 TOAST 的优势,由于 TOAST 在物理存储上和普通表分开,所以当 SELECT 时没有查询被 TOAST 的列数据时,不需要把这些 TOAST 的 PAGE 加载到内存,从而加快了检索速度并且节约了使用空间。
其次是增大吞吐量,比如并行查询,用资源换时间,但是要注意目前还无法并行化的查询,我这里大致罗列了一些
max_rows (set by GUIs like DbVisualizer),典型场景是 DBeaver,会自动优化每次"分页"显式 200 行 Queries that write or lock rows Functions not marked PARALLEL SAFE at the top level or within a CTE function called by a parallel query run within cursors, including FOR loops in PL/pgSQL Temporary tables,临时表由于会话内可见,因此无法并行 Non-expandable subqueries
还有问的最多的 insert 能否并行?copy 能否并行?答案是不能。
小结
上篇就到这,下一期继续。
评论

 0 点赞
0 点赞 0 点赞 0 点赞
0 点赞 0 点赞