




此前文章《OB SQL 性能抖动问题分析和应对》介绍过 OB SQL 性能抖动原理,今天分享一篇真实业务 SQL 性能抖动诊断案例。结论的参考意义不是特别大,主要是问题分析的过程也许能对大家有所启发。
问题现象
医疗 HIS 业务,大势所向,从 ORACLE 迁移到 OB(MySQL租户)。迁移那道槛迈过去了,剩下主要就是性能问题。细看下来,OCP SQL 巡检大量告警,SQL 审计日志里间歇性有报错的 SQL,落地并不平稳。不过总体上数据量和访问量也不算高,客户业务大部分时候体验还算好,除了一个间隙性的结帐业务。该业务有时候跑的很快,几乎秒出;有时候跑的很慢,等半分钟后报错,很是诡异。环境的变化除了国产化数据库外还有国产化主机和操作系统以及复用一个共享存储,不过问题原因的矛头主要还是数据库。
应用时快时慢,没有给出具体的日志。研发给出了怀疑的 SQL,但多次执行也是很快,偶尔很慢却又很难复现,没有明显的规律。
问题定位
数据库性能的诊断跟医生看病、刑侦断案并无二致,要从大量现象中找出对应的线索,然后推演出一个最有说服力的证据链。
分析 ODP 日志
首先就是要找到跟业务这个现象相关的日志,进一步确认问题的存在和时间点。此时数据库上慢 SQL 非常多,看 OCP 的慢SQL去跟业务问题匹配,这个效率非常低。所以先不看 OCP 里的 OB 问题,而是看 ODP 的诊断日志(obproxy_digest.log
)和错误日志(obproxy_error.log
)。后者日志更少,反映的问题更严重。果然就在错误日志里找到跟业务研发说的有关 SQL 信息。
2024-06-22 16:19:16.253609,obproxy,,,,obdemo:obmysql1:obuser,OB_MYSQL,VIEW_XXX_TOTAL,view_xxx_total,COM_QUERY,SELECT,failed,1317,SELECT `v`.`ID`%2C `v`.`CHARGESERIALNO`%2C `v`.`DAILYSERIALNO`%2C `v`.`OPERATORID`%2C `v`.`ORG_CODE`%2C `v`.`QUANTITY`%2C `v`.`SETTLEMENTDATE`%2C `v`.`TOTALPRICE`%0AFROM `VIEW_XXX_TOTAL` AS `v`%0AWHERE (((`v`.`ORG_CODE` = 'PDY60004') AND (`v`.`OPERATORID` = '1015')) AND (`v`.`DAILYSERIALNO` IS NULL OR (`v`.`DAILYSERIALNO` = ''))) AND (`v`.`SETTLEMENTDATE` < timestamp('2024-06-22 15:44:50')),29985936us,56us,0us,0us,Y0-00007FFA65113050,,,,0,192.255.101.2:2881,Query execution was interrupted,复制
这个日志里给出了几个信息:
这个 SQL 执行时间用了 29.98秒,这是 ODP 视角记录的时间。 这个 SQL 执行报错了,MySQL 错误号是 1317
,错误信息是:Query execution was interrupted
。
这个报错信息在 MySQL 里也比较常见,就是执行被中断了。到底是被谁中断了,暂时还不确定。
分析 SQL 审计视图
上面的 SQL 运行时间点、租户信息、数据库名、用户名信息就更精准了,根据这些信息进一步到 SQL 审计视图里定位相关 SQL记录。
select usec_to_time(request_time) req_time, svr_ip, sid, client_ip, user_client_ip, db_name, plan_id, ret_code, sql_id, query_sql, elapsed_time, execute_time, return_rows, affected_rows, event, flt_trace_id
from oceanbase.gv$ob_sql_audit
where ret_code <0 and plan_type in (1)
order by request_time desc limit 100
;复制
下面是某个时刻捕获到的报错 SQL。这些 SQL 不一定就是这个问题业务的 SQL。
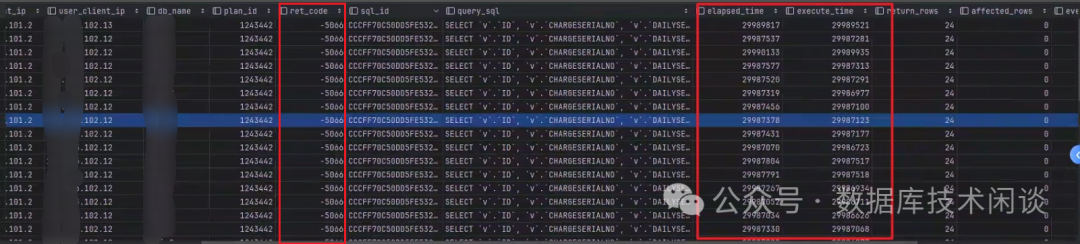
从这些报错记录里看到这些 SQL 执行时间都是 29.9秒多,且报错代码都是 -5060
。这个就比较有趣了。起初以为是 SQL 语句超时时间是 30秒,查了一下发现租户的语句超时时间早就改到 2000秒了。此外,语句超时报错代码也不是 -5066
。查询官网错误号里 5066 说明如下:
ERROR 5066 (HY000) : Session interrupted
OceanBase 错误码:5066
错误原因:Session 被终止。
解决方式:联系系统管理员或数据库管理员。复制
跟业务开发一确认明白了,业务 SQL 有执行超时机制,语句超时时间恰好是 30秒,推测就是 JDBC SQL Statement Timeout 设置。业务也尝试调整这个超时时间(调大到 300 秒以上),那是业务自己分析的一个技巧。总体上业务感觉还是数据库出了问题。
确实,从 SQL 审计视图看,这些 SQL 执行时间已经接近了 30 秒还没有完全执行完就被客户端中断了。跟 ODP 的那段日志也能对应上。也间接说明 ODP 到 OBServer 之间的链路延时很低(这也是显然的,ODP 就在 OBServer 机器上。如果有些 ODP 是独立部署的,那是要怀疑一下这个链路延时)。
进一步根据这个 SQL_ID 查审计视图,发现也不是每次都报错。往往报错了几条后又恢复正常了。正常执行的时间约在 100ms 以内。这个就跟业务反馈的时快时慢能对得上了。
所以,是数据库问题无疑了。
接下来就是分析这个 SQL 为什么会有时候执行那么慢。
分析 SQL 执行计划
之前的文章总结过,SQL 时快时慢有多种原因。
一是 SQL 的具体参数条件不一样,有些记录查询扫描的记录少所以快,有些记录查询扫描的记录多所以慢。不过拿着这个报错的 SQL 再次执行,发现又很快。这个很快也可能是业务数据逻辑已经发生变化了,现在跑这个 SQL 的结果跟当初业务跑的时候不一样。这点业务也可以配合验证,将业务数据回滚到业务处理之间状态。最终排除了这个可能性。
第二种可能就是 SQL 的执行计划发生了变化。现在跑的很快的时候,SQL 当前的执行计划是没问题的。但是 SQL 跑的很慢的时候的执行计划是什么已经看不到了。因为前面说过了 OB SQL 变慢后 OB 会有个自我调整的过程,重新生成一次执行计划。这个在多次分析 SQL 审计视图观察 plan_id
列也发现了确实变了。这里也是分析方向发生变化的一个时间点,实际上也有部分 SQL 审计视图记录发现 plan_id
列没有变化,就是执行时间变慢。只是后者这种更不符合常理或经验就先被忽略了。
根据 SQL 审计视图里的 sql_id
到视图 GV$OB_PLAN_CACHE_PLAN_STAT
也找到了执行计划的详细信息,包括产生时间,最后一次使用时间,最慢的执行耗时,平均耗时等。从这个视图也能看出一些最慢的时候时间能到300秒。
select tenant_id, svr_ip, plan_Id, sql_Id, type,statement, query_sql, first_load_time, last_active_time, avg_exe_usec, slowest_exe_time, slowest_exe_usec, concat(hit_count,'/', slow_count, '/', executions) hit_slow_to_exe , disk_reads, outline_id, outline_data
from oceanbase.GV$OB_PLAN_CACHE_PLAN_STAT
where tenant_id=1002 and sql_id in ('1F65790A87221C2824892003B190FCF4');复制
下面这个是示意结果记录截图(忽略图中的 outline_id
信息)。
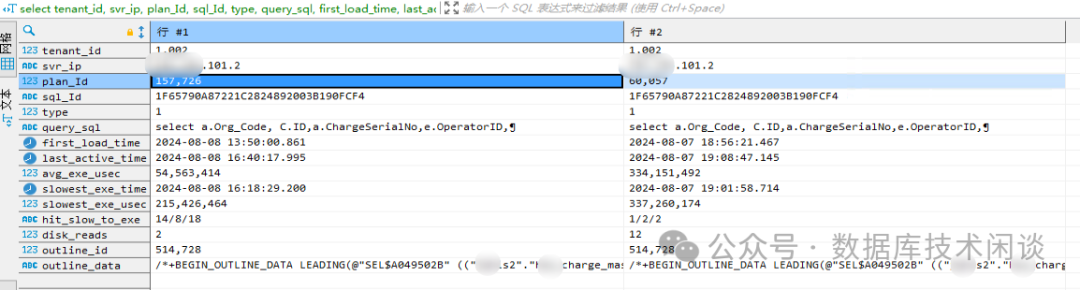
当 OB 淘汰了一个 SQL 执行计划的时候,那笔执行计划记录在这个里面也就看不到了。所以通常一个 SQL 在一个节点上只有一笔执行计划记录。不过有时候也能发现前一天的执行计划记录还在,并且也不会使用(从 last_active_time
判断)。为什么没有被淘汰掉原因不明。不过这笔记录也不是当天执行慢的时间点对应的执行计划,所以也没什么帮助。
接下去能继续做的就是分析当前实际执行计划。示例 SQL 如下。
select plan_depth, plan_line_Id, operator , name, rows, cost,property
from oceanbase.GV$OB_PLAN_CACHE_PLAN_EXPLAIN
where (tenant_id, svr_ip, svr_port, plan_id) = (1002, '***.***.101.2', 2882, 178199 )
;复制
当然这里也同时看了 SQL 的解析执行计划,两个执行计划也并不完全一致。为了验证这点,还专门使用 OUTLINE 绑定技术(所以上面执行计划事后截图看到了绑定的执行计划ID outline_id
)。
create outline otl_xxx20240808 on '1F65790A87221C2824892003B190FCF4' using hint /*+BEGIN_OUTLINE_DATA LEADING(@"SEL$A049502B" ((("userxxx"."xxx_***merge"@"SEL$5" "userxxx"."xxx_merge"@"SEL$4") "userxxx"."xxx_***"@"SEL$2") "userxxx"."xxx_yyy"@"SEL$3")) USE_NL(@"SEL$A049502B" "userxxx"."xxx_yyy"@"SEL$3") USE_NL(@"SEL$A049502B" "userxxx"."xxx_***"@"SEL$2") USE_NL(@"SEL$A049502B" "userxxx"."xxx_merge"@"SEL$4") INDEX(@"SEL$A049502B" "userxxx"."xxx_***merge"@"SEL$5" "xxx_***merge_ind2") INDEX(@"SEL$A049502B" "userxxx"."xxx_merge"@"SEL$4" "xxx_merge_ind2") USE_DAS(@"SEL$A049502B" "userxxx"."xxx_merge"@"SEL$4") INDEX(@"SEL$A049502B" "userxxx"."xxx_***"@"SEL$2" "xxx_***_Ind2") USE_DAS(@"SEL$A049502B" "userxxx"."xxx_***"@"SEL$2") INDEX(@"SEL$A049502B" "userxxx"."xxx_yyy"@"SEL$3" "xxx_yyy_ind2") USE_DAS(@"SEL$A049502B" "userxxx"."xxx_yyy"@"SEL$3") PROJECT_PRUNE(@"SEL$2") PROJECT_PRUNE(@"SEL$3") PROJECT_PRUNE(@"SEL$5") MERGE(@"SEL$2F8A4177" > "SEL$1") MERGE(@"SEL$02A956E8" > "SEL$1") MERGE(@"SEL$4" > "SEL$1") MERGE(@"SEL$7E146CE1" > "SEL$1") OUTER_TO_INNER(@"SEL$CE0B57E1") PRED_DEDUCE(@"SEL$1944B225") OPTIMIZER_FEATURES_ENABLE('4.2.1.0') END_OUTLINE_DATA*/;复制
所以这里也花了很多精力继续去分析是不是执行计划不同导致性能差异很大。
关于 SQL 的讨论
在分析 SQL 性能的过程中,DBA 和开发都有各自的怀疑点。开发会说这个 SQL 也不复杂,就是对一个视图下了几个条件。DBA 把视图解开一看,有的视图有好几个 UNION,每个 UNION 里的子查询有多表连接。视图的逻辑其实代表了某种业务逻辑,然后有些业务就基于这个视图开发,导致开发认为这个很简单。或者有时候是开发使用了一个开发框架,查询条件是框架自动发的,所以开发还不一定能修改这个 SQL。
这个业务慢 SQL 很多的原因也就是由于使用了很多针对视图的复杂查询,而视图本身又是多个子查询汇总。视图对于数据库是一个考验,数据库在给 SQL 生成执行计划时是否会将视图解开并将一些条件下压到子查询中,这个还不一定。要看视图的内部逻辑。
开发还有一种观点,数据量不大,即使 SQL 写的不好,也不至于这么慢。而 DBA 往往看的是 SQL 执行计划中表被条件过滤后的记录,以及多个结果集之间的连接算法等。性能的快慢不一定是由原始的表记录大小决定。这些观点代表了不同角色的经验,大部分时候都对,但也不是绝对的对。都有一定道理,分析的时候都要考虑。
但就这个案例而言,研发的怀疑也确实有道理,4张表 JOIN,最大的表也不过几十万记录,确实没理由有时候跑到 300秒还跑不出来。

上面的执行计划是分析过程中抓到的一种,不同的执行计划只是在其中一个表的 JOIN 顺序和算法上有差异(NESTED-LOOP JOIN
变 HASH JOIN
),但也确实不至于慢到那种程度。
所以后期的分析结论倾向于不是执行计划变化的原因,执行计划的问题很小,很可能是其他原因导致。比如说硬件问题或网络问题。这个就需要相应的证据来证明。可惜实际上没有相关硬件异常日志信息。这条路也不怎么通。
SQL 全链路日志
由于这个业务执行次数并不多,复现还有很大难度。所以分析周期拉的很长。在每天的持续分析 SQL 审计视图中终于抓到变慢的时候的全链路跟踪ID(列 flt_trace_id
)。
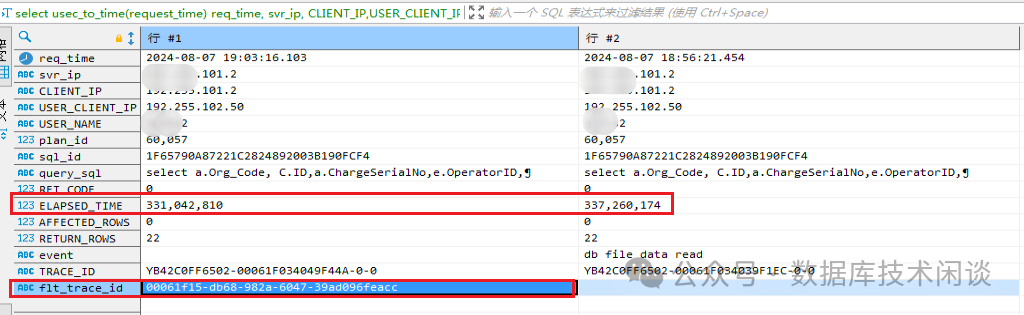
有了这个全链路ID 再借助于 OB 开源工具 obdiag
快速的提取了相关日志。
obdiag analyze flt_trace --flt_trace_id='00061f15-db68-982a-6047-39ad096feacc'复制
这个日志信息不多,比较容易读,也实用。解读方法官网有文档。
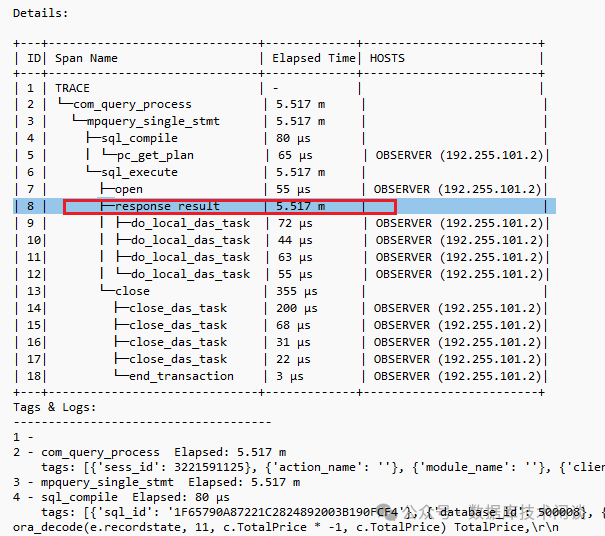
上面是出问题时 SQL 的全链路日志,由于这是 OB 里面的记录的全链路日志,所以只能看到 OB 内部的链路耗时分布。从中可以看到在 response_result
这一步耗时在 300秒左右。不过看不出来为什么这一步耗时那么久。分析方法估计是进一步看执行计划。所以实际上这一步分析应该在看完 ODP 日志之后再分析。
不过这个全链路日志不是每个 SQL 请求都有的,OB 是抽样记录。记录后也不是每笔记录都会在 OBServer 里打印日志(打印也影响性能),打印比例是百万分之一。如果实在想增加捕捉到日志的概率,临时调整一下也行。
alter system set _print_sample_ppm=1000;复制
1000 表示 百万分之1000。不要轻易调整吧。在视图 GV$OB_FLT_TRACE_CONFIG
里可以查看当前全链路日志配置参数。如果业务 SQL 总体 QPS 很高,还是有一定机会捕捉到全链路日志。
此外,有时候自己也确实复现了这个 SQL 的慢。在 obclient (版本 2.2.3+) 里开启全链路日志方法:
obclient 所在 SHELL 设置环境变量: export ENABLE_PROTOCOL_OB20=1;export ENABLE_TRACE=1;obproxy (版本 4.2.0+) 里设置参数: alter proxyconfig set enable_ob_protocol_v2_with_client=true;alter proxyconfig set enable_ob_protocol_v2=true;
。开启会有一些性能成本,具体多少不知道,估计不大。obclient 会话开启 : set ob_enable_show_trace='on';
。运行业务 SQL。 运行: show trace;
运行结果示例如下(下面是 SQL 正常时候的跟踪结果)。
MySQL [xxx2]> show trace;
+-----------------------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-----------------------------------------------+----------------------------+------------+
| ob_proxy | 2024-07-11 16:16:37.354218 | 211.959 ms |
| ├── ob_proxy_partition_location_lookup | 2024-07-11 16:16:37.354224 | 0.031 ms |
| ├── ob_proxy_server_process_req | 2024-07-11 16:16:37.354427 | 211.506 ms |
| └── com_query_process | 2024-07-11 16:16:37.354493 | 211.307 ms |
| └── mpquery_single_stmt | 2024-07-11 16:16:37.354502 | 211.286 ms |
| ├── sql_compile | 2024-07-11 16:16:37.354531 | 54.716 ms |
| │ ├── pc_get_plan | 2024-07-11 16:16:37.354535 | 0.021 ms |
| │ └── hard_parse | 2024-07-11 16:16:37.354660 | 54.540 ms |
| │ ├── parse | 2024-07-11 16:16:37.354661 | 0.111 ms |
| │ ├── resolve | 2024-07-11 16:16:37.354816 | 3.645 ms |
| │ ├── rewrite | 2024-07-11 16:16:37.358556 | 6.895 ms |
| │ ├── optimize | 2024-07-11 16:16:37.365483 | 42.714 ms |
| │ ├── code_generate | 2024-07-11 16:16:37.408254 | 0.471 ms |
| │ └── pc_add_plan | 2024-07-11 16:16:37.409095 | 0.087 ms |
| └── sql_execute | 2024-07-11 16:16:37.409264 | 156.370 ms |
| ├── open | 2024-07-11 16:16:37.409265 | 0.069 ms |
| ├── response_result | 2024-07-11 16:16:37.409347 | 155.878 ms |
| │ ├── do_local_das_task | 2024-07-11 16:16:37.409419 | 0.125 ms |
| │ ├── do_local_das_task | 2024-07-11 16:16:37.412456 | 0.070 ms |
| │ ├── do_local_das_task | 2024-07-11 16:16:37.412655 | 0.064 ms |
| │ └── do_local_das_task | 2024-07-11 16:16:37.561701 | 0.091 ms |
| └── close | 2024-07-11 16:16:37.565255 | 0.364 ms |
| ├── close_das_task | 2024-07-11 16:16:37.565257 | 0.085 ms |
| ├── close_das_task | 2024-07-11 16:16:37.565355 | 0.020 ms |
| ├── close_das_task | 2024-07-11 16:16:37.565452 | 0.031 ms |
| ├── close_das_task | 2024-07-11 16:16:37.565494 | 0.020 ms |
| └── end_transaction | 2024-07-11 16:16:37.565601 | 0.006 ms |
+-----------------------------------------------+----------------------------+------------+
27 rows in set (0.021 sec)复制
相比前面 OB 里看到的全链路日志,这里顶层多一个环节 ob_proxy
。JAVA 应用也可以开启这种全链路 TRACE ,只需要在 JDBC URL 里加上:useOceanBaseProtocolV20=true&enableFullLinkTrace=true
。那时候如果应用发出一个 JDBC SQL 请求 show trace
,得到的结果顶层就是一个 jdbc
。这个功能要求使用 OB 的JDBC 驱动,且版本在 2.4.3+ 。
OB TRACE 日志
尽管上面全链路日志没有给出具体的性能慢原因,但还有个 OB trace 日志可能有帮助。上面 SQL 审计视图里实际上每个 SQL 请求还有个 trace_id
信息。这个列是每一笔请求都有记录,只需要到所有 OB 节点的运行日志 observer.log*
里搜索这个 trace_id
即可。这里也借用 obdiag
工具做。
示例命令如下。
obdiag gather log --scope observer --from "2024-08-06 12:00:00" --to "2024-08-06 13:00:00" --grep "YB42C0FF6502-00061F034049F44A-0-0"复制
时间范围不要指定的太广,日志太多太大命令搜索成本太高就会直接拒绝掉。下面是对业务SQL变慢等时候日志截图。
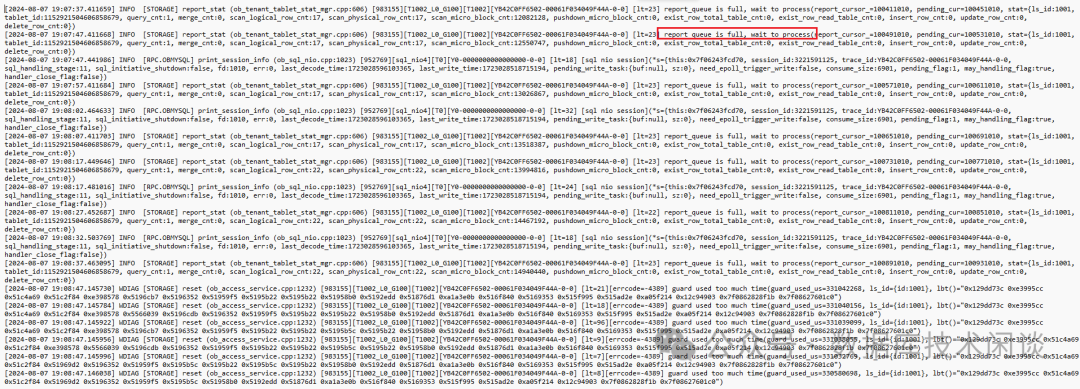
日志里很多提示:report_queue is full, wait to process
,具体什么意思也不知道。OB 的日志基本是是给 OB 内核研发看的,普通人很难看懂这段日志。同时我也找了一个 SQL 执行正常时候的日志进行对比,差异只是红色的提示次数很少或者没有。为此给 OB 提了一个工单,请求他把日志发给研发看看是什么意思。也不知道工单支持人员有没有真的去找研发,答复总是往 system_memory
太小或者 内部 CPU 队列满的角度去解释。而我从内存配置到 CPU 请求数、业务负载综合判断根本就不是 CPU 资源不足导致。后从开源代码里找到出处
int ObTenantTabletStatMgr::report_stat(
const ObTabletStat &stat,
bool &succ_report)
{
int ret = OB_SUCCESS;
succ_report = false;
if (IS_NOT_INIT) {
ret = OB_NOT_INIT;
LOG_WARN("ObTenantTabletStatMgr not inited", K(ret));
} else if (OB_UNLIKELY(!stat.is_valid())) {
ret = OB_INVALID_ARGUMENT;
LOG_WARN("get invalid arguments", K(ret), K(stat));
} else if (!stat.check_need_report()) {
} else {
uint64_t pending_cur = pending_cursor_;
if (pending_cur - report_cursor_ >= DEFAULT_MAX_PENDING_CNT) { // first check full queue with dirty read
if (REACH_TENANT_TIME_INTERVAL(10 * 1000L * 1000L/*10s*/)) {
LOG_INFO("report_queue is full, wait to process", K(report_cursor_), K(pending_cur), K(stat));
}
} else if (FALSE_IT(pending_cur = ATOMIC_FAA(&pending_cursor_, 1))) {复制
虽然我看了这段代码也不明白这是干什么的,但我想一个 OB 研发看了肯定知道的,绝对不会往 CPU 队列满上扯。这段代码事后间接咨询了研发说是跟统计信息有关的,肯定不影响 SQL 性能。
OB 优化器的动态采样
后来跟 OB 售前朋友交流这个问题,提到一个经验,说有些客户也碰到性能时好时慢的问题,关闭优化器动态采样就好了。这个听起来很有道理,查看了一下官网文档介绍:
OceanBase 数据库 V4.2.0 版本开始支持优化器动态采样功能,该功能在 SQL 运行时可以收集需要的统计信息,帮助优化器生成更好的执行计划,从而优化查询性能。
OceanBase 数据库的 SQL 查询语句都会自动应用动态采样功能,使计划的生成更加精准,执行计划的执行更加高效。复制
关闭方法,修改租户变量:
set global optimizer_dynamic_sampling = 0;复制
改了之后,观察了几天,SQL性能稳定了,客户再也没找我了。
重新再去查看了一下 OB 日志,发现那个日志 report_queue is full, wait to process
提示还是很频繁,那应该是跟性能无关。
OCP SQL 性能巡检告警
上面那个业务问题解决了后,业务再也没有提慢的问题。但是 OCP 告警里关于 SQL 性能下降的告警还是非常多。这是业务和OCP 对慢的容忍度不同。
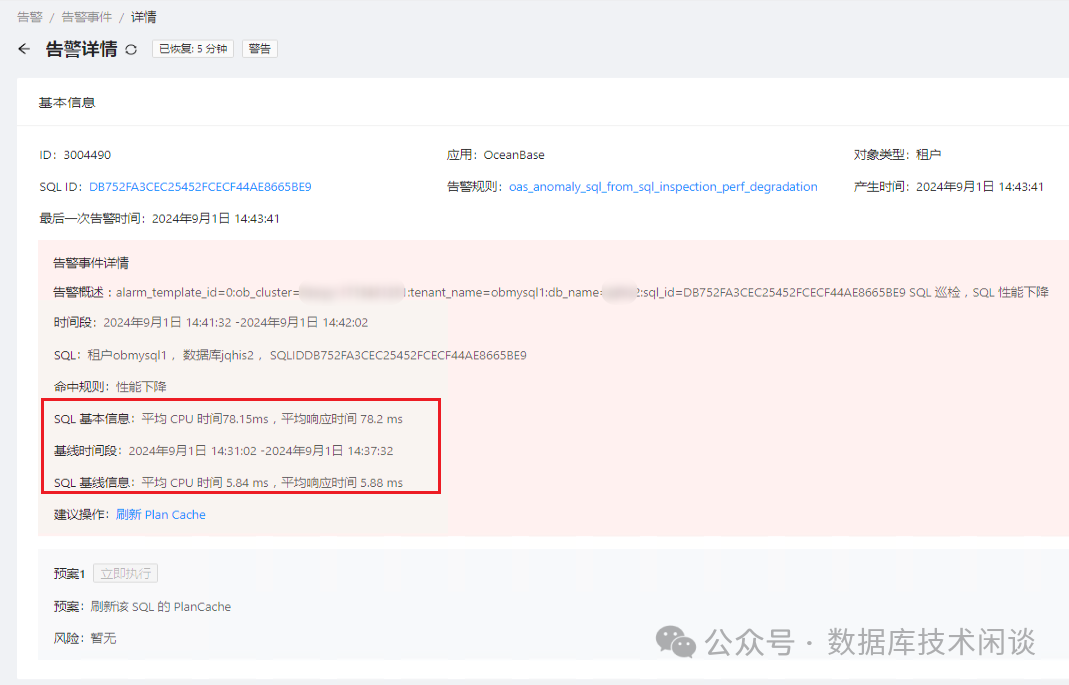
尽管我主张在问题露头的时候就要消灭问题,但业务并不着急这件事。OCP 里频繁的告警看得人实在不舒服,还有个办法就是调整 OCP 关于性能下降告警的阈值。
OCP 的【系统管理】-【系统参数】里搜索:degradation
,有两个参数,一个是跟执行计划变化有关的,一个跟性能下降有关的。我们关注后者。
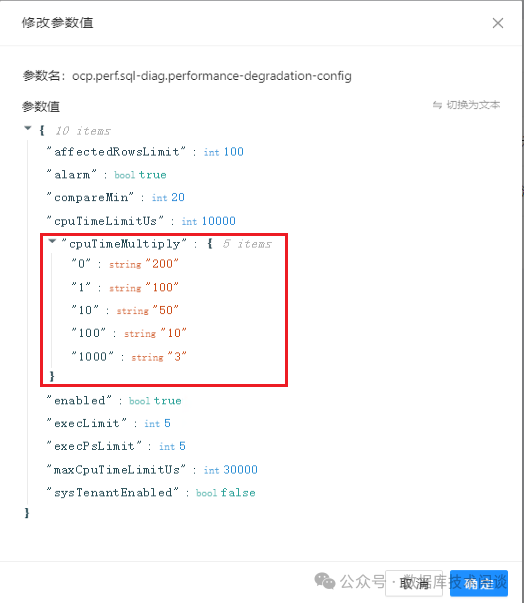
这个参数 cpuTimeMultiply
是针对不同时间段内的性能下降容忍倍数。提交后约3分钟生效。
改动后的一段时间,世界变得安静了许多。
结论
传统业务迁移到 OB 上后,会经常碰到性能下降这个情况。OCP 的监控也能快速发现这类现象。其变慢原因有多种。一是业务 SQL 在传统数据库上本来就有性能问题只是监控手段不到位看不到。二是业务迁移到 OB 上后,执行计划不好或者不稳定经常发生变化导致有时候执行很慢有时候快。除此之外就可能是外部硬件环境原因或者 OB 某个功能不完善导致。本文中案例的经验就是关闭租户的优化器动态采样功能。这个是 4.2.0 版本推出的功能。
参考
更多相关原理和经验请参考:
