




MySQL 优化器
作为国内甚至世界上最为流行的开源关系型数据库,MySQL的计算引擎一直为人所诟病。大家的共识是MySQL的计算层做的很差,但innodb则非常优秀,客观来说确实如此。MySQL从8.0开始才在计算引擎做了大力度的改造,包括重构了执行层,拥有了真正的Volcano执行器,并支持了anti join/hash join等基础功能,目前针对join ordering,社区也在开发hypergraph optimizer来尝试产生更丰富的join tree形态,找到更优的join计划。 但可能是因为基础太薄弱了,这种发展的速度并不快,而且还有一些根本性的问题,不做大手术是无法解决的,就笔者来说,我认为MySQL8.0目前仍存在一些非常明显的问题:
- 复杂查询改写无法应用的问题,比如社区实现了”subquery_to_derived”这样的子查询解相关能力,但这个优化并一定总是有好的效果,因此默认是关闭的,需要用户基于具体的SQL来利用hint开启,但这样case by case的使用会给业务和运维带来很大的负担,很难在实际中派上用场。
- 非常有限的查询改写功能(e.g 谓词下推),无论在数量,以及每种改写功能覆盖的场景上,都非常单一,无法应对生产环境中有分析需求的各种复杂查询。
- 扩展性差,这个是最致命的,MySQL一个非常大的弊端是功能、子系统之间的耦合严重,这导致内部数据结构的组织很复杂且相互交织,如果想扩展新的功能就更加吃力甚至不可能。例如:
- 在查询改写阶段,各个基本能力之间有比较强的依赖关系,一个改写要依赖于前一个改写完成(因为要依赖上一个改写产生的一些结构)
- 优化期的结构与执行期是耦合的,也就是很多优化结构最终也会用于执行,这同样也导致了结构的复杂相互依赖或引用,作为查询改写最需要做的就是不断调整查询树的结构,这会带来问题。
- 改写之间的相互影响没有被考虑,比如MySQL是在最后进行了谓词下推inline view的操作,但下推之后的谓词,可能会使得内层的query block能够实现一些新的改写动作(e.g left join化简为inner join),但这是无法做到的。
- 除了改写模块,物理优化的统计信息完全依赖索引、代价模型粗糙过时、没有任何计划的管理能力,也没有任何自适应的优化、执行能力。。。 这其中每一个点都是一个方向,有很多可以补强的工作,本文主要关注查询改写因此就不深入了,后续会专项一一介绍。
PolarDB CBQT Rewriter
在解决改写框架的扩展性和耦合性这个问题上,我们面临两种设计方案的选择:
- 重写优化框架,比如改造为top-down的方式
- 保留原有的bottom-up模式,实现对改写规则的抽象和基于代价的改写与枚举策略 (参考Oracle的一篇早期的paper)
方案1确实很有吸引力,原因是改造会更彻底,摆脱MySQL原有的历史包袱,而且目前开源的top-down优化框架很多,借鉴参考也会非常方便。但其缺点对我们来说也是致命的,那就是兼容性:前面也提到了MySQL的各类结构的耦合,这会导致优化器的很多动作会对执行层面产生影响,最终会导致执行结果受到影响,例如类型、精度、执行行为等。虽然具备HTAP的能力,但PolarDB仍是一个以在线业务为主的TP系统,其对MySQL的100%兼容性是客户的基本预期,如果打破这个预期,产生的影响会无法预测。 因此方案2就成为了当下的选择,虽然工程复杂度高,但达到的效果正是我们所期望的。 和Oracle一样,我们也称这个改写框架为CBQT (Cost Based Query Transformation)。总得来说,它做到了两件事情
- 将MySQL原有的和后续PolarDB新实现的各类查询改写,用一套规则框架进行了封装,每一个改写能力都是一个规则,其中包括
- 启发式的规则(总是可以应用,改写后效果更优,e.g 谓词下推)
基于代价的规则(不一定更优,需要基于代价确定,e.g scalar相关子查询展开)
有了这套规则框架,后续新实现的查询改写能力,只需要实现几个必要的接口,就可以接入到改写框架中,提升了扩展性,框架会基于一定策略对各个改写规则反复枚举,完成尽可能多的有收益改写,使查询转换为一个尽量更优的形态。
- 对于基于代价的规则,通过对Mini-CBO模块的调用来获取代价信息,并基于代价的比较做出是否应用改写的决策,确保改写后的更优性。
MySQL原有的处理流程如下图: 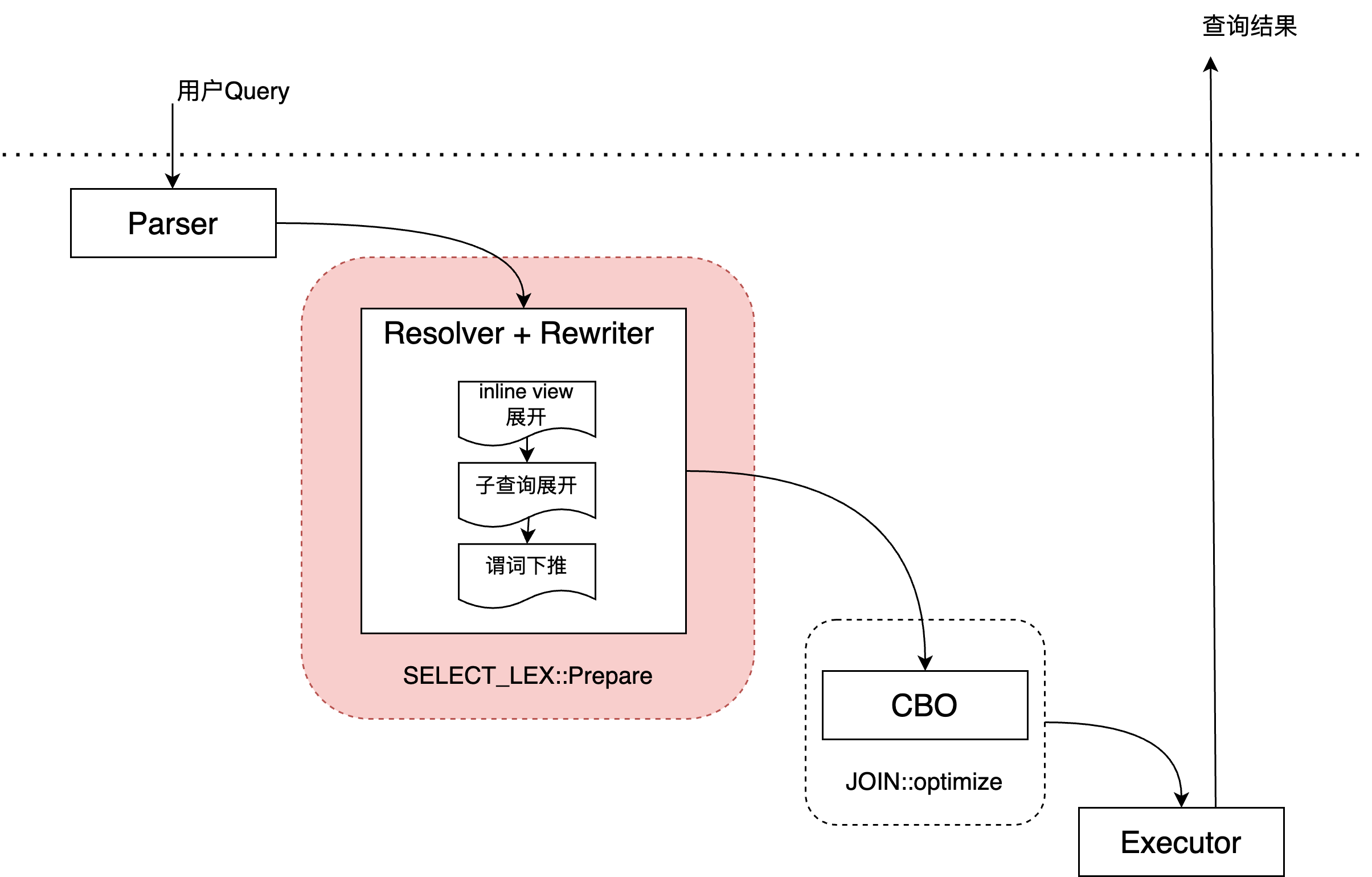 在原有流程中,Resolver和Rewriter是耦合在一起处理的,各个改写动作需要以固定的顺序依次完成,其中一些改写由于不确定其是否能更优需要跳过(除非基于switch/hint强制指定)。 而Rewriter和CBO还是有比较明确的边界,CBO的职责比较明确:确定各个query block中,join的顺序、表的访问方式,代价的估算等。 PolarDB的优化流程如下图:
在原有流程中,Resolver和Rewriter是耦合在一起处理的,各个改写动作需要以固定的顺序依次完成,其中一些改写由于不确定其是否能更优需要跳过(除非基于switch/hint强制指定)。 而Rewriter和CBO还是有比较明确的边界,CBO的职责比较明确:确定各个query block中,join的顺序、表的访问方式,代价的估算等。 PolarDB的优化流程如下图:
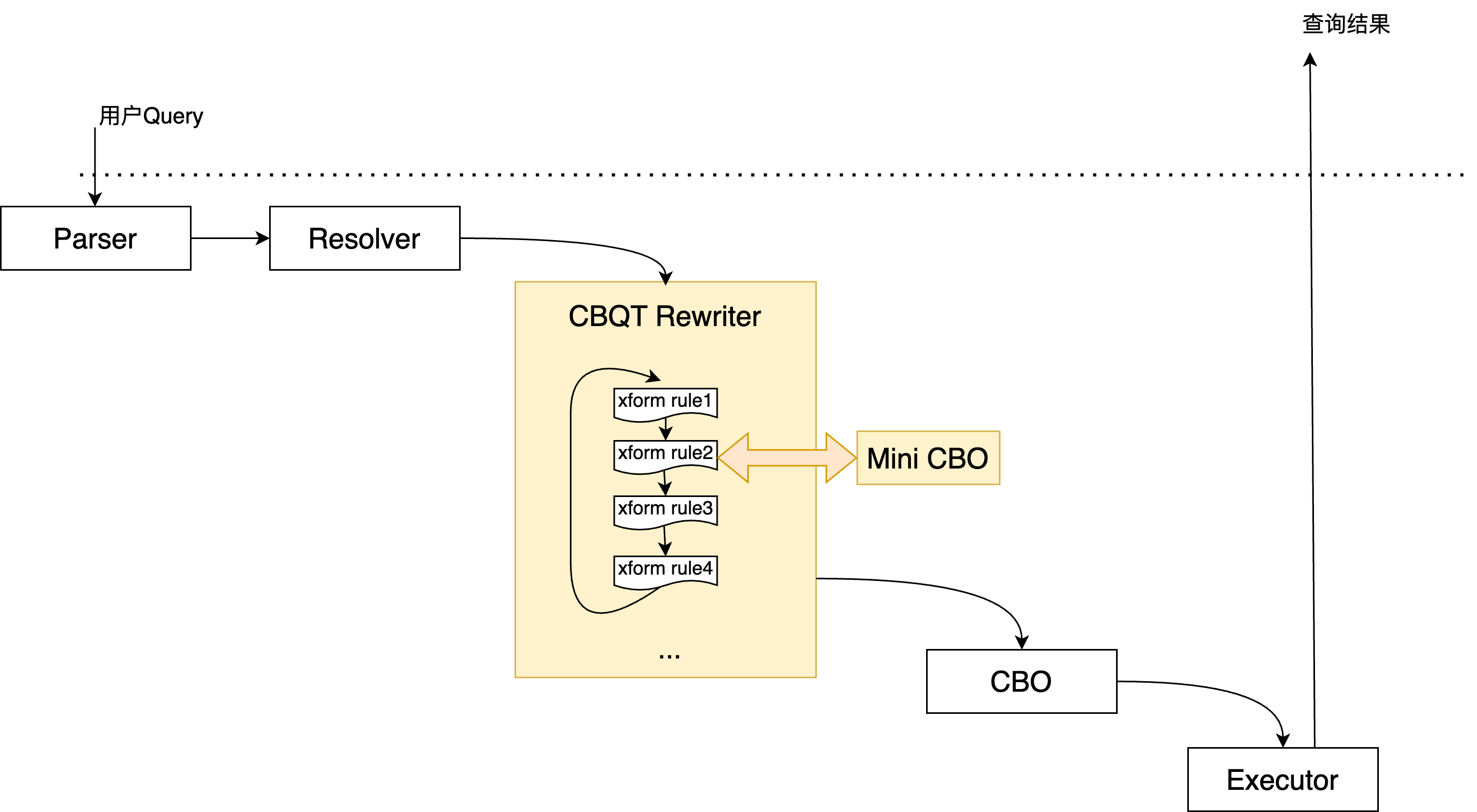
可以看到,在新的优化流程中,Resolver做了解耦,成为了一个独立的流程,这是后续工作的基础,使得Rewriter能够成为一个独立扩展和运行的组件,此外出现了一个Mini-CBO组件,它和Rewriter会反复的交互,实现基于代价的枚举过程。
更丰富的查询改写
在新的Rewriter中,增加了很多查询改写能力,在长期线上运维的过程中,我们针对用户各种复杂查询的应用场景,积累了大量来自用户的慢SQL,从中是可以提取出一系列的共性特征的,从而构成很多新的改写策略,这些改写能帮助用户查询实现数量级的性能提升。 一个最为简单的例子就是投影列裁剪,在基于列存的系统中,投影列裁剪是最为基础的能力,因为可以尽量减少需要读取的列数量,提升CPU/IO效率。但在基于innodb的行存系统中重要性看起来并没有那么大,因此MySQL原有的处理中,只在一个inline view展开到外层时,会消除外层用不到的投影列。但在我们遇到的很多场景中,用户会在inline view中实现一些通用而复杂的业务计算逻辑,将计算结果物化后,外层再根据各种不同的需求做二次处理,这会导致内层inline view为了保证通用性而加入了大量的投影列。这些投影表达式都会经过计算并物化到临时表中,增加计算+内存开销(尤其当投影列是复杂表达式如子查询等)。而针对任一个具体的SQL,外层二次处理需要的投影一般是较少的,因此对于无法展开的inline view,做投影列的裁剪就很有必要了。
SELECT count(0)
FROM (
SELECT t1.id, t1.factory_code, ...
(
SELECT count(DISTINCT sign.user_id)
FROM sign JOIN m
ON ...
) AS sign_user_num,
(
SELECT count(DISTINCT a.user_id)
FROM a
WHERE a.data_state = 0
AND a.paper_id = t1.paper_id
AND NOT EXISTS (
SELECT 1
FROM b
WHERE b.paper_id = t1.paper_id
AND b.user_id = a.user_id
AND a.create_time < b.create_time
) AS exam_user_num,
...
FROM t1 LEFT JOIN t3
ON ...
) countAlias;
=>
SELECT count(0)
FROM (
SELECT t1.id
FROM t1 LEFT JOIN t3
ON ...
) countAlias;复制上面的例子是线上客户的一个真实查询,其内层的投影列有100多个,其中包含一些嵌套子查询的计算,但外部只是做了一个count操作,所以内层的投影列其实只需要保留一个t1.id就好了 目前PolarDB的改写能力还在持续丰富,之前我们写过一个改写系列文章介绍了一部分,后续还会不断补充。
更完备的查询改写
对于查询改写的每一种能力,需要能够实现的尽可能完备、覆盖尽量多的场景,例如社区高版本实现了谓词下推的功能,PolarDB同样也实现了谓词下推,但两者有很大的区别:
- PolarDB 在下推谓词前,首先会做基于等值/非等值的谓词推导,尽量构建可以下推的谓词来做提前过滤,而社区则只基于原始条件做处理,这意味着:
SELECT * FROM t1 JOIN (select * from t2) dt2 ON t1.a = dt2.a AND t1.a > 5;复制
这样的查询是无法推导出 dt2.a > 5,从而实现下推的,但PolarDB可以转换为
SELECT * FROM t1 JOIN (select * from t2 WHERE t2.a > 5) dt2 ON t1.a = dt2.a AND t1.a > 5;复制
这样可以让dt2物化的数据尽可能少,也让t2表的读取能够利用t2.a的潜在索引来加速
- PolarDB可以将谓词下推到inline view/subquery中,社区只能下推到inline view中
SELECT * FROM t1 WHERE t1.a > 5 AND t1.a < t1.b t1.b IN ( SELECT t2.b FROM t2 ); ==> SELECT * FROM t1 WHERE t1.a > 5 AND t1.a < t1.b t1.b IN ( SELECT t2.b FROM t2 WHERE t2.b > 5 );复制
在开发的过程中,我们的一个基本设计原则就是,在调研该功能的已知技术方案时,尽可能在场景的丰富度和功能覆盖面上做到更多,避免浅尝辄止的设计与实现。
基于迭代的枚举框架
有了以上这些更多的改写能力后,我们需要把这些能力以合理的方式组织在一起,在MySQL原处理流程中,各个改写依次尝试一遍后结束,但这会导致改写之间的影响被忽略掉,从而可能错过一些更优的计划形态,例如:
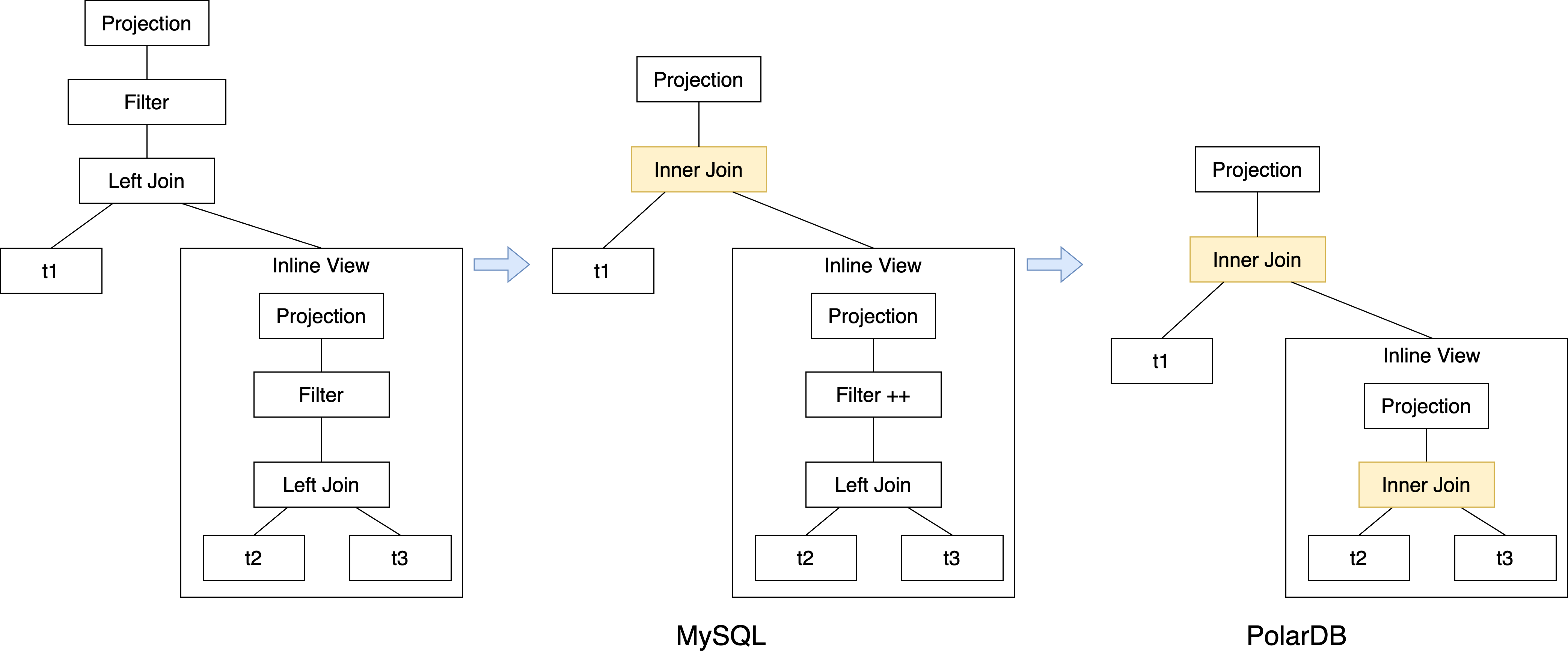
如上图最左侧的一个查询计划图,是t1表和inline view的left join,inline view内部也是一个left join。 MySQL原有流程中,inline view内部和外层查询,会各自考虑基于filter做left join化简为inner join的改写,在这个步骤都完成后,最后会考虑外层的谓词下推到inline view当中,所以在MySQL中,可以看到上图中间的计划树形态。但这错过了基于外层下推条件,将inline view内部的left join做化简的机会,因为谓词下推是所有改写中的最后一个。 相比PolarDB的枚举框架是迭代的,理论上会将所有的规则反复应用,直到没有任何改写能够再次被应用为止,因此是可以获取一个最优的潜在计划形态的。如上图的最右侧,在完成谓词下推后,后续仍会考虑基于新的下推谓词做left join化简,从而保证内层也会转换为一个inner join。
枚举策略
这种反复对改写规则的迭代,自然会造成优化时间的增长,本质上这是优化时间与执行时间的trade-off。因此可以考虑多种可能的枚举策略,对应不同的权衡考虑。 在枚举策略的实现上我们参考了Oracle的处理,在原paper中,共包含有4种策略
- 穷尽式枚举(Exhaustive)
- 迭代式枚举(Iterative)
- 线性枚举 (Linear)
- 两趟式枚举(Two-pass)
- 规则(Rule)
任何一个改写功能,我们将其抽象为一个Rule,一个改写功能可能会应用到很多查询计划树的多个部件中,但逻辑上这仍是一个Rule。
- 对象(Object)
对于每个改写功能,它可能会应用到多个查询树的部件上,比如子查询展开这个Rule,可以应用在多个子查询上,那每个子查询都可以作为一个Object,去考虑它是否应用当前的改写Rule。
考虑到优化效果与效率的折衷,PolarDB目前实现了Linear和Two-pass两种枚举策略。
- 线性枚举 (Linear)
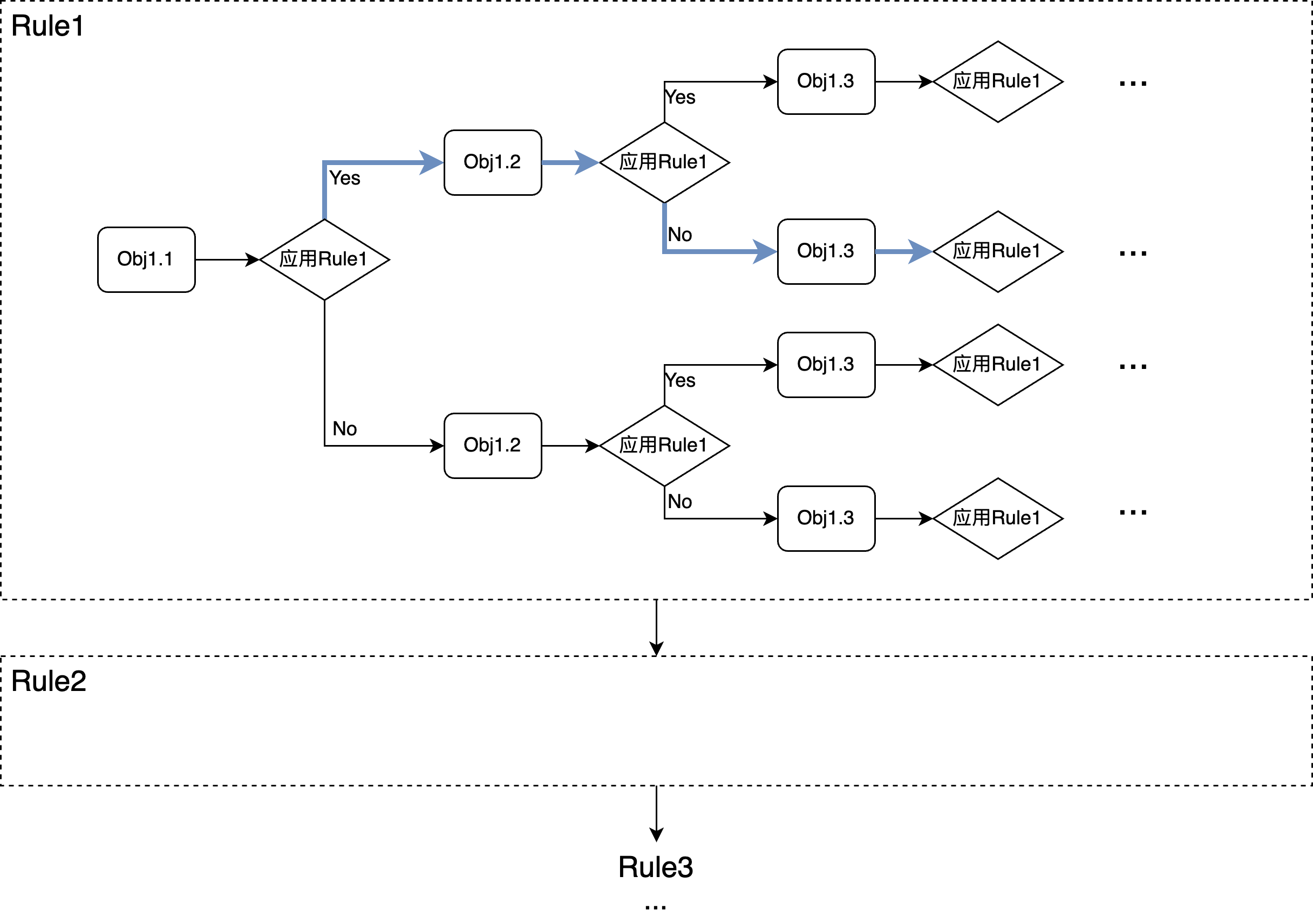
从上图可以看到,在一次迭代中,对所有的rule会依次考虑一遍,相对复杂的部分是在每个rule内部,对每个rule,一个query tree中可能会有很多地方可以应用该rule,也就是图中的多个Obj,对每个Obj,都可能应用或不应用该改写动作,而基于此决定,在考虑下一个Obj是否要应用,所以每个object依次考量一遍并基于当前结果,做下一步的动作。 很明显这是一个对计划空间的局部最优搜索,因此不一定能找到全局最优解,但仍然还是很大程度扩展了原有的计划空间。
- Two-pass
当查询的SQL语句非常复杂时,即使是线性的处理方式也会导致优化时间过长,因此还可以进一步退化: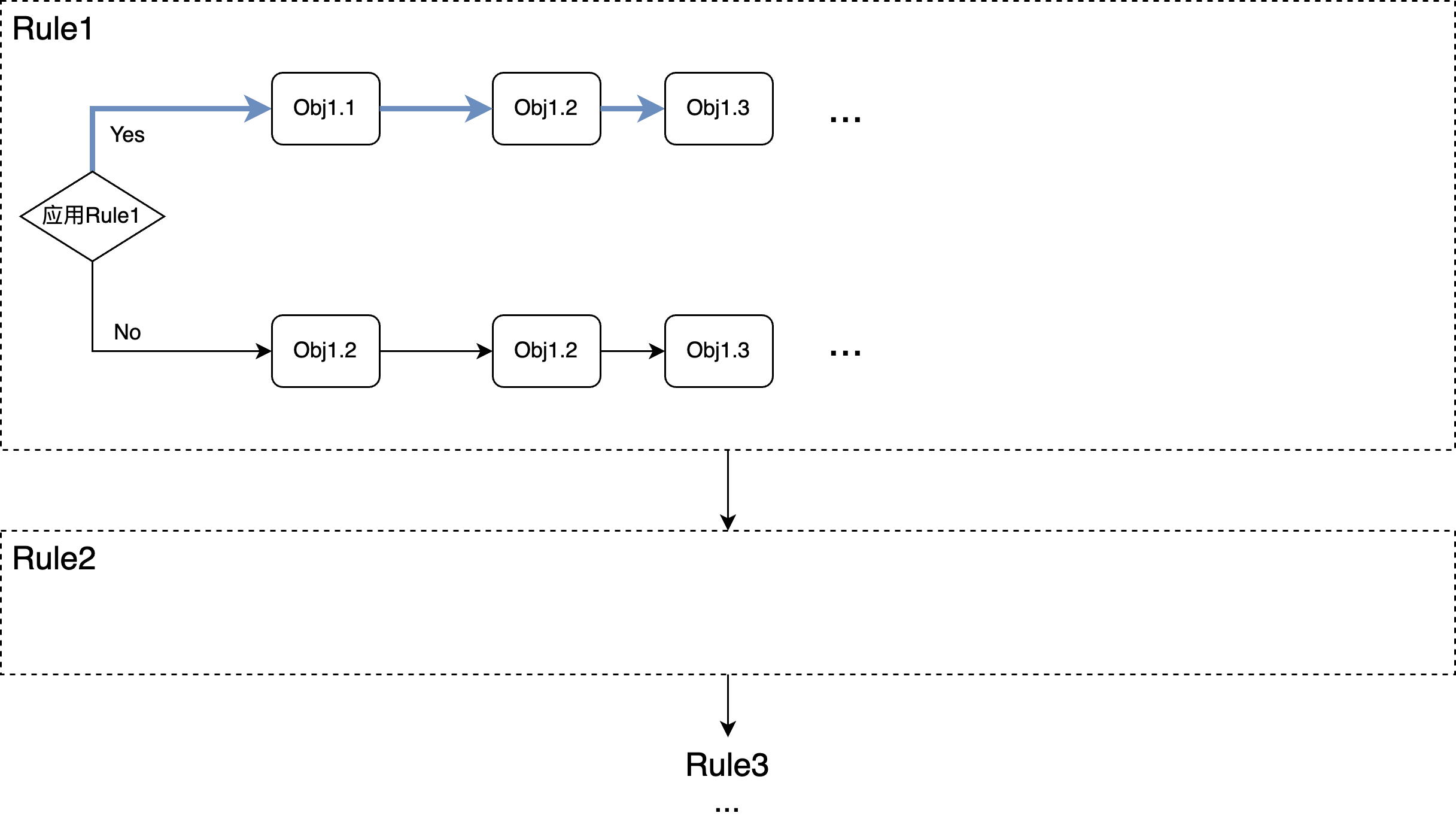
可以看到,仍然是在一次迭代中,对所有的rule考虑一遍,但每个rule内部则简单了很多,只有2个选择:要么对所有object应用该改写,要么所有object都不应用。相对于MySQL基于静态开关的控制,这里等于只多考虑了额外一种情况。 在PolarDB内部,会基于一些策略去考察当前查询的复杂度,自适应的决定使用哪一种枚举策略,默认是线性枚举(Linear)的方式。


