




最近一些工作通过应用机器学习技术来辅助或重建DBMS中基于成本的查询优化器取得了较好的效果,但它们仍存在不足,例如性能不稳定,训练成本高,模型更新缓慢,这些不足是来自于使用机器学习模型预测执行计划的成本或延迟过程中存在的固有问题。针对以上问题,本次为大家带来数据库领域顶级会议VLDB 2023的论文:《Lero: A Learning-to-Rank Query Optimizer》

一.背景
查询优化器是数据库中最重要的角色之一。它的目的是为每个查询选择一个有效的执行计划。提高其性能一直是一个长期存在的问题。传统的基于成本的查询优化器有三个主要组成部分:cardinality estimator, cost model和plan enumerator。其核心执行思路是通过在搜索空间中考虑有效的计划,并返回执行成本估计最小的计划。但是,面对不同的数据分布或系统配置,这种启发式方法并不总是可靠的,可能会产生明显的错误或生成的计划质量较差。于是研究者们进一步研究使用机器学习模型来取代传统的基于启发式的成本模型和计划枚举器等。基于学习的查询优化器仍然有三个主要缺陷:性能不稳定、学习成本高以及模型更新慢。除此之外,传统的和新提出的学习查询优化器的缺陷都源于预测执行延迟或计划成本问题。执行延迟取决于许多因素,例如底层数据分布、工作负载模式和系统环境。训练这样的预测模型是一项耗费较大的操作,它需要收集大量的训练数据,通过执行查询计划和测量延迟统计,并且需要漫长的训练过程来探索巨大的假设空间。
论文提出了Lero,一个learning-to-rank查询优化器。在learning-to-rate范式下,传统成本模型和学习的成本模型可以被视为pointwise方法,它为每个计划输出一个顺序分数(即估计成本)来对它们进行排序,Lero采用一种新的轻量级的pairwise机器学习模型来进行查询优化。Lero采用非侵入式设计,这种设计能保证其对DBMS中现有系统组件的修改最小化。另外Lero是利用数十年来查询优化器的经验与知识,而不需要额外的冷启动学习成本。Lero可以通过探索不同的优化方向并学习准确地对它们进行排名来快速提高查询优化的质量。
二.方法介绍
2.1 系统概述
Lero是一个learning-to-rank查询优化器,它不断探索不同的查询计划,观察它们的性能,并学习更准确地对它们进行排序。Lero采用pairwise方法,其目的是预测两种计划中哪一种更有效。
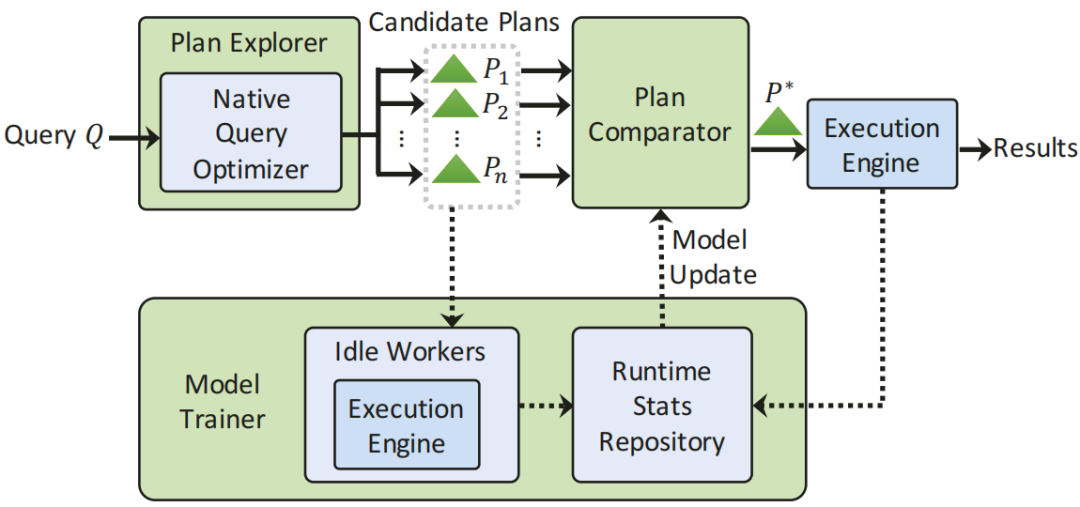
图1 系统结构图
图1显示了Lero的整体架构。对于每个输入查询Q,plan explorer与native query optimizer一起生成许多可能良好并且多样化的候选计划P1、P2、…、Pn,然后调用pairwise plan
comparator model并在候选计划中选择最佳计划P*。在系统后台,model trainer在系统资源可用时使用空闲workers执行其他候选计划,将延迟信息收集到运行时状态存储库中,并持续训练comparator model并定期更新它。这种设计使comparator model能够不断地训练,并随着时间的推移变得更好,而不会影响正常的数据库服务。下面简要介绍这三个组成部分:
Plan Comparator Model:形式上,设CmpPlan(P1,P2)是一个比较查询的任意两个计划的函数。这里的comparator model就是学习上述CmpPlan的模型。更具体地说,这里以(Pi,Pj,label)的形式组织训练数据集(例如来自运行时状态存储库),用于每个查询的所有对执行计划,其中标签表示两个中哪个计划更好。
Plan Explorer:对于查询,plan explorer生成n个不同的候选计划。当comparator选择的最佳计划返回并执行查询时,model trainer将使用其余候选计划来改进模型。plan explorer为每个查询生成更多的计划,在将子查询的基数估计输入到native查询优化器的成本模型中以生成不同的候选计划之前,会有意地scaled up/down。各种不同质量的的计划也增加了候选计划的多样性,以训练comparator模型。
Model Trainer:对于每个查询, trainer执行由plan explorer生成的其它候选计划,并将它们的计划信息和执行统计信息添加到运行时状态存储库中。这些信息进一步用于训练和更新comparator model。通过这样做,Lero能够尽可能多地探索新的计划空间,并从潜在的错误中吸取教训。
2.2 模型设计
Plan comparator模型的整体模型架构如图2所示。它由plan embedding layers和comparison layer组成。
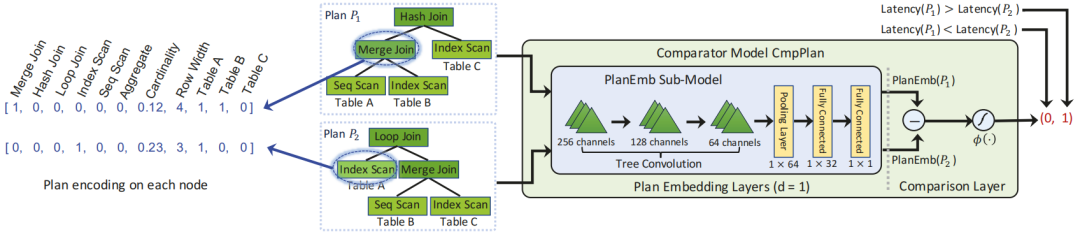
图2 查询计划比较模型结构
plan embedding layers可以有效地捕获查询计划的所有关键信息,包括表、操作符和计划结构属性等,comparison layer比较两个计划的embeddings,并计算它们在计划质量方面的差异,以进行比较。
plan embedding layers:将P1和P2从原始特征空间映射到一维空间,以了解计划之间的差异。子模型PlanEmb从每个计划提取特征并生成其嵌入表示PlanEmb(Pi)。CmpPlan中的两个组件PlanEmb(P1)和PlanEmb(P2)共享相同的模型结构和可学习参数。
Comparison Layer:plan embedding模型与CmpPlan一起学习,通过对计划进行pairwise comparisons,用二元标签表示每组计划哪个更好。在CmpPlan的comparison layer中,计算两个计划的差值x=PlanEmb(P1)-PlanEmb(P2),然后使用激活函数φ(x)=(1+exp(-x))-1生成模型的最终输出。最后,以PlanEmb()的最小值作为执行的最佳计划。

Loss Function:CmpPlan的目标是最大化在任意两个计划之间输出正确顺序的可能性,以便选择最佳计划。损失函数如下公式所示。
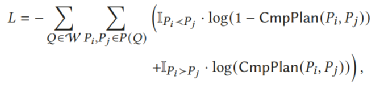
2.3 模型训练
模型不是从头开始训练,而是首先在合成工作负载上离线预训练comparator model,以继承native query optimizer及其cost model的知识。然后,使用在实际执行查询计划期间收集的训练数据,在真实工作负载上对其进行持续的在线训练和更新。
(1)Pre-training
在离线训练阶段使用候选计划的估计成本对comparator model进行训练,候选计划是在特定训练阶段从查询的样例工作负载中生成的。预训练后, PlanEmb(P)是原生估计成本PlanCost(P)的近似值。因此,该模型在开始时被引导执行与查询优化器类似的操作。随着越来越多的查询被执行,CmpPlan不断得到改进和调优,以适应可能的动态数据分布和随时间漂移的工作负载。
预训练PlanEmb(P)的目标是以一种与数据无关的方式学习这些函数,以便处理任何看不见的查询。这样可以完全地使用合成工作负载预训练PlanEmb(P)。即在不同的表上随机生成一些具有不同特征的计划,并将其作为训练数据并将它们输入到本地cost model中(不执行计划),以获得估计的计划成本作为标签。由于cost models通常属于一类结构简单的函数,因此模型预训练收敛速度很快。
(2)Pairwise
Training
在线阶段,Lero在pairwise comparison框架中训练和更新comparator
CmpPlan。对每个查询Q,它的候选计划由plan explorer生成,在系统资源可用时,这些计划由空闲workers执行,执行信息收集在运行时状态仓库中。然后根据损失函数,为每个查询构建n(n-1)个训练数据点,对每个pair(i,j)构建数据点和标签。
接下来使用SGD optimizer周期性地使用上面构造的训练数据集通过反向传播来更新CmpPlan和PlanEmb。对于子模型PlanEmb中的参数,因为它们在PlanEmb的两个副本中共享,分别输出PlanEmb(Pi)和PlanEmb(Pj),所以这里将共享参数的两个副本的梯度加在一起,以更新模型PlanEmb中的参数。
三.计划探索策略
3.1 计划探索目标
Lero的plan explorer为查询Q生成候选查询计划列表,有两个目标。一是关于查询优化的目的,Lero应用comparator model在候选执行计划中确定最佳计划。因此,候选计划必须包括一些真正好的计划供考虑;二是关于计划探索的目的,Lero优先为查询探索其它有希望的计划。通过执行计划并pairwise比较它们的性能,Lero能够捕获过去的优化错误,并使用新观察到的运行时信息及时调整模型。Lero会考虑其它足够多样化的计划以学习新的计划空间,并随着时间的推移改进模型。
现有的探索方法有两种:1)为每个查询探索有效计划的随机样本,这被应用于一些基于强化学习的方法。2)通过调整一组提示或规则来禁用/强制产生某些类型的优化规则来探索计划。
3.2 cardinality作为计划探索的旋钮
Lero使用cardinality estimator作为plan explorer的调优旋钮。在Lero的plan explorer中,通过多次调优(放大或缩小)估计的cardinality,以生成不同候选计划的列表。C()表示cardinality estimator,对于查询Q的子查询Q',C(Q')计算一个基数估计。有别于在成本模型中调用C(),这里要求查询优化器调用一个调优过的预估器,它将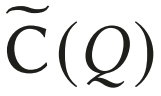 生成一个不同的计划。通过将不同的调优过的预估器输入到成本模型中,query optimizer将生成不同的计划作为候选列表。使用cardinality estimator作为调优旋钮有以下优点:
生成一个不同的计划。通过将不同的调优过的预估器输入到成本模型中,query optimizer将生成不同的计划作为候选列表。使用cardinality estimator作为调优旋钮有以下优点:
首先,在基于成本模型的查询优化器中,cardinality估计决定了估计的成本,从而确定了表和子查询上的连接顺序和物理操作。因此,在计划执行的相同资源预算下,调优cardinality估计极有可能在候选计划中引入多样性,可能使用表的不同的连接顺序或不同的操作符。
其次,基数调优与平台无关。对于大多数DBMS,存在系统提供的接口来修改估计cardinality,这对系统部署十分友好。
3.3 基于优先级的启发式方法
文章的启发式方法的关键思想是优先探索本地优化器可能犯错误的地方,而不是像暴力破解策略那样同时探索所有可能性并调优所有子查询的cardinality估计。该方法主要关注k个表上大小为k的子查询的cardinality估计错误(在每次都有对应每个不同的k≥1)。算法如图3所示。

图3 查询探索策略
Plan explorer的一个重要目标是产生多样化的候选计划。在图4介绍了一些典型案例的示例,plan explorer鼓励候选计划的多样性用于连接四个表的查询,A⋈B⋈C⋈D。
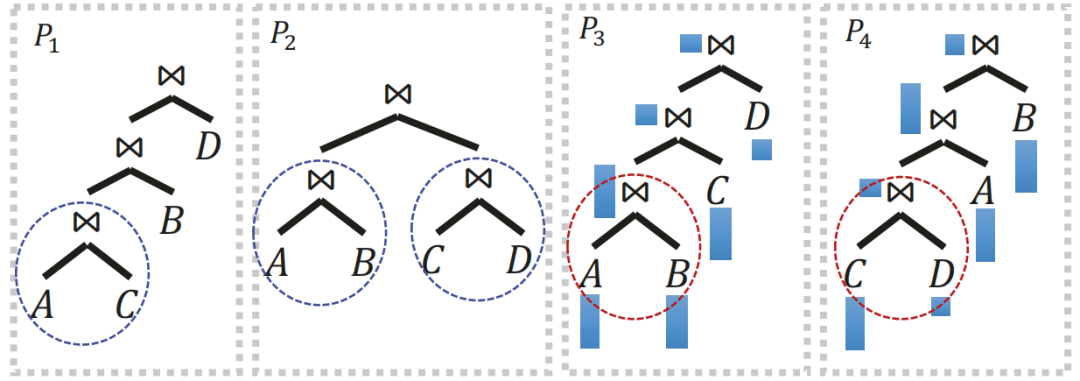
图4 plan explorer生成多样性查询计划实例
四.实验
实验设计主要验证关于Lero表现的一些关键的问题:与PostgreSQL的本地查询优化器和其他学习的查询优化器相比,Lero在查询执行性能上能取得多大的改进?Lero的查询优化成本是多少?Lero能否适应动态数据的工作负载? 然后,实验将检查Lero中的设计选择和设置,并了解它们如何影响Lero的性能:提出的计划探索策略是否高效和有效?它与其他策略相比如何?如果空闲资源更少或有限,Lero还能实现类似的性能提升吗?
总的来说,与Bao、Bao+和PostgreSQL的优化器相比,Lero实现了最好的性能。它的性能接近STATS, TPC-H和TPC-DS上最快的计划,如下表所示。
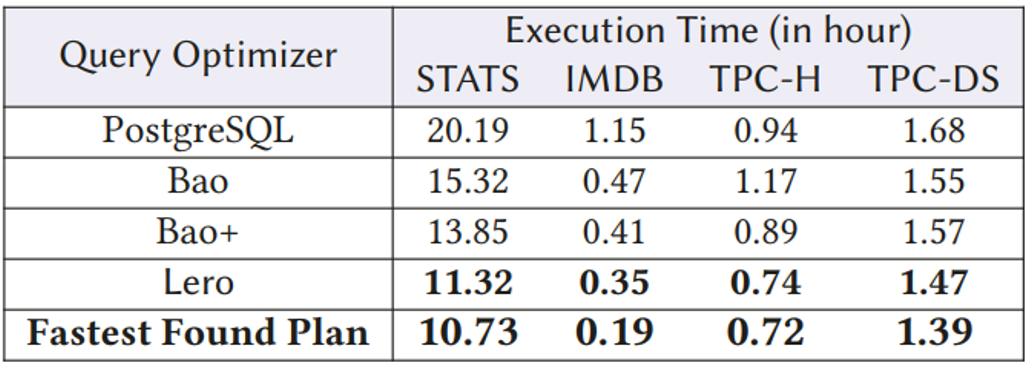
表5 不同查询优化器整体性能
图6比较了每个学习过的优化器(Bao、Bao+和Lero)在146个STATS测试查询上的每次查询执行时间。与Bao和Bao+相比,Lero显著减少了性能回归,并带来了更多的性能提升。

图6 不同查询优化器每个查询世界比较
在图7中,实验测量了学习优化器在为每个工作负载部署后的性能曲线。Lero的训练收敛得更快。随着越来越多的查询被执行,Lero和Bao/Bao+之间的性能差距逐渐扩大。Lero的性能更加健壮。

图7 不同查询优化器性能曲线
在实现查询执行性能的显著改进的同时,Lero花费了额外的查询优化时间为输入查询生成候选计划列表,并应用比较器模型选择最佳候选计划。表8显示查询优化中的额外时间与执行之间相比非常低。
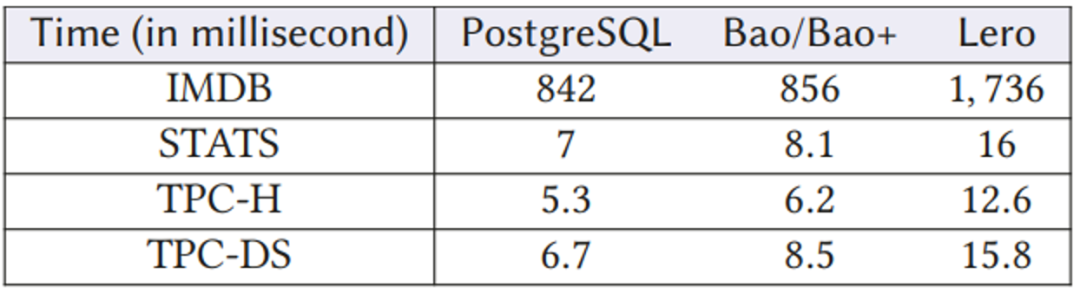
图8 查询优化代价
实验的一个目标是评估不同的学习优化器如何通过更新模型来适应动态数据。在图9展示了每个优化器在动态数据上部署后的性能曲线,以及它们在稳定模型下的性能。在这两种情况下,Lero都优于PostgreSQL、Bao和Bao+。事实证明,Lero比其他两个学习过的优化器更能适应这种数据变化。
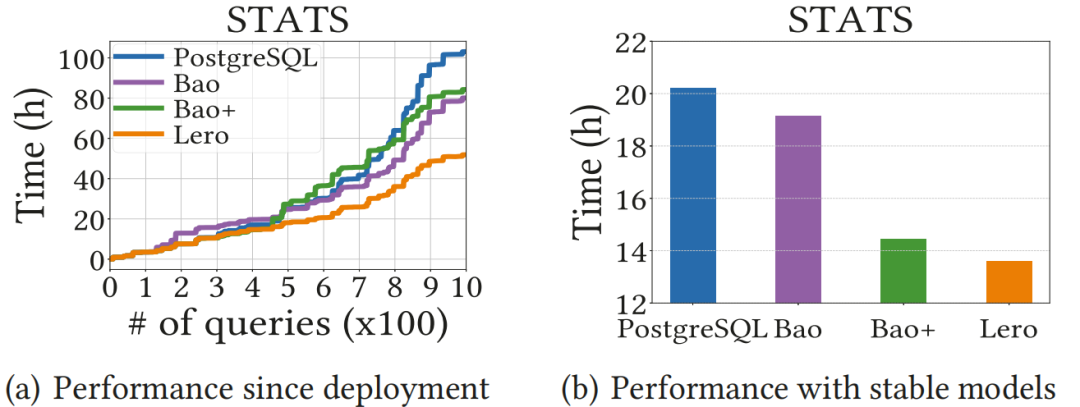
图9 动态数据上优化器性能
除了前文所提到的计划探索策略外,这里还展示了两种替代方法并比较它们的性能:1基于提示集的策略 2)随机生成许多计划的随机策略。Lero的plan explorer为pairwise comparator model生成良好且多样化的计划,以便更有效地探索和学习。
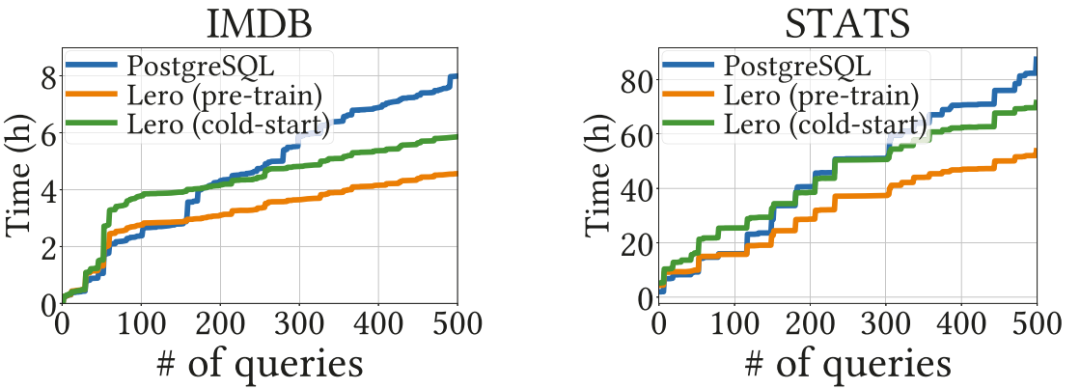
图11展示了lero自部署以来在不同空闲计算资源下的性能表现。这意味着有限的闲置资源肯定会减慢模型的学习和收敛速度,但对Lero的最终性能影响不大。
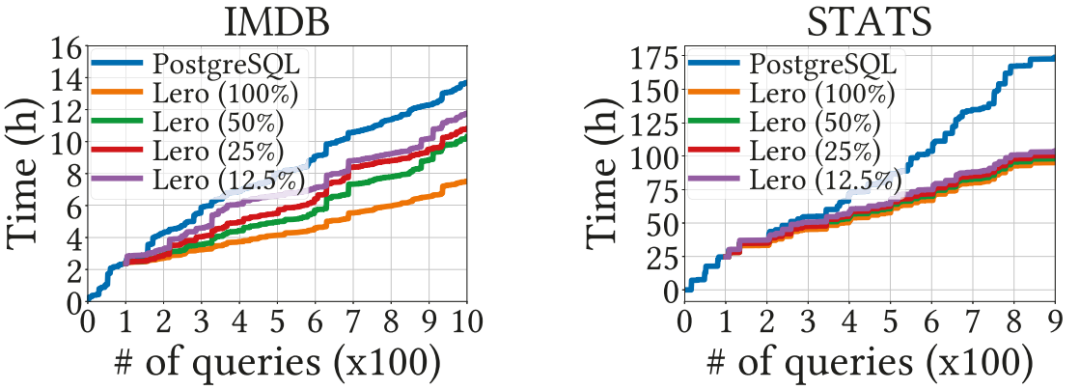
图11 lero在不同空闲资源下的性能曲线
五.总结
本文提出了Lero,一个learning-to-rank的查询优化器。Lero将learning-to-rank机器学习技术应用于查询优化。就查询优化而言,开发机器模型来预测准确的执行延迟或基数是多余的。相反,Lero采用pairwise 方法来训练一个二元分类器来比较任何两个计划,这种方法被证明是更高效和有效的。其次,Lero利用历史的数据库研究知识,与native 查询优化器共同提升优化质量。第三,Lero采用计划探索策略,能够更有效地探索新的优化机会。
最后,文章也进行了广泛的实验和评估,证明了Lero在查询性能方面的优势,以及它适应不断变化的数据和工作负载的能力。
本文作者 李佳俊 |  |




