旋钮调优在数据库优化中起着重要作用,通过调优旋钮设置能够优化数据库性能或提高资源利用率。然而,在大数据时代,数据库实例越来越多、场景越来越复杂、数据量越来越大,导致传统的优化技术已经难以满足大数据的需求,因此近些年提出了许多新的方法来解决这个问题。本次为大家带来最新收录在CCF A类期刊TKDE上的论文:《Automatic Database Knob Tuning: A Survey》。
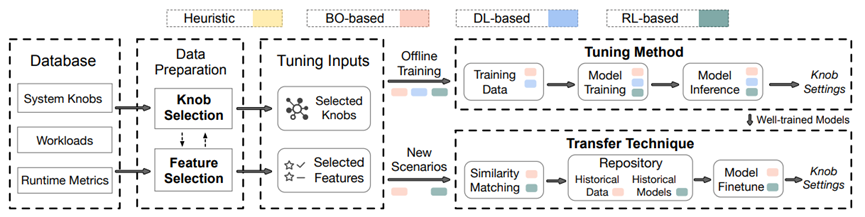
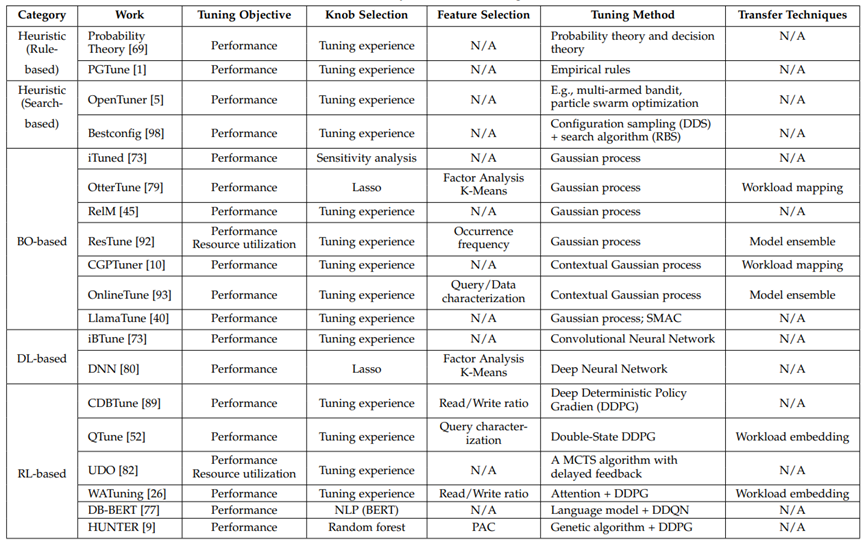
配置旋钮(knobs)控制着数据库系统的许多方面(如查询优化器、底层支援管理),旋钮值的不同组合会显著影响系统的健壮性、性能和资源使用。一般来说,旋钮调优的目的是通过有效地调整旋钮的值,以满足某些调优目标。例如,数据库内存管理由各种配置旋钮控制,如:共享缓冲区大小和后台进程空间等,适当调优这些旋钮可以避免频繁的磁盘I/O,提高数据访问效率。传统上,旋钮调优依赖于数据库管理员(DBA)手动尝试典型的旋钮组合,这往往是非常耗时的,并且不能适应大量的数据库实例。为了解决这些问题,研究人员尝试设计调优方法,能够自动探索不同场景的旋钮设置。旋钮调优问题具体可以分解为四个基本问题:(1)调优的目标是什么?(2)调什么?(3)用什么调?(4)如何调?针对问题一,调优的目标有两个方面,一方面用户需要配置数据库以获得高性能(如吞吐量、延迟);另一方面数据库供应商要求在不牺牲性能的前提下,提高资源利用率(如I/O和内存使用)或降低维护成本。此外,一种调优方法的优劣通常可以从四个方面进行评估:性能、开销、适应性以及安全性。针对问题二,由于数据库系统中有数百个旋钮,调优所有的旋钮可能需要消耗大量的系统资源,因此,选择能够显著影响性能的重要旋钮至关重要。但是如何评估旋钮与性能表现的关系和如何针对不同调优任务选择不同旋钮是选择旋钮过程中所需要面临的两个重要挑战。针对第三个问题,需要用多样化的特征来刻画调优需求,具体来说就是选择一些可能影响调优性能的特征(如工作负载、数据库状态、硬件环境)来反映数据库的执行行为(如写操作的脏页更新、读操作的缓冲区共享)。针对第四个问题,在过滤掉大部分旋钮和不相关的特征之后,配置空间(即所选旋钮的所有候选配置)仍然可以很大。然而传统的经验方法可能只会发现导致性能提升的次优旋钮设置,此外传统方法不知道实际场景中的各种调优目标和约束,这可能会浪费大量资源,因此基于场景特征和调优目标进行智能化推荐旋钮的设置至关重要。一般来说一个配置不可能对所有调优任务都是最优的,大多数现有的机器学习模型不能直接用于新的调优任务,并且需要很长时间从头开始训练,因此将历史调优任务上训练好的模型迁移到新任务上的技术也非常关键。论文广泛回顾了现有的调优方法,并介绍了它们如何回答上述四个问题并解决存在的挑战。图1展示了自动化数据库调优的总体工作流程,其包含四个主要模块,即旋钮选择、特征选择、调优方法和迁移技术。旋钮选择对应前文提到的问题二,即要调什么(配置旋钮)。从广义上讲,“配置旋钮(configuration knobs)”表示数据库中值可以调整并可能对数据库性能产生影响的的旋钮,具体可以分为7类:Access Control、Query Optimizer、Query Executor、Background Processes、Resource (CPU)、Resource (Memory)以及Resource (Disk)如图2所示。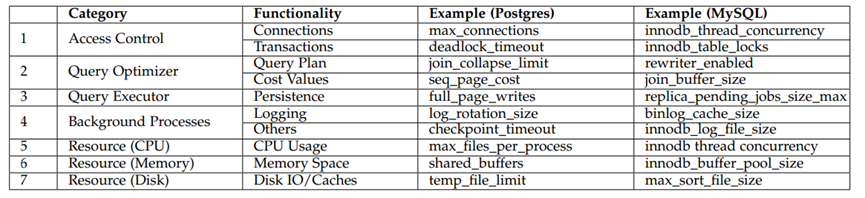
图 2 配置旋钮类型
在众多的系统旋钮中,有些旋钮可以通过不同的机制显著影响性能。例如,有的旋钮(如并发控制)可以直接影响数据库性能;而有些旋钮(如后台进程管理)可能通过减少不必要的维护操作而间接影响性能。目前大多数数据库都有数百个旋钮,其中只有一小部分旋钮可以在数据库性能调优中发挥主要作用。传统的旋钮选择方法依赖于DBA来选择重要或者合适的旋钮,这给DBA带来巨大的负担,一些新的方法被提出来解决这个问题,可以分为基于经验的方法和基于排名的方法。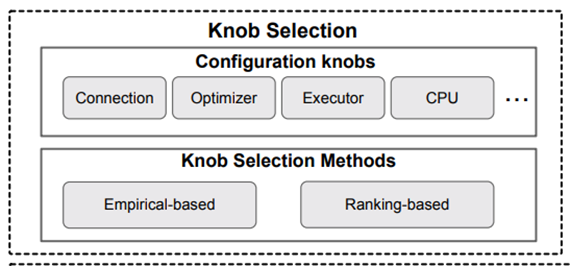
图 3旋钮选择
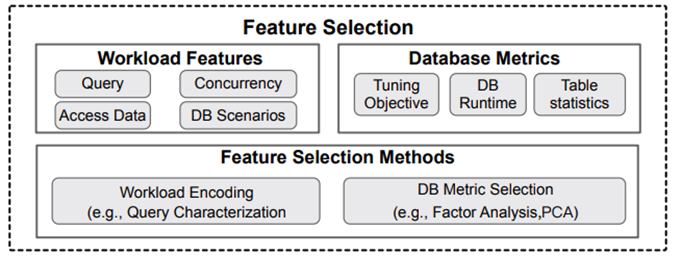
基于经验的旋钮选择要求人根据调优文档或经验来选择旋钮,这种方法相对简单,更值得信任,因为每个旋钮都是经过手工验证的。但是它也存在明显的局限性。首先,人类难以识别各种旋钮之间的复杂相关性(某些旋钮的最大值可能依赖于其他旋钮);其次,单纯依赖人的经验可能会忽视对系统性能有潜在影响的旋钮;此外,调优经验可能跟不上数据库系统频繁的版本更新。基于排名的方法根据对旋钮对数据库性能的影响对旋钮排序,并选择影响较大的旋钮。基于排名的方法包括配置样本收集和旋钮排序。第一步收集一些旋钮设置样本及其在工作负载上的性能表现,第二步对旋钮进行排序。这种方法的优点是可以找到几个显著影响数据库性能的旋钮,但也仍存在一些挑战。首先,基于排名的旋钮选择方法需要找到旋钮于性能之间的关系,旋钮有数百个,选择的旋钮只占很小一部分,这可能会引入偏差;其次如果基于排名的方法遗漏了一些重要旋钮,就会影响调优性能;最后,预选旋钮无法处理动态场景,因为不同的场景可能需要不同的重要旋钮。特征选择模块回答了问题三(用什么调),即决定选择哪些合适的调优特征来反映数据库的执行行为。诸如工作负载特征等各种特征可能会影响数据库性能,选择调优特征(如工作负载、数据库状态和硬件环境)来表征目标调优需求至关重要。调优特征包括工作负载特征和数据库运行时状态。不同的组件会影响不同工作负载的性能。例如,对于访存密集型工作负载,调优与内存相关的旋钮可能会提高性能,而其他旋钮可能会产生较小的影响。因此,表征工作负载以定位相关的组件并优化相应的旋钮是至关重要的(例如,增加高并行查询的并发阈值)。基于现有的调优工作,决定不同工作负载调优需求的主要特征分可以分为:查询特征、并发特征和数据特征。查询特征包括使用的查询运算符、关键字、查询结构(简单查询、具有多连接的复杂查询、相关子查询)、查询成本。并发特征包括并行级别和读写比率,其隐式地表明了访问冲突的级别。被访问的数据特征包括表的大小和数据统计。另外大多数数据库系统提供大量数据库指标来反映执行状态,其大致可以分为三类:调优目标指标、数据库运行时指标和表统计。调优目标指标反映了数据库性能(如延迟和吞吐量)或资源使用情况。数据库运行时度量涉及数据库状态指标和查询状态指标。运行时状态指标反映了数据库的执行状态(如读磁盘块的数据);查询状态指标反映提交给数据库的查询的执行状态。表统计信息用于反映数据分布、规模。配置旋钮调优的目的是找到满足用户要求的最佳旋钮设置,因此可以将旋钮调优问题简单定义为:给定一个工作负载和一套可调旋钮,在预定义的目标和约束条件下选择最优的旋钮设置。现有的研究可以分为四类:启发式、基于贝叶斯优化、基于深度学习、基于强化学习。
图 5调优方法
基于启发式的方法大致分为基于规则和基于搜索两类。基于规则的方法借助手动调优的思想,从经验中构建规则并指导之后的调优过程,其无法适应工作负载和数据量的变化。基于搜索的方法采用层次搜索的方法,将旋钮空间划分为几个子空间,并选择性能最好的子空间。基于贝叶斯优化的调优方法采用基于序列模型的迭代算法,使用代理模型(Surrogate Model)来拟合目标函数,并通过迭代观测到的新数据点来更新该模型。基于贝叶斯优化的调优模型中,除了代理模型和采集函数外,还有两个关键模块即模型初始化和数据库特征。代理模型映射了旋钮设置和数据库性能之间的关系,在基于贝叶斯优化的调优工作中,高斯过程是使用最广泛的代理模型。采集函数决定在哪里采样,它选择搜索预测值大的位置或者不确定性大的位置,这样才有可能搜到目标函数的最优解。为了初始化代理模型,贝叶斯优化通常从一些采样的旋钮设置开始,由于采样方法可能找不到良好的初始样本,因此迁移技术可以帮助根据历史数据选择高质量的初始样本。最后,由于在新的场景中,旋钮-性能关系可能会发生变化,因此在调优过程当中需要考虑额外的数据特征,基于已有的工作,其采用特征分为1)旋钮设置特征;2)工作负载/运行时特征;3)底层系统特征。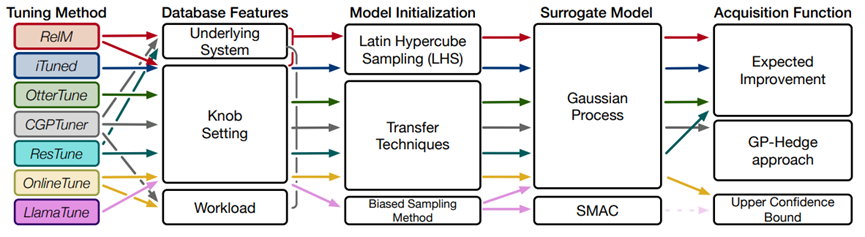
图 6 基于贝叶斯优化调优模型工作流程
除了基于贝叶斯优化的调优方法,基于深度学习的调优方法可以迭代估计和提高调优性能,现有基于深度学习调优方法采用深度神经网络(DNN)作为调优模型,使用ReLU作为激活函数。以前基于贝叶斯优化的方法不考虑资源利用问题,这对于云数据库非常重要,而通过深度学习的构建估计模型可以解决这一问题。与基于贝叶斯优化的方法相比,基于深度学习的方法能有效估计调优性能而不需要重复执行工作负载来评估所选配置,从而减少开销。但是基于深度学习的方法需要大量准备好的样本才能很好地训练调优模型。为了在没有太多历史数据地情况下提高大配置空间的优化模型性能,研究者们提出基于强化学习的方法。强化学习的本质是通过环境和代理之间的相互作用来学习调优策略,基于强化学习的方法将旋钮调优问题中的模块映射到强化学习框架中的六个模块:将调优模型作为Agent,将旋钮调优作为Action,将调优后的性能变化作为Reward,将调优评估模型作为Policy,将数据库作为Environment,将运行时指标作为State。这样,Agent会根据State特征推荐调优动作,并通过Reward更新调优策略以优化数据库性能。基于强化学习的调优方法适用于高位配置空间搜索,但它同时也需要比贝叶斯优化方法高得多的开销。在实际应用场景当中,工作负载可能会动态发生变化,没有单一的旋钮设置能够适应不同的工作负荷,然而,像基于强化学习这样的方法无法有效转移到新的工作负载当中去,需要从头开始训练,这既耗时又耗费了许多系统资源。因此为了适应动态工作负载,迁移技术旨在通过将从历史调优任务中学到的知识迁移到新的调优任务中来提高调优效率。目前研究者们提出的迁移技术包括workload mapping、learned workload embedding以及model ensemble三种。传统的高斯过程方法是对一个新的工作负载随机抽样配置,这往往需要花费很多时间探索。因此有研究者将历史工作负载存储在仓库中,并匹配最相似的历史工作负载来构建初始调优模型。具体来说,workload mapping技术使用从运行时指标中提取的特征向量来表示工作负载,并计算目标工作负载的特征向量与存储库中历史工作负载的向量之间的相似性(例如,欧几里得距离)。workload mapping可以直接匹配大多数相似的历史工作负载,但它有两个局限性。首先,它可能无法从调优库中找到任何类似的历史工作负载;其次,它需要通过执行工作负载来获得工作负载映射的指标信息,这会消耗资源。另一种迁移技术是提取工作负载特征,并将这些特征集成到调优方法当中。例如Li[1]等人提出设计一个workload embedding模型,该模型将工作负载的常见查询特征(例如,操作符类型、查询成本)作为输入,并输出预测的数据库状态变化(例如,读块的数量)。这种方法优势在于,它可以直接提取不同工作负载的调优特征,而不是重复执行。但缺点是,嵌入模型仍然需要大量准备好的训练样本来学习从工作负载到未来数据库状态变化的映射。最后一种转移技术不是与历史工作负载/模型匹配,而是在典型工作负载上准备一组训练有素的调优模型(基础模型),并集成这些模型以泛化未见过的工作负载。它依靠历史模型的加权和来泛化到新的工作负载,这比匹配最相似的工作负载更具有鲁棒性。然而,模型集成的性能很大程度上依赖于所选择的基础模型,即这些模型是否具有足够的代表性。旋钮选择对于调优具有数百个旋钮的数据库系统非常重要。然而对大多数旋钮进行调优,仍然存在一些挑战。一些现有的旋钮选择方法将旋钮-性能关系简化为线性模型,这可能并不准确 (如当旋钮值大于某个数字时,效果不会改变)。其次,基于排名的方法不考虑旋钮之间的关系,而旋钮相关性可以显著影响调优性能(例如,一个旋钮可能是另一个旋钮的阈值)。因此,需要同时考虑单个旋钮特征和它们的协同效应来选择旋钮。在实际场景中,数据库模式、数据和查询可能会不断更新,利用这些更新对模型进行微调是非常重要的。现有的配置调优不能随着数据库的更新而有效地更新旋钮值。确保最佳整体性能和提高系统鲁棒性非常重要。现有的基于学习的方法需要多次重复执行工作负载才能获得执行结果,这对于评估调优性能至关重要。然而,重新运行工作负载可能会很耗时,而且在实际应用场景中并不现实,因此,预测调优性能而不是实际执行工作负载非常重要。虽然一些调优方法对于特定场景效果很好,并且实现了类似场景的泛化能力,但在不同场景下训练多个模型的工作量太大。因此,需要设计一个可以处理典型场景的调优模型。本文回顾了现有的旋钮调优研究,总结了旋钮调优流程中的核心模块,包括旋钮选择、特征选择、调优方法和迁移技术。对于每个模块,这篇文章对相应的解决方案进行了分类,并讨论了它们的优点和局限性。此外,文章也列出了旋钮调优中仍存在的研究挑战和开放问题。这项调查为研究人员提供了更好地了解现有解决方案的设计原理,并提供了未来进一步研究和优化的方向。[1]G. Li, X. Zhou, S. Li, and B. Gao. Qtune: A query-aware database tuning system with deep reinforcement learning. Proc. VLDB Endow., 2019
本文作者 李佳俊 武汉理工大学推免至重庆大学的准硕士生,重庆大学START团队成员。主要研究方向:AI4DB,时空数据挖掘 | |
时空艺术团队(START,Spatio-Temporal Art)来自重庆大学时空实验室,旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!