





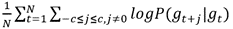 最大。其中,gt为当前单元格,gt+j为gt的相邻单元格,c为相邻单元格数。而两个相邻的单元格应该具有相似的表示形式,该概率可以使用softmax函数计算为
最大。其中,gt为当前单元格,gt+j为gt的相邻单元格,c为相邻单元格数。而两个相邻的单元格应该具有相似的表示形式,该概率可以使用softmax函数计算为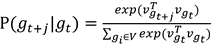 ,其中,vgt表示gt的向量表示。
,其中,vgt表示gt的向量表示。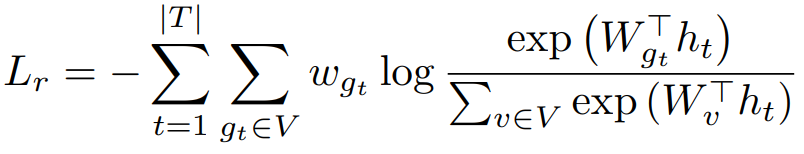 。其中,WT是将ht从潜在空间投射到词汇表空间的投影矩阵,Wgt为单元格权重,计算公式为
。其中,WT是将ht从潜在空间投射到词汇表空间的投影矩阵,Wgt为单元格权重,计算公式为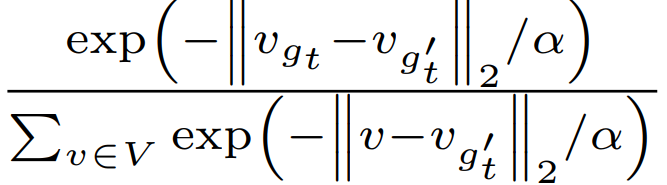 ,gt和g't表示预测的单元格和真实单元格。vgt和vg't是他们对应的向量表示。为了在不影响性能的情况下降低计算成本,这里使用的范围是g't的k个最近邻,而不是词汇表V中的所有单元格。
,gt和g't表示预测的单元格和真实单元格。vgt和vg't是他们对应的向量表示。为了在不影响性能的情况下降低计算成本,这里使用的范围是g't的k个最近邻,而不是词汇表V中的所有单元格。 。的初始估计,第三阶段通过自我训练,我们可以迭代地改进整体聚类,细化轨迹聚类分配,使聚类更具鉴别性。主要由以下四个部分构成。
。的初始估计,第三阶段通过自我训练,我们可以迭代地改进整体聚类,细化轨迹聚类分配,使聚类更具鉴别性。主要由以下四个部分构成。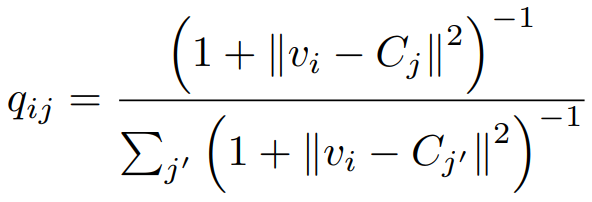 ,qij表示将轨迹Ti分配给簇j的概率。
,qij表示将轨迹Ti分配给簇j的概率。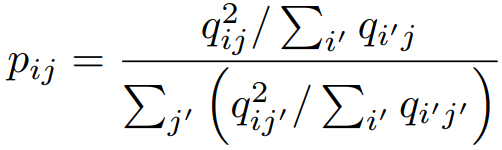 。
。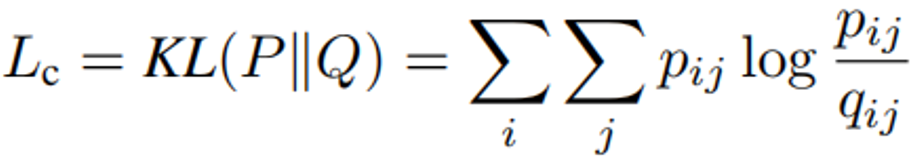 。并且,利用Adam随机梯度下降联合优化聚类质心Cj和神经网络参数θ,以最小化聚类损失。
。并且,利用Adam随机梯度下降联合优化聚类质心Cj和神经网络参数θ,以最小化聚类损失。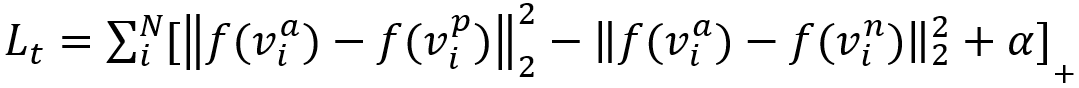 。其中,via是嵌入轨迹作为anchor,vip是via周围的噪声点作为positive,vin是其余的点作为negative。
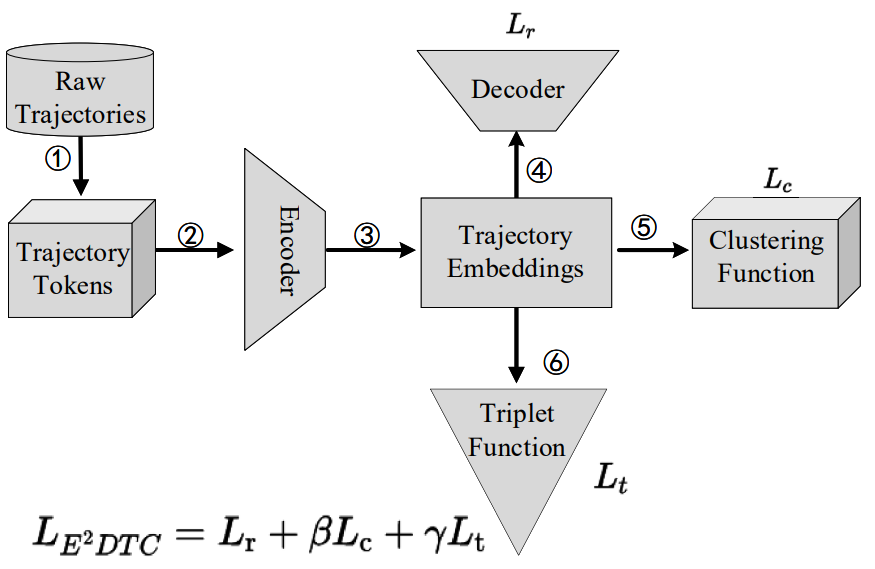
。其中,via是嵌入轨迹作为anchor,vip是via周围的噪声点作为positive,vin是其余的点作为negative。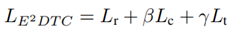 ,Lr捕获了输入的隐藏特征,Lc促进了形成聚类结构的表示,而Lt增强了编码器的聚类能力。
,Lr捕获了输入的隐藏特征,Lc促进了形成聚类结构的表示,而Lt增强了编码器的聚类能力。
文章转载自时空实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
