Spark等大数据分析平台在处理和分析大规模数据方面发挥着重要作用。然而,Spark的配置调优一直是困扰开发者和数据分析师的难题。由于Spark应用程序代码结构复杂、执行时间冗长、应用场景多样,传统的配置调优方法难以有效应对这些挑战。本次为大家带来数据库领域顶级会议ICDE的文章《Adaptive Code Learning for Spark Configuration Tuning》,针对上述问题提出了LITE系统。随着大数据时代的到来,数据规模呈现爆炸式增长,如何有效地管理和分析海量数据成为企业和科研机构的共同挑战。大数据分析平台应运而生,它们能够高效地处理和分析大规模数据,为各行各业提供决策支持和洞察力。其中,Apache Spark 作为一款开源、分布式的大数据处理平台,凭借其易用性、高性能和强大的生态圈,已经成为大数据分析领域的主流工具之一。然而,Spark 的配置调优一直是困扰开发者和数据分析师的难题。Spark 提供了丰富的配置参数,例如 executor.cores、executor.memory 等,这些参数的设置会直接影响应用程序的性能。然而,由于 Spark 应用程序代码结构复杂、执行时间冗长、应用场景多样,手动调优方法难以有效应对这些挑战。传统的配置调优方法及其主要存在的问题如下:1. 基于规则方法:依赖于专家经验和领域知识,缺乏通用性和可扩展性,难以适应不同的应用场景和数据规模;2. 基于实验方法:通过反复执行应用程序并测试不同的配置参数,效率低下,难以在短时间内找到最优配置;3. 基于成本方法: 建立成本模型来预测应用程序的性能,难以捕捉代码语义与配置参数之间的复杂关联;4. 基于机器学习的方法:需要大量的训练数据,且难以适应新的应用程序和数据规模。为了解决这些问题,本研究提出了LITE系统,一个基于机器学习的 Spark 配置自动调优系统。针对上述问题,本文提出了LITE系统,通过轻量级的自动调优方法,将小型数据集上的学习知识迁移到大型数据集,实现高效的Spark配置调优;同时,提出了NECS模型,利用代码和调度器特征,捕捉代码语义与配置参数之间的复杂关联,实现更准确的性能预测;最后,还提出了自适应模型更新和自适应候选生成方法。其中,自适应模型更新通过对抗学习,根据新收集的反馈数据 fine-tune 模型,提高模型在大型数据集上的泛化能力,自适应候选生成则是动态调整搜索空间,减少调优开销,提高调优效率。LITE (LIghtweighT knob rEcommender) 系统是一个基于机器学习的 Spark 配置自动调优系统,旨在解决 Spark 应用程序配置调优的难题,下图便是LITE的总体样貌: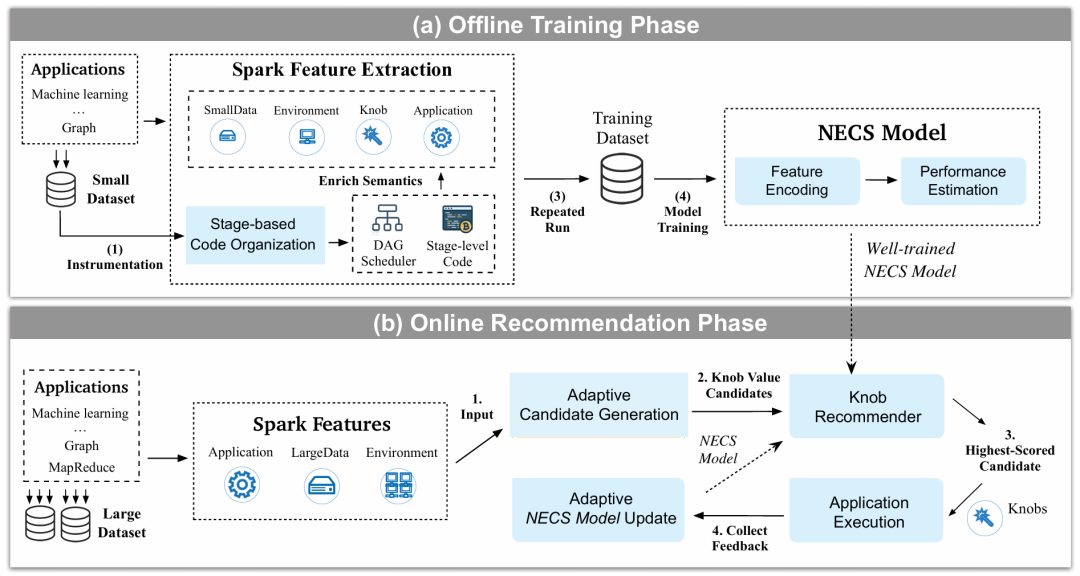
LITE 系统通过以下几个关键组件和技术实现高效的配置调优。
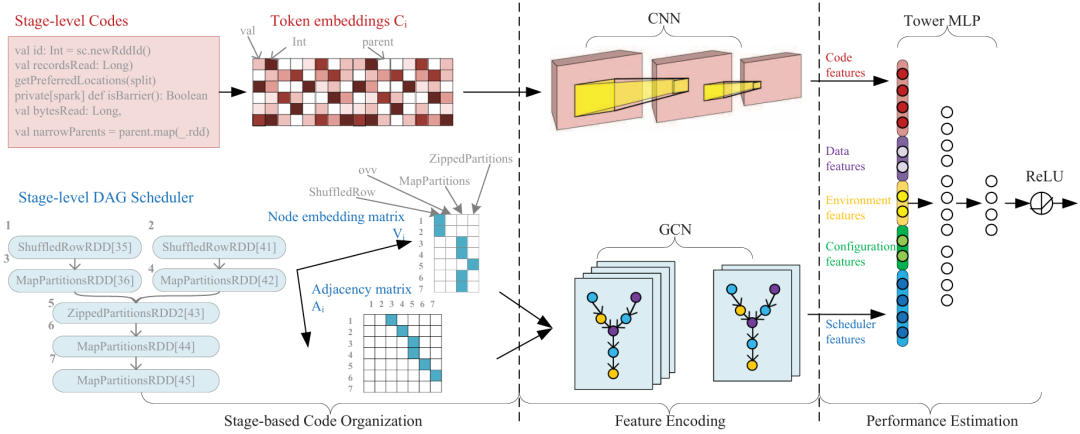
NECS (Neural Estimator via Code and Scheduler representation) 模型是 LITE 系统的核心组件之一,它利用代码和调度器特征来预测 Spark 应用程序的性能。NECS 模型的主要目标是解决 Spark 配置调优中的代码语义复杂性问题,即如何捕捉代码片段和操作符之间的复杂关联,并将其与配置参数联系起来。NECS组成成分包含三个部分:Code Encoder, Scheduler Encoder, Performance Estimator。其中Code Encoder利用 CNN (卷积神经网络) 对代码特征进行编码,捕捉代码片段和操作符之间的局部依赖关系;Scheduler Encoder 利用 GCN (图卷积神经网络) 对调度器特征进行编码,捕捉代码片段之间的长距离依赖关系;Performance Estimator 则利用 MLP (多层感知器) 对编码后的特征进行建模,预测不同配置参数下的应用程序性能。NECS的训练过程也可以总结为四部分:收集训练数据,编码特征,训练Performance Estimator,评估模型性能。其中,收集训练数据主要收集Spark应用程序的代码、调度器特征和执行时间,作为训练实例;编码特征则是利用Code Encoder和Scheduler Encoder对代码和调度器特征进行编码,得到编码后的特征向量;训练Performance Estimator则是利用编码后的特征向量作为输入,训练相关的估计模型,使其能够预测不同配置参数下的应用程序性能;最后利用测试数据评估 NECS 模型的预测精度和泛化能力。 总的来说,NECS模型是一个基于代码学习的Spark应用程序性能预测模型,它能够捕捉代码语义与配置参数之间的复杂关联,实现更准确的性能预测。NECS模型的应用可以帮助开发者和数据分析师解决Spark配置调优的难题,提高Spark应用程序的性能,降低配置调优的成本,提高数据分析的效率。LITE系统的在线推荐组件主要负责在运行时根据待调优Spark应用程序的特征,推荐最优的配置参数,该组件包含一下几个关键步骤:收集程序特征,生成候选配置,评估候选配置,推荐最优配置,模型更新。其中,收集程序特征主要收集代码,调度器,环境,数据等相关特征。在完成特征收集之后,根据这些相关特征,在线推荐会预测合适的的配置参数范围,并从中随机采样候选配置。具体来说,在线推荐利用随机森林回归模型,根据应用程序的特征和训练数据,预测每个配置参数的合适范围,然后根据配置参数的预测范围,扩展搜索空间,确保覆盖所有可能的配置参数组合,最后就是从扩展后的搜索空间中随机采样候选配置。候选的参数配置会进行相关评估,然后将最优的配置作为推荐配置并返回给以用户,用户可以根据推荐配置运行Spark应用程序。最后就是模型更新阶段,模型将会收集新收集的反馈数据,并利用自适应模型更新方法fine-tune NECS模型,提高模型在大型数据集上的泛化能力。
表2 应用数据集:应用名, 类型, 训练集、验证集、测试集的输入数据大小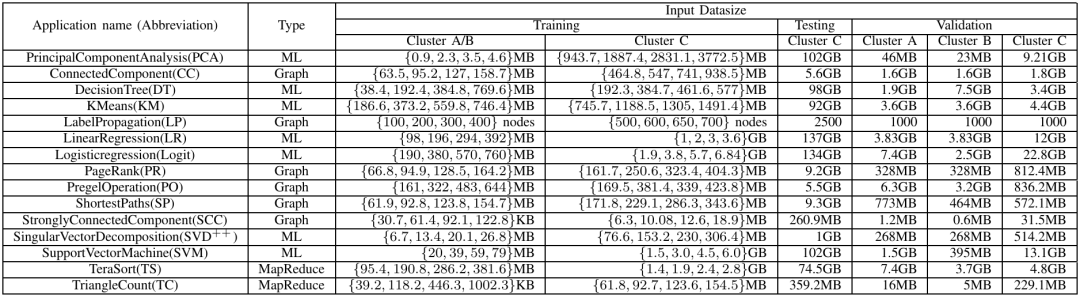
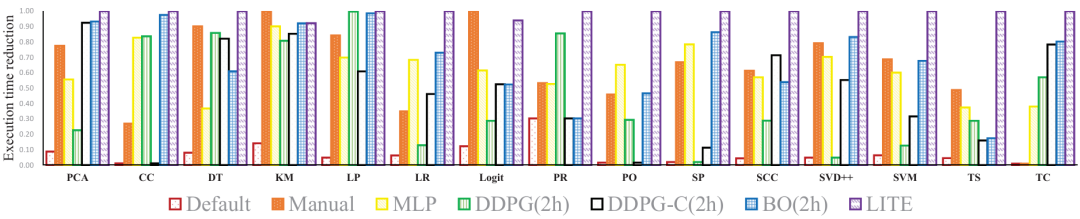
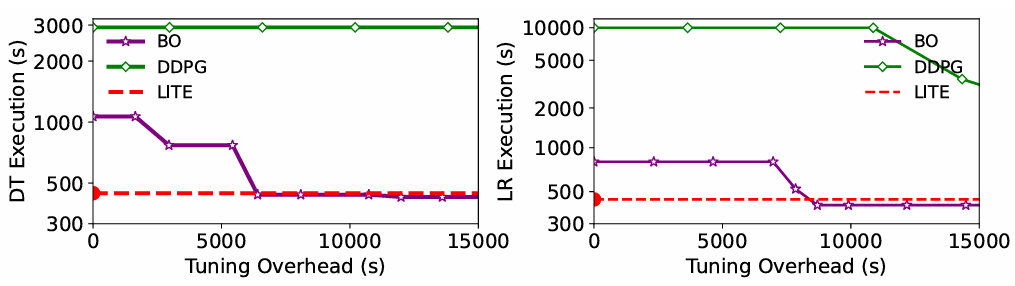
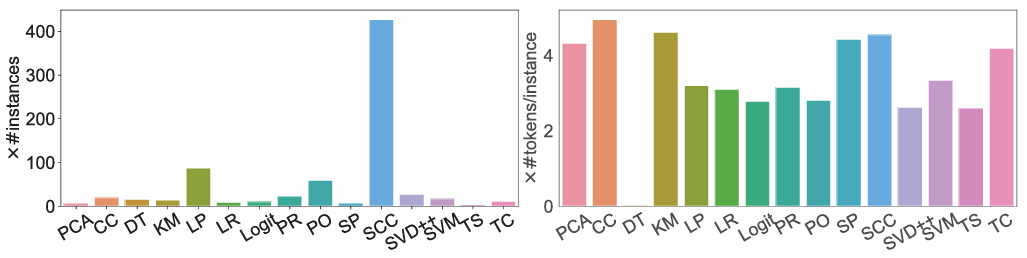
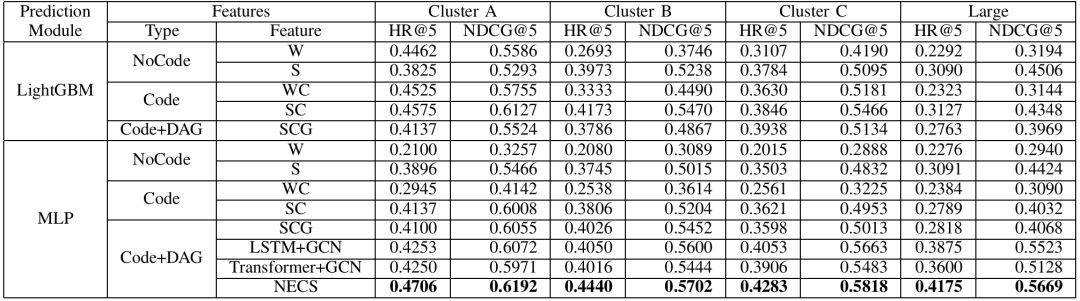
使用Spark-bench基准测试套件中的 15 个应用程序,涵盖了机器学习、图计算和批处理等多种类型,评价指标则为使用Execution Time Reduction (ETR)和HR@5/NDCG@5等指标评估配置调优的效果。图3 不同方法下每个应用的ETR(执行时间缩减,越大越好)图4 调优DecisionTree和LinearRegression:调优性能 vs 调优开销从中可以看出与默认配置、手动配置、MLP、BO、DDPG和DDPG-C等基线方法相比,LITE系统在 Execution Time Reduction (ETR) 方面取得了更好的结果,表明 LITE 系统能够显著提高 Spark 应用程序的性能。除此以外,与BO和DDPG等基线方法相比,LITE系统的在线推荐时间更短,表明 LITE 系统能够更高效地找到最优配置参数。如上表所示,与 MLP、LightGBM、Transformer、LSTM和GCN等基线模型相比,NECS模型在HR@5和NDCG@5等指标上取得了更好的结果,表明NECS模型能够更准确地预测不同配置参数下的应用程序性能。实验结果表明,LITE系统能够有效地解决Spark配置调优的难题,提高Spark应用程序的性能,降低配置调优的成本,提高数据分析的效率。LITE系统的创新性技术方案为Spark配置调优领域带来了新的突破,具有广泛的应用价值。总的来说,LITE系统的优势可以提高Spark应用程序的性能,通过自动寻找最优配置参数,LITE系统可以显著提高Spark应用程序的执行效率,缩短执行时间,降低资源消耗;通过降低配置调优的成本,LITE系统可以自动完成配置调优过程,减少人工干预,降低配置调优的成本;通过提高数据分析的效率,LITE系统可以快速找到最优配置参数,从而降低相关消耗。
苟书祥 重庆大学计算机科学与技术(卓越)专业2021级本科生,重庆大学Start Lab团队成员。主要研究方向:时空数据挖掘 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!
图文|苟书祥
校稿|李 政
编辑|朱明辉
审核|李瑞远
审核|杨广超