





论文考虑了一个具有N个客户端的一般联邦学习模型,目标是最小化所有客户端的加权平均目标函数,其中每个客户端的局部目标是最小化经验风险。在联邦学习中,数据分区不能在各方之间共享,只有中间结果被通信到中央服务器进行优化,并且数据可以是非IID的。论文的解决方案基于FedAvg框架,但FedAvg框架没有解决非IID数据问题,论文通过引入分布正则化来明确考虑在非IID数据上的学习。
论文假设每个客户端的数据来自相同的分布,但分布在客户端之间有所不同。为了有效地学习不同扭曲的数据分布,论文提出将这些分布投影到一个公共空间,使得投影分布之间的距离最小化。论文采用最大平均差异(MMD)的经验估计作为客户端数据分布之间的距离,并通过添加一个新的局部目标来修改标准联邦学习模型,该目标明确捕获客户端之间的成对数据分布差异。优化这个模型需要新的联邦学习算法,因为直接应用FedAvg会导致高通信成本,并且在优化这个模型时也无法保证收敛。
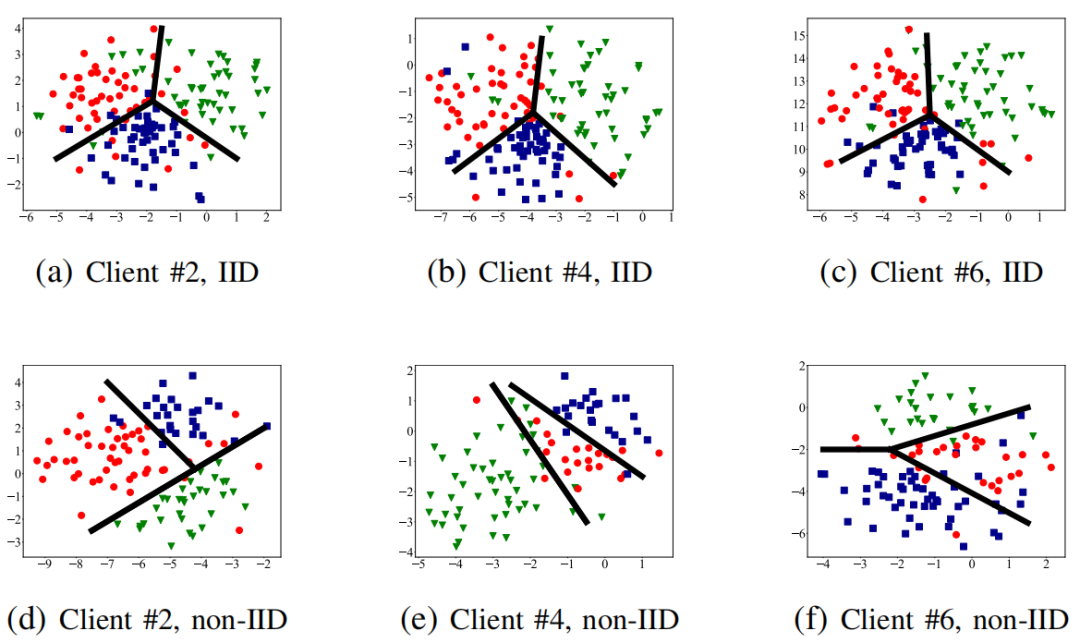
优化目标由标准联邦学习目标和分布正则化项组成。标准联邦学习目标可以通过FedAvg等通信高效的算法进行优化,但精确计算正则化项需要在每对客户端之间进行额外的通信来计算成对的MMD距离,这会导致至少
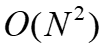 的通信开销。
的通信开销。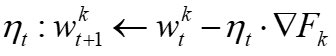 ,批量大小为B,进行E步。之后,中央服务器通过对它们进行加权平均来聚合本地模型,即
,批量大小为B,进行E步。之后,中央服务器通过对它们进行加权平均来聚合本地模型,即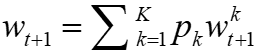 。在FedAvg中,采样比例SR、本地步骤数E和小批量大小B共同控制计算和通信开销。当SR = 1且E = 1时,FedAvg简化为标准的同步分布式SGD。
。在FedAvg中,采样比例SR、本地步骤数E和小批量大小B共同控制计算和通信开销。当SR = 1且E = 1时,FedAvg简化为标准的同步分布式SGD。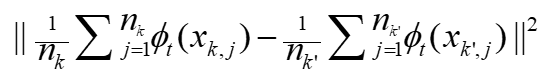 。rFedAvg的基本思想是使用延迟映射来避免这种全局通信。具体来说,论文定义一个本地映射算子
。rFedAvg的基本思想是使用延迟映射来避免这种全局通信。具体来说,论文定义一个本地映射算子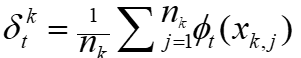 ,这样距离就变成了
,这样距离就变成了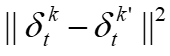 。延迟映射指的是,在t轮的客户端k,论文使用k'在某个之前轮t' < t的本地映射
。延迟映射指的是,在t轮的客户端k,论文使用k'在某个之前轮t' < t的本地映射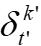 来计算它们之间的距离。本地映射δ的同步遵循FedAvg中的同步,即每E个本地步骤同步一次。
来计算它们之间的距离。本地映射δ的同步遵循FedAvg中的同步,即每E个本地步骤同步一次。 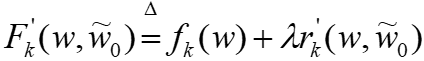 ,
,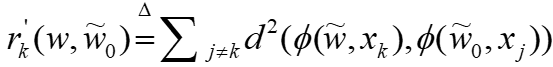 。延迟映射
。延迟映射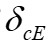 在全局步骤c时由服务器广播,因此在i步后延迟。本地训练后,每个客户端发送他们的
在全局步骤c时由服务器广播,因此在i步后延迟。本地训练后,每个客户端发送他们的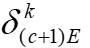 以及本地模型参数到服务器进行聚合和后续通信。
以及本地模型参数到服务器进行聚合和后续通信。
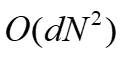 ,因为服务器必须向N个客户端广播N·d维向量的副本。每个延迟的
,因为服务器必须向N个客户端广播N·d维向量的副本。每个延迟的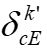 是使用每个客户端的本地模型参数
是使用每个客户端的本地模型参数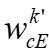 计算的,这可能加剧客户端之间的差异。
计算的,这可能加剧客户端之间的差异。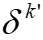 的平均值而不是计算它们之间的距离来减少通信开销。
的平均值而不是计算它们之间的距离来减少通信开销。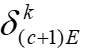 然后将其发送回服务器。这样客户端可以在计算它们之间的距离时达成共识。其次,服务器将使用客户端δ的平均值而不是N维向量δ。因此,通信开销从
然后将其发送回服务器。这样客户端可以在计算它们之间的距离时达成共识。其次,服务器将使用客户端δ的平均值而不是N维向量δ。因此,通信开销从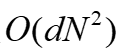 降低到O(dN)。在这种情况下,
降低到O(dN)。在这种情况下,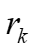 的目标将从
的目标将从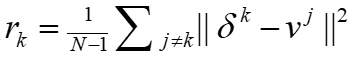 变为
变为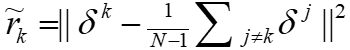 。注意
。注意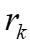 和
和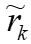 关于
关于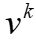 的梯度相同,因此收敛仍然可以保持,而也可以被视为的紧密下界。
的梯度相同,因此收敛仍然可以保持,而也可以被视为的紧密下界。
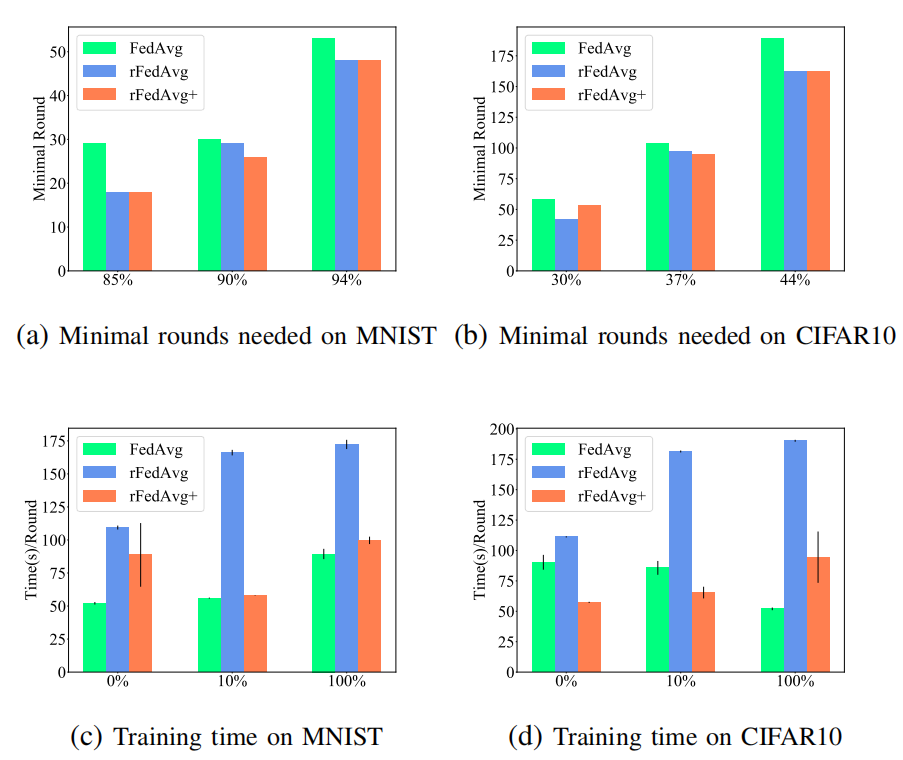
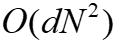 降低到O(dN),尽管客户端需要在每个训练轮中与服务器通信两次。正如论文将在评估中展示的,rFedAvg+在测试准确率方面通常优于rFedAvg,并且每轮训练时间也更高效。还值得一提的是,尽管论文假设所有客户端都参与了rFedAvg和rFedAvg+的描述,但实证研究表明,在部分参与的情况下它们也是有效的。然而,所提出的方法仍然有一些局限性。例如,它们只能缓解数据异质性问题,而不能在极端非IID(即有异常值)的情况下完全解决它。在这种情况下,一个可能的补救措施是首先消除异常值,论文的方法将是可行的。
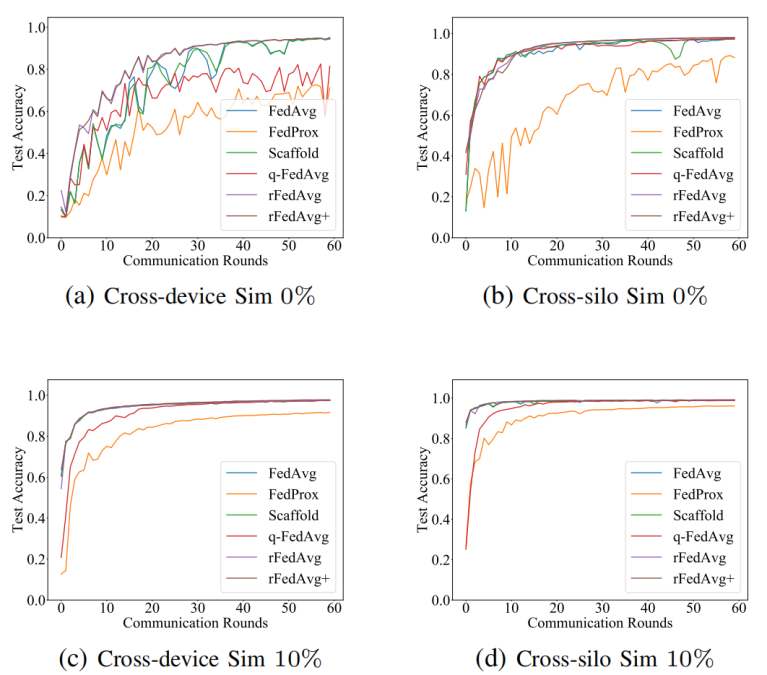
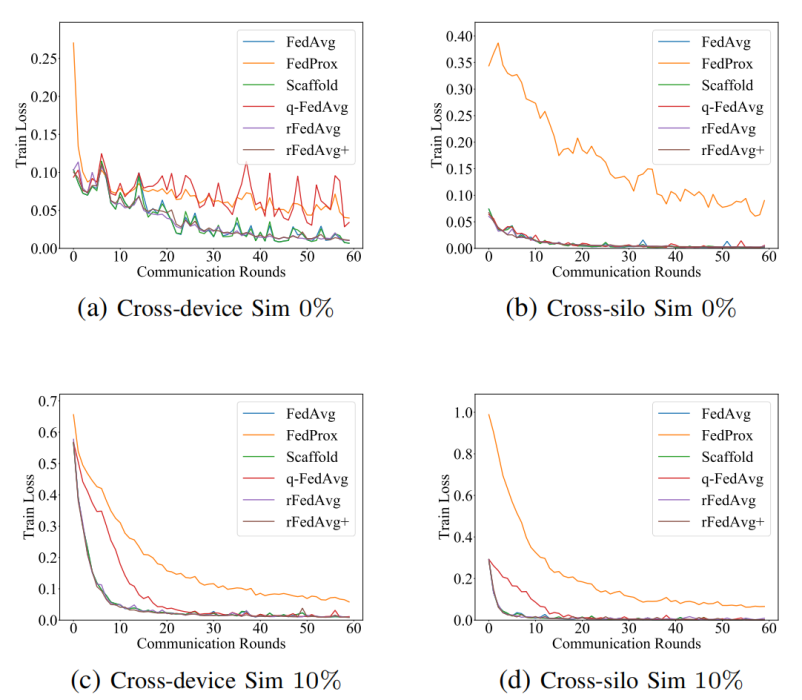
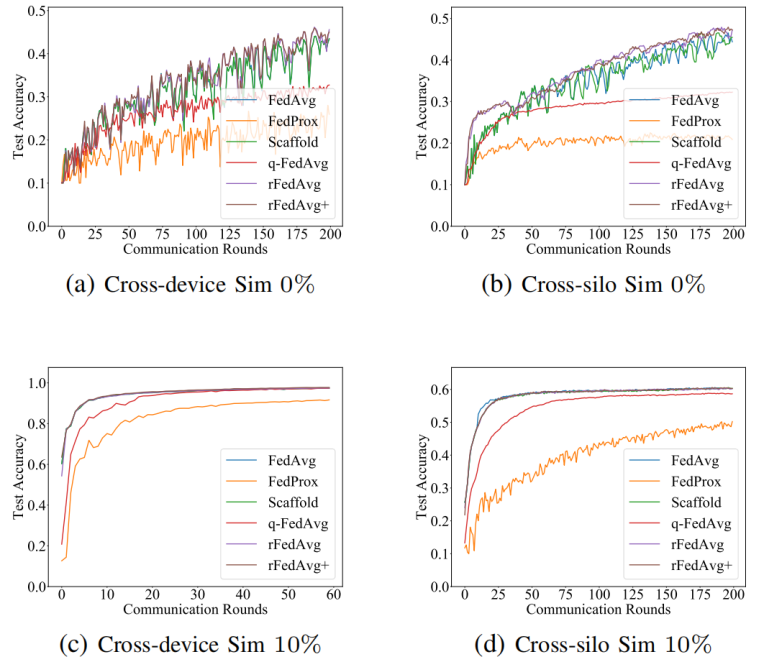
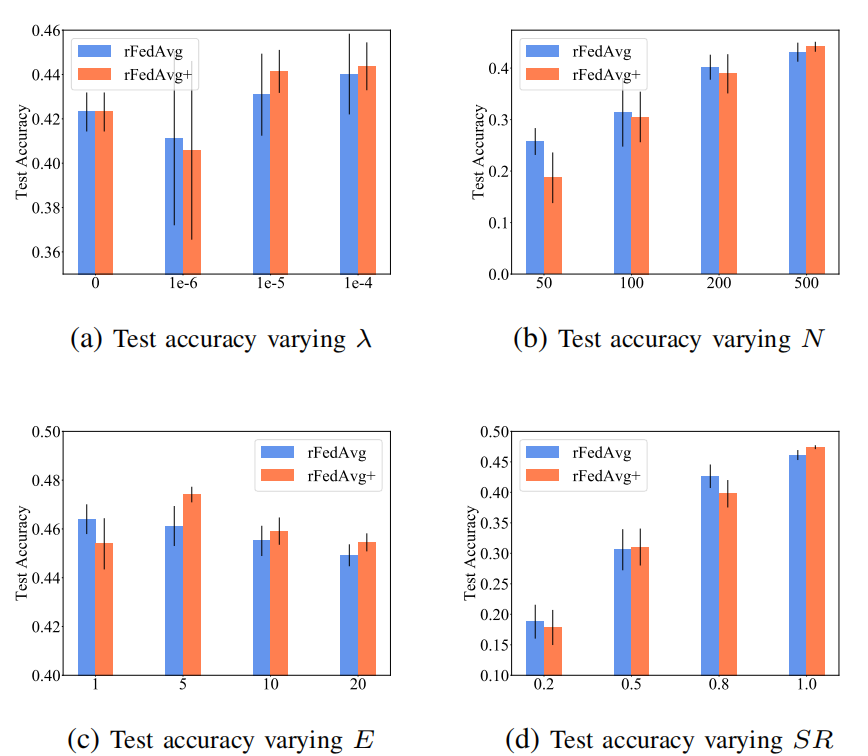
降低到O(dN),尽管客户端需要在每个训练轮中与服务器通信两次。正如论文将在评估中展示的,rFedAvg+在测试准确率方面通常优于rFedAvg,并且每轮训练时间也更高效。还值得一提的是,尽管论文假设所有客户端都参与了rFedAvg和rFedAvg+的描述,但实证研究表明,在部分参与的情况下它们也是有效的。然而,所提出的方法仍然有一些局限性。例如,它们只能缓解数据异质性问题,而不能在极端非IID(即有异常值)的情况下完全解决它。在这种情况下,一个可能的补救措施是首先消除异常值,论文的方法将是可行的。数据集:论文在4个数据集上比较了不同方法的性能,包括MNIST、CIFAR10、Sent140和FEMNIST。


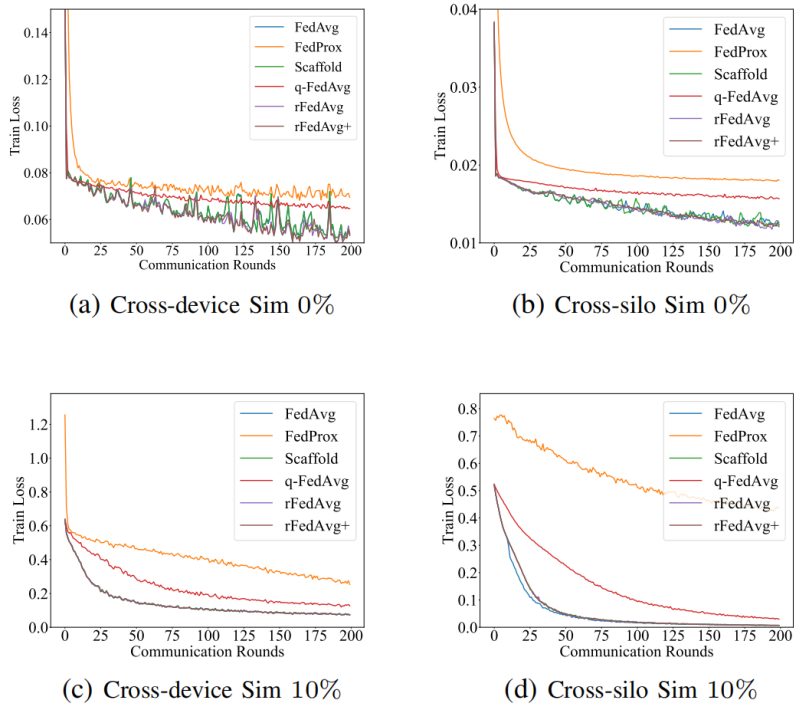
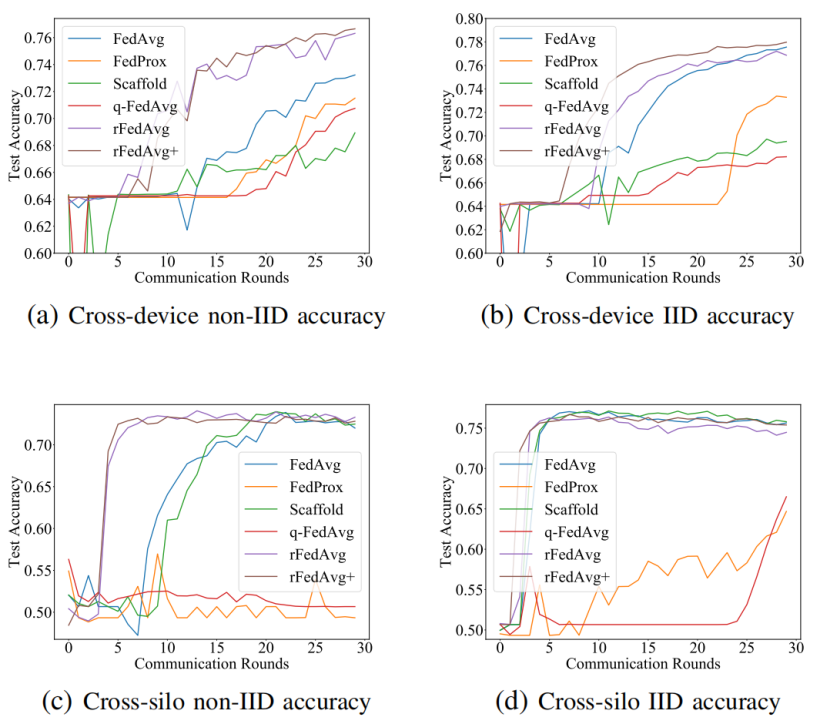
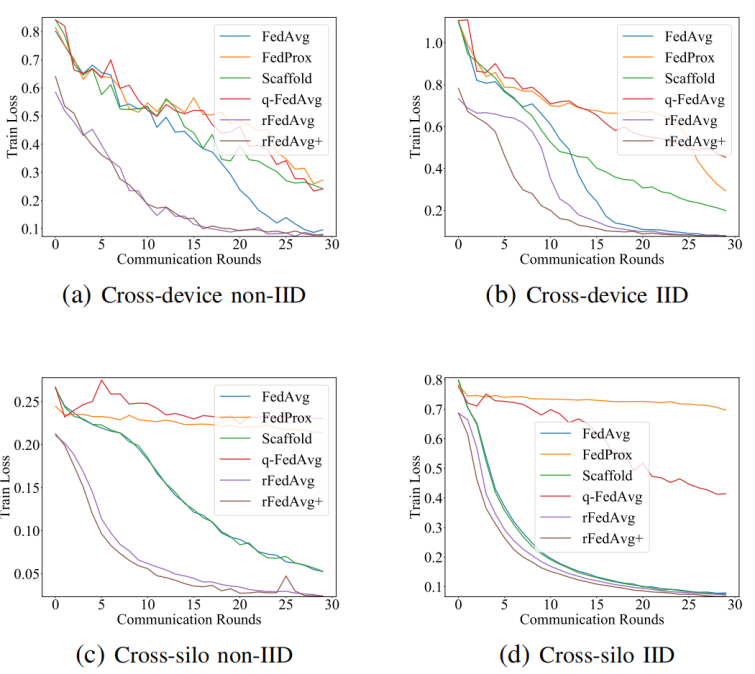
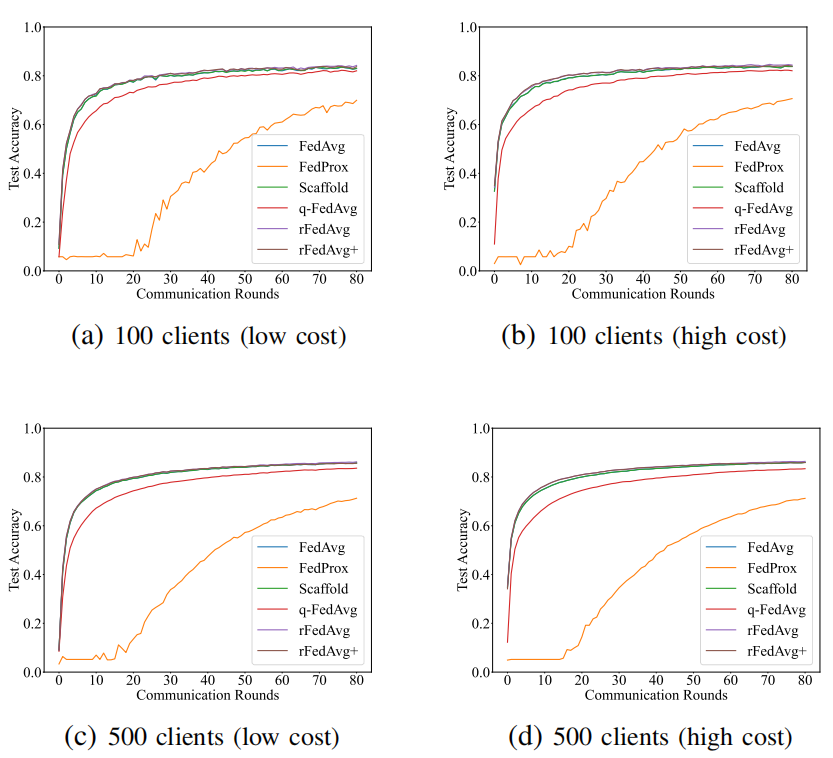
|

重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!

图文|刘明星
编辑|徐小龙
审核|李瑞远
审核|杨广超
文章转载自时空实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
GTS Techlabs与Peacom宣布建立战略合作伙伴关系
全球TMT
37次阅读
2025-03-06 15:02:36
移远通信推出支持边缘计算的QuecPi Alpha开源智能生态开发板
全球TMT
34次阅读
2025-03-05 19:04:25
AI WAN引领IP承载网全面迈进智能化时代,加速运营商业务新增长
全球TMT
31次阅读
2025-03-25 20:33:02
华为全面升级星河AI园区网络解决方案,AI使能以体验为中心建网,共赢AI时代
全球TMT
31次阅读
2025-03-08 15:13:19
全球领袖齐聚2025年巴塞罗那世界移动通信大会,共商网络安全对策,提升客户体验
全球TMT
27次阅读
2025-03-17 16:10:58
[操作系统] 进程间通信:匿名管道原理与操作
DevKevin
24次阅读
2025-03-18 21:29:27
《当人工智能遇上广域网:跨越地理距离的通信变革》
程序员阿伟
21次阅读
2025-03-23 22:50:57
北京移动数据库及一体机维保服务
天下观查
21次阅读
2025-03-11 10:14:26
跟着论文学习数据库6:共识算法
锋哥聊DORIS数仓
18次阅读
2025-03-12 10:23:10
GBASE南大通用中标上海移动网优大数据分析等系统杨浦节点迁移工程项目
GBASE数据库
15次阅读
2025-03-19 11:20:45


