




无处不在的GPS传感器从运动物体中收集大量的轨迹数据,然而,由于轨迹数据量巨大,直接存储和处理原始数据的成本很高。利用轨迹简化,可以将轨迹简化为一组连续的线段,是一种有效的方法。虽然针对此项问题提出了许多算法,但仍然存在许多问题,包括(1)非数据驱动能力(2)计算成本较高。(3)只关注轨迹中的局部信息保存,而未能捕获轨迹压缩的全局移动模式。本次为大家带来数据库领域顶级会议ICDE2023的论文《A Lightweight Framework for Fast Trajectory
Simplification》。

一、背景
随着定位技术的发展,传感器的采样率越来越高(即获取每个运动物体更细粒度的位置),更多被监控的移动物体同时生成大量轨迹数据。使得基于人工智能的轨迹数据分析算法(如相似学习、深度预测等)达到了一个临界点。因此,对轨迹数据的压缩为后续的轨迹分析奠定了基础。现有的轨迹简化算法分min-#(它基于n个点的原始轨迹生成一个简化的轨迹,误差只有轨迹点的误差)和min-ϵ(给定一个有n个点和一个正整数m的轨迹,它找到一个由m个点组成的子序列来近似这个轨迹)两类。对于min-ϵ在早期提出了精确算法(Bellman和Error-Search),但其复杂性较高,不适合大规模轨迹分析。因此,近似算法更受欢迎。近似算法又分非基于学习的方法和以学习为基础的方法,然而,这些算法虽然达到了较高且相当的轨迹简化质量,但效率较低。一方面,非基于学习的方法与基于距离的误差度量紧密耦合,导致计算量大,效率低。而基于学习的方法需要处理巨大的状态空间和大量带有转换的操作,这会带来计算开销。另一方面,它们通常侧重于局部特征的保存,而忽略了上下文感知的全局迁移,导致了粗糙的分辨率和全局迁移趋势的损失。
基于上述问题,该论文提出了一个轻量级框架S3,实现了更高的简化效率和相当的有效性。论文的主要贡献如下:
•提出了第一个基于深度学习的快速轨迹简化框架S3 i)是数据驱动的,ii)以轻量级的方式运行,没有标记数据或错误计算的监督,iii)实现了更高的效率和有效性。
•设计了一个由压缩器和构造器组成的Sequence-to-Sequence-to-Sequence架构,以自监督的方式实现快速轨迹简化。进一步构建上下文感知的GNN,以保持本地和全球移动依赖关系。
•将S3扩展为流设置,因此也可以支持在线轨迹简化任务。
•将S3与离线和在线模式下的非学习和基于学习的基线进行了比较,结果表明S3更高效并且有效。
二、方法介绍
2.1相关定义及符号表示
定义一:点(p)将GPS点p表示为自由空间中的三元(x, y, t),表示在时间t时,运动物体位于二维位置(x, y)。
定义二:轨迹(T)轨迹T是GPS点的时序序列,表示为T = 〈p1, ...,pn〉。
定义三:子轨迹T[i:j]=〈pi, pi+1, ...,pj〉。
定义四:子序列T[si:sj]=〈psi, psi+1, ...,psj〉。
定义五:锚段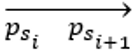 段是原轨迹psi和psi+1之间的任何点的锚段
段是原轨迹psi和psi+1之间的任何点的锚段
定义六:A:邻接矩阵;H:输出矩阵;X:特征矩阵。
2.2 S3总体框架
S3由四个模块组成,即嵌入层、压缩器、构造器和差分层。考虑一个原始轨迹T =〈p1,p2,…pn〉。嵌入层将原序列投射到轨迹嵌入vT=〈g1,g2,…gn〉,然后将其作为压缩器的输入,压缩器基于Seq2Seq以vT生成简化轨迹T’=〈ps1, ps2,
...,psm〉。然后,构造器以简化轨迹T’作为输入,并尝试恢复输入轨迹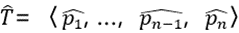 。在前向后神经网络训练过程中,压缩器(T->T’)和构造器
。在前向后神经网络训练过程中,压缩器(T->T’)和构造器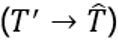 通过T’ 通信,即
通过T’ 通信,即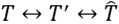 ,该通信由重构损失LR(T,T’)引导。
,该通信由重构损失LR(T,T’)引导。
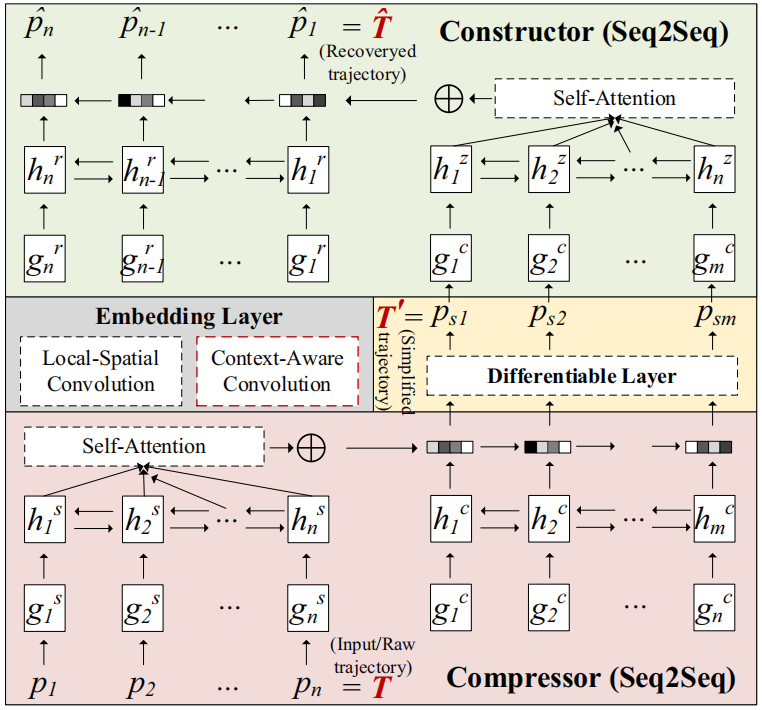
图1 S3整体框架图
•嵌入层:由于神经网络只能采用向量作为输入,给定由真实GPS点组成的轨迹T,需要将其转换为离散标记。因此,论文使用网格划分方法,将整个区域划分成不相连的网格,所有的网格共同组成了V。然后使用skip-gram算法通过最大化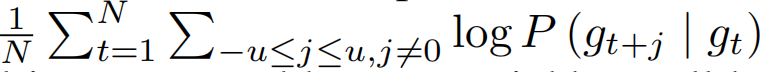 来初始每个单元格的表示。其中当前单元格用gt表示,相邻单元格用gt+j表示,相邻单元格数目用u表示,总单元格数用N表示,gt矢量用vgt表示,由于两个相邻单元格有相似的表示,因此可以使用
来初始每个单元格的表示。其中当前单元格用gt表示,相邻单元格用gt+j表示,相邻单元格数目用u表示,总单元格数用N表示,gt矢量用vgt表示,由于两个相邻单元格有相似的表示,因此可以使用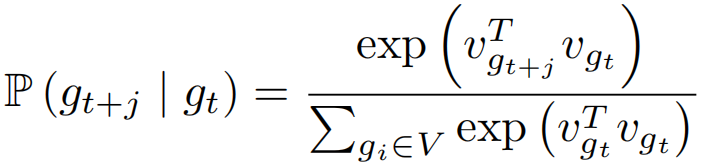 来计算概率。因此,论文得到了空间嵌入vT=〈g1, ··· , gT,
··· ,g|T|〉。
来计算概率。因此,论文得到了空间嵌入vT=〈g1, ··· , gT,
··· ,g|T|〉。
•压缩器
1)Seq2Seq简介:Seq2Seq是一种 encoder-decoder 结构,它将输入和输出分成两个部分来处理,首先 encoder 负责编码 input ,输出一个中间向量 w ,然后将 w 作为 decoder 的输入进行解码,输出一个序列 output 。在编码器和解码器的内部中,通常使用的是循环神经网络。同时使用EOS指示序列的结束,以便使得输入与输出长度不同。因此常使用于NLP任务中。特别的,Seq2Seq是一个条件语言模型,其在输入序列和前导已知的情况下最大化后续目标的概率。具体而言,编码器读取输入序列x,更新RNNs隐藏状态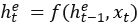 ,,其中e和d用于区分编码和解码阶段。在处理最终的xt后,得到最终隐藏状态ht。使用vx保留输入x的顺序信息。解码器通常还利用RNNtype网络通过
,,其中e和d用于区分编码和解码阶段。在处理最终的xt后,得到最终隐藏状态ht。使用vx保留输入x的顺序信息。解码器通常还利用RNNtype网络通过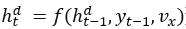 预测当前输出yt。Seq2Seq的目标函数为
预测当前输出yt。Seq2Seq的目标函数为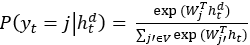 ,其中j为V的可能值,htd通过矩阵Wjt从隐藏状态投影出来。
,其中j为V的可能值,htd通过矩阵Wjt从隐藏状态投影出来。
2)Parallel-Attentive Encoder-Decoder:编码器和解码器都使用双向RNN,如图1所示,给定vt并进行编码得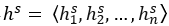 。其中的
。其中的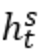 是Bi-RNNs的双向隐藏状态的连接。
是Bi-RNNs的双向隐藏状态的连接。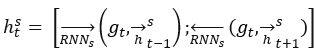 。
。
自注意力机制:在每一步使用一个概率分布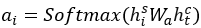 ,以生成上下文感知向量
,以生成上下文感知向量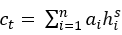 ,其中Wa为参数矩阵。结合ct和解码器的当前状态htc得到pst的概率分布。
,其中Wa为参数矩阵。结合ct和解码器的当前状态htc得到pst的概率分布。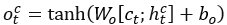
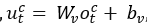
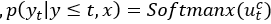 ,其中Wo,bo,Wv,bv均为超参数。解码器的嵌入etc,和htc均通过ct更新。
,其中Wo,bo,Wv,bv均为超参数。解码器的嵌入etc,和htc均通过ct更新。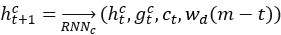 。通过从均匀分布中抽样,得到简化轨迹对每个输入轨迹的目标长度m,根据m生成具有不同压缩比的简化轨迹。其次,文章计算每个点的注意力得分,并存储到HashMap中。自注意部分是完全平行的,例如输入长度为n,可以创建n个线程来完成此步。
。通过从均匀分布中抽样,得到简化轨迹对每个输入轨迹的目标长度m,根据m生成具有不同压缩比的简化轨迹。其次,文章计算每个点的注意力得分,并存储到HashMap中。自注意部分是完全平行的,例如输入长度为n,可以创建n个线程来完成此步。
•差分层
在生成T’时,文章从分布p(pst|T|)中采样它的邻居位置pst,为避免对同一位置的重复采样,在训练和推理过程中将标记每个采样位置。其解决方法是使用峰值softmax函数: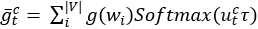 ,在训练过程中将所有词汇表网格嵌入的加权和作为输入传递给压缩器解码器的下一步以及构造器编码器的相应步骤。文章使用Gumbel Softmax,从softmax中取特定的pst样本相当于从Gumbel 分布中减去独立噪声样本ξ中的argmax,并将其逐个添加到logits中
,在训练过程中将所有词汇表网格嵌入的加权和作为输入传递给压缩器解码器的下一步以及构造器编码器的相应步骤。文章使用Gumbel Softmax,从softmax中取特定的pst样本相当于从Gumbel 分布中减去独立噪声样本ξ中的argmax,并将其逐个添加到logits中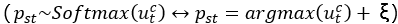 ,因此对峰值softmax函数修改如下
,因此对峰值softmax函数修改如下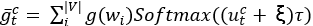 。
。
文章使用基于邻居的采样来选择采样阶段中最邻近的轨迹点。在前向训练阶段,使用pst~Softmax(utc)<->pst=argmax(utc)+ξ离散化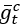 ,使用
,使用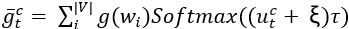 计算后向训练梯度。最后,使用长度向量和每个双向编码器最后隐藏状态的变换来初始化每个解码器的隐藏状态:
计算后向训练梯度。最后,使用长度向量和每个双向编码器最后隐藏状态的变换来初始化每个解码器的隐藏状态: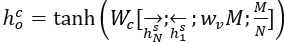 ,其中Wc为一个可训练隐藏层。
,其中Wc为一个可训练隐藏层。
•构造器
构造层的操作与压缩层的操作相对应,其编码器对简化轨迹的位置ps1, ...,psm的嵌入g1c, ...,gmc进行操作。
损失函数:重构损失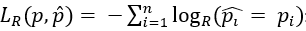 表示构造层对输入轨迹T = 〈p1, ...,pn〉计算的负对数似然(pR为采样分布)。
表示构造层对输入轨迹T = 〈p1, ...,pn〉计算的负对数似然(pR为采样分布)。
2.3 S3的上下文感知拓展
该论文在图神经结构背景下拓展S3以此在轨迹中保留全局移动模式。论文首先构建了一个图来模拟轨迹的上下文感知关系,又提出GNN来学习每个轨迹的初始嵌入。
•图构造:论文利用原始轨迹构建空间图,通过捕获所有轨迹中空间位置之间的相关性来捕获全局依赖性。具体而言,构建上下文感知的空间图G = (V, E), G中的每个节点表示一个网格单元,边缘表示网格单元之间的连通性。如图二所示,如果轨迹包含从gi\gj到gj\gi的连续片段,则在网格单元gi和网格单元gj之间创建边缘。在高采样轨迹中,一些连续的时空点可能被映射到相同的网格单元。在这种情况下,去除g中的自环。边ei,j∈E上的权值定义为包含连续片段(gi\gj<-> gj\gi)的轨迹数。每个节点gi采用一个独热向量来表示其在特征矩阵中的位置唯一性。
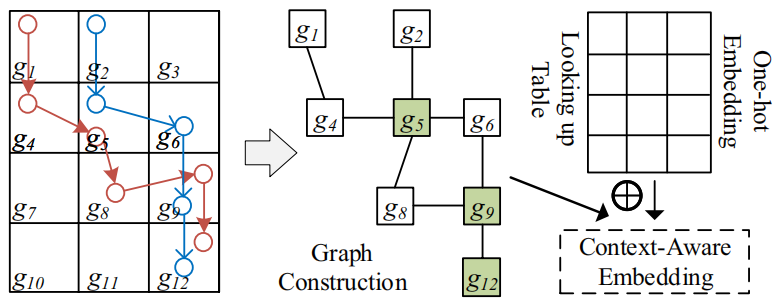
图2 全局移动性嵌入的图示
•上下文感知图卷积
对构建的上下文感知的空间图G进行图卷积运算以获得上下文轨迹嵌入。多层空间卷积网络执行分层传播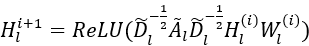 。其中,Wl(i)是特定层的可训练矩阵,
。其中,Wl(i)是特定层的可训练矩阵,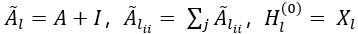 ,其中Xl为G的特征矩阵,Hl(i)为第i层的输出,d为嵌入维数。
,其中Xl为G的特征矩阵,Hl(i)为第i层的输出,d为嵌入维数。
•上下文感知错误距离(CED)
论文定义T与T’的CED距离为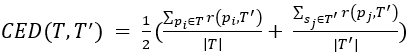 ,其中r(p,T) = maxpi∈T{SC(p,pi)},SC(p,pi) = S(pi,pj)+C(pi,pj),S(pi,pj)表示pi与pj之间的归一化L2空间距离,C(pi,pj)表示pi与pj之间的归一化余弦语义距离。在Hausdorff距离之后,使用max函数,以计算两点集之间的最大不匹配。
,其中r(p,T) = maxpi∈T{SC(p,pi)},SC(p,pi) = S(pi,pj)+C(pi,pj),S(pi,pj)表示pi与pj之间的归一化L2空间距离,C(pi,pj)表示pi与pj之间的归一化余弦语义距离。在Hausdorff距离之后,使用max函数,以计算两点集之间的最大不匹配。
2.4 S3的在线拓展
相比于离线,在线设置中,已经被丢弃的轨迹点不在可访问,需要被简化的轨迹点逐点到达,且对效率要求更高。本文提出S3的两个修改,已进行S3在线拓展。
•当每个点经过compressor时,将其嵌入缓存到哈希表中,该哈希表可以直接与下一个点连接以组成最终隐藏层(复杂度O(n)->O(1))。
•在自注意力层中,采用相同的思路,并使用先前计算的每个输入点的注意力分数,以提高处理新数据的效率。
•图三为在线S3伪代码。对于每个到达的点pi,它首先通过嵌入层中的查找表将该点嵌入到其隐藏向量表示中(第3行)。接下来,它将这个单点嵌入直接连接到之前的序列嵌入中(第4行)。如果嵌入长度超过缓冲区大小W,它使用压缩器和差分层执行轨迹简化(第11-14行);否则,它继续初始化嵌入的轨迹(第6-9行)。

图3 S3在线拓展伪代码
三、实验
3.1实验设置
数据集:考虑到轨迹的特征可能会因移动物体的运输方式而显著不同,使用两种真实数据集来确定算法是否具有适应性。
•GeoLife1包含每个用户三年以上的轨迹,包括多种交通方式(步行、自驾、公共交通)。GPS点周期性采集,每5秒采样91%的轨迹。
•T-drive2包含中国北京10,357辆出租车在7天内的轨迹,采样率在1到177秒之间变化。
基线:对于非基于学习的方法:自上而下,自下而上,Error-Search,STTrace,SQUISH,SQUISH- e。对于基于学习的方法:RLTS。
评估指标:使用PED、SED、DAD和CED进行算法质量评估,并使用运行时间进行算法效率评估。
参数设置:空间网格单元的长度100米。使用了一个三层的GRU作为其基本计算单元。使用最大梯度范数约束裁剪梯度,该文实验中设置为5。使用Adam随机梯度下降训练模型,迭代500次,初始学习率为0.0001。在每种比较方法重复20次之后,给出平均性能。SED、PED、DAD的单位分别为10m、10m、1弧度。对于同一数据集下的不同压缩比,不需要针对每个压缩比训练S3。对于不同的数据集,分别训练S3。在框架的实现中使用了Python和PyTorch。所有的实验都是在一台配备了GeForce GTX-2080
Ti 11G GPU、运行2.40 GHz的英特尔Silver 4210R处理器和16 GB RAM的服务器上进行的。
3.2效果评估
•离线轨迹简化:针对GeoLife1的实验效果如图4所示(图上方为运行效率,下方为有效性)。观察到在PED,SED,DAD评估指标上,Error-Search有着最佳有效性,但运行速度最慢。S3的运行速度最快(S3的框架与大量误差距离计算解耦),但有效性下降较小。在CED指标上,S3有最佳有效性。
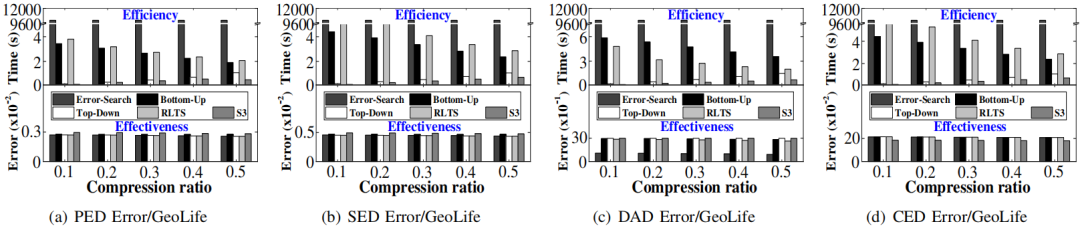
图4 离线设置GeoLife1实验效果
图5为将压缩比固定为0.1,改变轨迹长度以研究简化效率。明显观察到,随着算法长度的增加,运行时间也会增加,但S3具有较高的稳定性,运行效率始终保持较高水准。
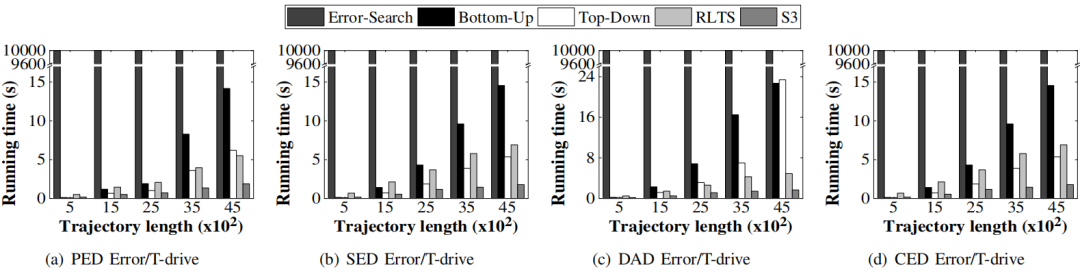
图5 离线设置不同轨迹长度效率
•在线轨迹简化:图6为S3与现有的在线算法在不同压缩比条件下效率与有效性的实验结果以及不同流轨迹长度的单点压缩时间。观察到,S3有着较好的效率增益,在有效性上,除了在CED上误差最小,在其他误差距离上达到了中等效果。
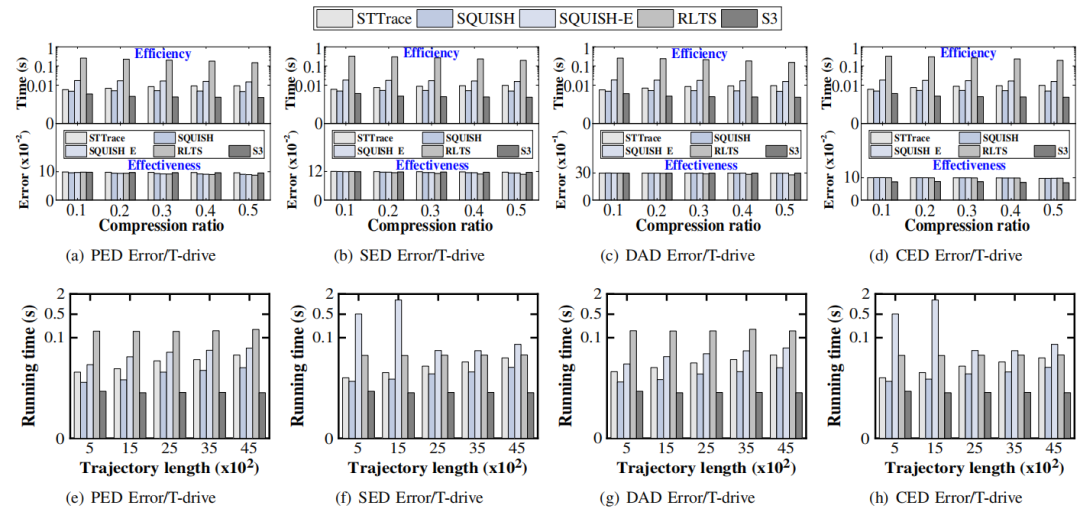
图6 在线轨迹简化效率及有效性分析
•有效性研究:观察上述的在线与离线研究发现,S3以有效性换取效率,使得有效性略有下降。为了证明S3的有效性差距没有影响。论文评估了轨迹简化对后续的轨迹分析任务的影响。如图7所示,论文选择top-k轨迹相似度查询作为评估任务,使用基于点的DTW作为轨迹相似度度量,采用HR@50作为绩效指标。观察到,在相同的比率下,S3的HR@50达到0.8~0.96,基线的则在0.46~0.98.这表明,S3虽没有达到最优的效果,但其质量差距完全可接受。
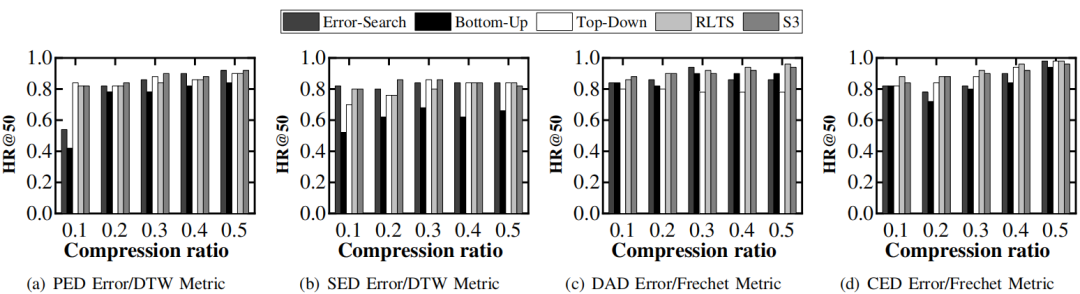
图7 top-k轨迹相似度查询结果
四、总结
论文研究了现有的轨迹简化方法的问题,提出了一个轻量级的基于表示学习的框架,称为S3。S3以端到端方式执行自监督轨迹简化,同时是数据驱动的。并且,其在离线和在线场景下都表现出了较高的效率与质量。
|

重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!

图文|王旭博
编辑|李政
审核|李瑞远


