




摘要
本发明涉及一种数据库学习型索引构建方 法和系统。该方法包括:根据数据关键字和数据 存储位置,构建累积分布函数;利用机器学习模 型拟合累积分布函数,以获取数据关键字与数据 存储位置的关联性,得到学习型索引;根据学习 型索引,快速定位待查询的键值所处的位置。本 发明能够克服现有的B树数据库索引算法调节难 度高自适应能力差、辅助数据结构内存空间占用 偏大的问题,能够有效地减少辅助数据结构的内 存占用、提高数据库索引的自适应调节能力。
1 .一种数据库学习型索引构建方法,其特征在于,包括以下步骤:
根据数据关键字和数据存储位置,构建累积分布函数; 利用机器学习模型拟合累积分布函数,以获取数据关键字与数据存储位置的关联性, 得到学习型索引; 根据学习型索引,快速定位待查询的键值所处的位置。
2 .根据权利要求1所述的方法,其特征在于,
将所述累积分布函数建模为pos=F(key) ×N,其中,F(key)表示累积分布函数,key表示数据键,pos表示数据存储位置,N表示总的数 据规模。
3 .根据权利要求2所述的方法,其特征在于,
所述利用机器学习模型拟合累积分布函 数,是通过机器学习选择合适的累积分布函数即F函数的参数,使得损失函数最小化。
4 .根据权利要求1所述的方法,其特征在于,
所述利用机器学习模型拟合累积分布函 数,包括对键值数据进行分组处理;所述对键值数据进行分组处理包括:预先设定每一组数 据点的个数segmentSize,每读取segmentSize个数据点之后就划分为一组,并拟合一个机 器学习模型,记录模型参数,并以一组数据关键字的最大值和最小值为分界点,以作为分组 依据。
5 .根据权利要求4所述的方法,其特征在于,
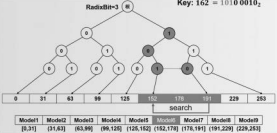
所述根据学习型索引,快速定位待查询的 键值所处的位置,包括:使用根查询表作为辅助数据结构来准确而快速地将待查询键定位 到目标组;所述根查询表基于一个基数树Radix Tree,将前k个二进制位相同的数据键映射 到同一个结点,实现数据键的快速分组定位,其中k是RadixBit即基数树的深度;使用两组 之间的分界点作为根查询表的结点,并且用这些分界点构建数组,称为结点数组,在结点数 组的每个位置存储指针;在每次输入待查询数据键Key时,首先根据基数树定位到结点数组 中的两个结点,再通过二分查找找到结点数组中不小于Key最大值的下标,也即获得对应分 组在数组中的下标,随即完成一次根查询表分组定位过程。
6 .根据权利要求4或5所述的方法,其特征在于,
采用数组长度动态自适应的切分方法 动态地对数组进行切分,所述数组长度动态自适应的切分方法包括以下步骤: 试探性地对最底层同一父节点下的若干数组合并,用一个索引模型代替原有的若干索 引模型,以节省空间消耗; 基于索引模型的平均预测误差这一指标,评价合并的效果,如果误差低于设定阈值则 接受合并,反之则撤销这次合并操作; 自底向上重复合并操作,直至不存在满足合并条件的数组为止。
7 .根据权利要求1所述的方法,其特征在于,
通过引入外接数组支持插入操作、删除操 作,即将插入的元素放置在待插入位置的外接数组中,然后定期将外接数组与原数组进行 整合;在每次进行插入操作时,首先执行查询操作,找到待插入的键对应的位置,即数组中 不大于当前键的最大值所在位置,称其为lower_bound,该位置外接一个固定大小的数组, 并将待插入的键值对放入其中;在查询操作中,首先定位到lower_bound,如果lower_bound 就是待查询的键,就完成一次查询操作,如果lower_bound不是待查询的键,就在其对应的 外接数组中进行查询;当外接数组满时,将该外接数组和原数组进行整合,并进行模型重训 练;进行删除操作时,仍然首先执行查询,找到数据所在位置,同样将该位置标记为空,对所 有标记为空的位置进行整合。
8 .一种采用权利要求1~7中任一权利要求所述方法的数据库学习型索引构建系统,其特征在于,
包括: 累积分布函数构建模块,用于根据数据关键字和数据存储位置,构建累积分布函数; 累积分布函数拟合模块,用于利用机器学习模型拟合累积分布函数,以获取数据关键 字与数据存储位置的关联性,得到学习型索引; 查询模块,用于根据学习型索引,快速定位待查询的键值所处的位置。
9 .一种电子装置,其特征在于,
包括存储器和处理器,所述存储器存储计算机程序,所 述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行权利要求1~7中 任一权利要求所述方法的指令。
10 .一种计算机可读存储介质,其特征在于,
所述计算机可读存储介质存储计算机程 序,所述计算机程序被计算机执行时,实现权利要求1~7中任一权利要求所述的方法。
