




如其名称所示,MySQL中的GROUP BY
子句用于将数据进行分组。它将多行数据聚合为一行。FROM
和WHERE
子句生成一个中间的表结果集,而GROUP BY
子句则系统性地将数据分组。GROUP BY
子句可以按一个或多个列对结果集进行分组。意思是GROUP BY
子句将相似类型的记录或数据分组然后返回。如果在查询中使用了GROUP BY
子句,我们通常应使用聚合函数如COUNT()
、SUM()
、MAX()
、MIN()
、AVG()
等。
当我们实现GROUP BY
子句时,首先表中的数据将根据指定的列划分为不同的组,随后聚合函数将对每个组的数据执行以获取结果。这意味着首先使用GROUP BY
子句将相似类型的数据进行分组,然后在每个组上应用聚合函数以获取所需的结果。
在这篇文章中,我们将通过具体的示例和数据展示GROUP BY
的各种应用。
测试数据准备
我们将创建一个名为employees
的表,并插入一些中文数据。以下是创建和填充数据的SQL脚本:
CREATE TABLE employees (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50),department VARCHAR(50),salary DECIMAL(10, 2));INSERT INTO employees (name, department, salary) VALUES('张三', '技术部', 7500.00),('李四', '销售部', 6000.00),('王五', '技术部', 8000.00),('赵六', '人事部', 5500.00),('孙七', '销售部', 7000.00);复制
执行以上SQL脚本后,我们将得到如下的测试数据:
| id | name | department | salary |
|---|---|---|---|
| 1 | 张三 | 技术部 | 7500.00 |
| 2 | 李四 | 销售部 | 6000.00 |
| 3 | 王五 | 技术部 | 8000.00 |
| 4 | 赵六 | 人事部 | 5500.00 |
| 5 | 孙七 | 销售部 | 7000.00 |
基本的GROUP BY用法
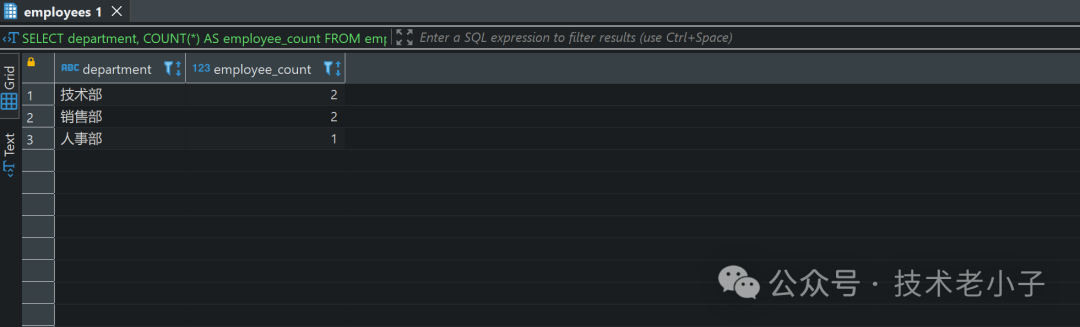
1. 按部门统计员工人数
使用GROUP BY
按部门分组,并使用COUNT
函数统计各部门的员工人数:
SELECT department, COUNT(*) AS employee_countFROM employeesGROUP BY department;复制
结果:
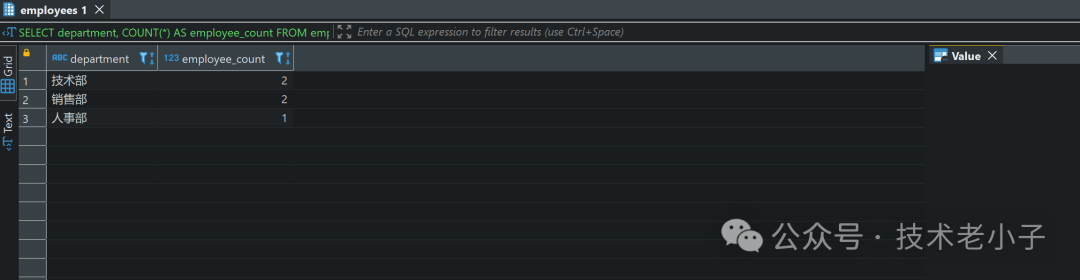
2. 按部门统计总薪资
使用GROUP BY
按部门分组,并使用SUM
函数计算各部门的总薪资:
SELECT department, SUM(salary) AS total_salaryFROM employeesGROUP BY department;复制
结果:
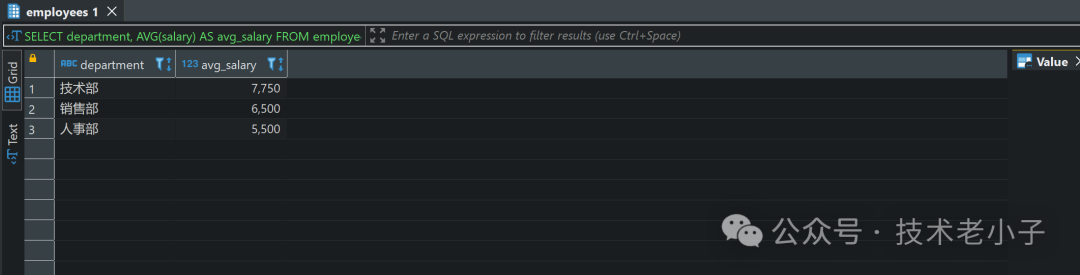
3. 按部门计算平均薪资
使用GROUP BY
按部门分组,并使用AVG
函数计算各部门的平均薪资:
SELECT department, AVG(salary) AS avg_salaryFROM employeesGROUP BY department;复制
结果:
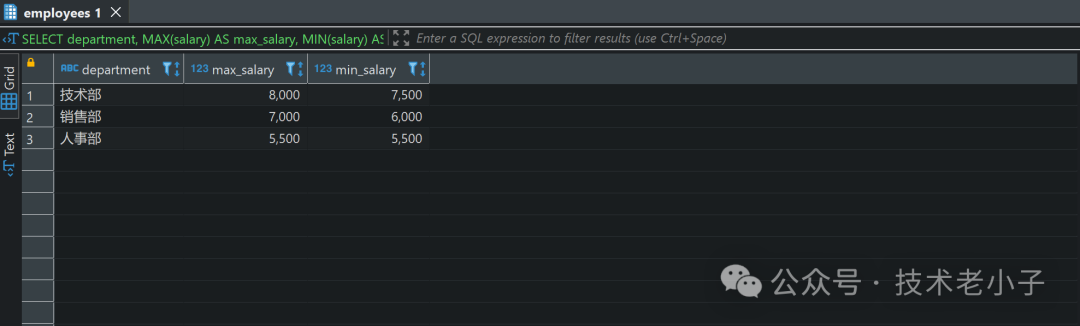
4. 按部门统计最高和最低薪资
使用GROUP BY
按部门分组,并使用MAX
和MIN
函数计算各部门的最高和最低薪资:
SELECT department, MAX(salary) AS max_salary, MIN(salary) AS min_salaryFROM employeesGROUP BY department;复制
结果:
复杂示例:按部门和薪资级别统计
我们还可以进行多列分组,例如按部门和薪资级别统计员工人数。我们先给每个员工定义一个薪资级别,然后进行分组统计。
SELECTdepartment,CASEWHEN salary >= 8000 THEN '高薪'WHEN salary >= 6000 THEN '中薪'ELSE '低薪'END AS salary_level,COUNT(*) AS employee_countFROM employeesGROUP BY department, salary_level;复制
结果:
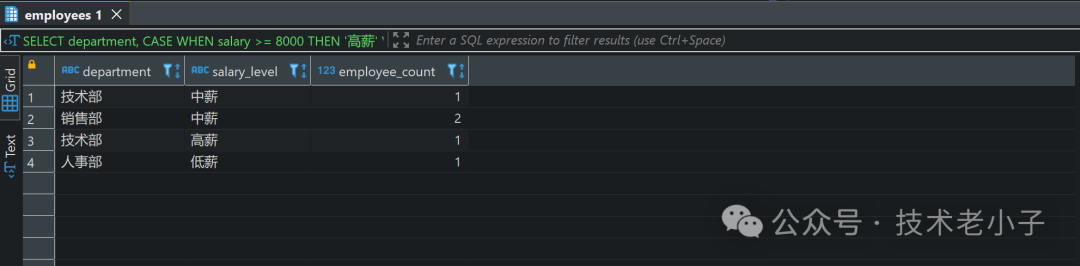
这个查询通过CASE
表达式为每个员工定义了一个薪资级别,然后按部门和薪资级别分组,并统计各组的员工人数。
结论
GROUP BY
子句在MySQL中是一个非常强大的工具,用于对数据进行分组和聚合分析。通过结合使用各种聚合函数,我们可以轻松统计和汇总不同组的数据。这对于数据分析、报表生成等工作非常有用。通过本文的示例,您应该对GROUP BY
的基本用法有了较为充分的理解,并可以在实际项目中应用这些知识。




