




传统的生成式语言模型(LLM)面临着成本高昂以及可拓展性和更新速度上的限制,而检索增强型语言模型(RALM)将大语言模型与矢量数据库结合,能够在降低模型规模的同时提高生成质量。然而,要高效实现这种方法仍面临巨大的技术挑战,尤其是在推理效率和硬件资源利用方面。为此,本次为大家带来发表在PVLDB 2024的文章《Chameleon: a Heterogeneous and Disaggregated Accelerator System for Retrieval-Augmented Language Models》。

一. 背景
生成式语言模型(LLM)近年来在许多自然语言处理任务中展现了卓越的性能。然而,传统的 LLM 依赖大规模参数存储大量知识,这种方式不仅在训练和推理时代价高昂,还面临知识陈旧的问题。为解决这些问题,检索增强型语言模型(Retrieval-Augmented Language Models, RALM)已成为一种有吸引力的替代方案。如图1所示,通过结合大型语言模型和外部向量数据库,RALM 能够动态检索相关知识,在生成时将检索的内容作为附加上下文进行处理。这一方法使得 RALM 能够使用更小的模型参数和更少的预训练成本,同时通过动态知识更新保持模型的最新性。
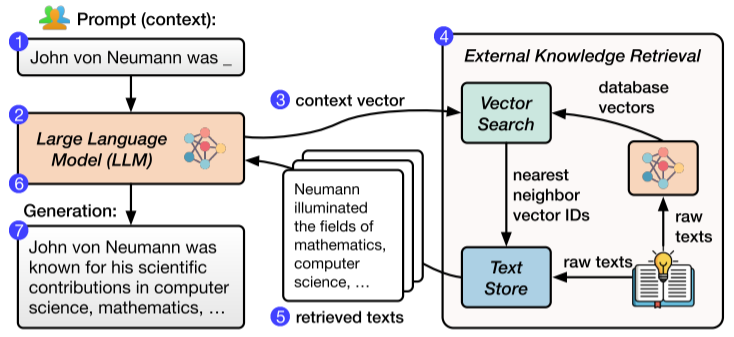
图1 一种检索增强型语言模型
尽管 RALM 在生成质量和效率上有显著优势,其推理过程仍然面临两大挑战:
挑战1:工作负载异构性。RALM 的推理任务包括大型语言模型的推理和外部知识检索,这两者在计算需求和资源分布上截然不同。具体而言,LLM 推理依赖高效的张量计算,而向量检索则需要高吞吐量的大内存访问与相似度计算。单一硬件平台难以同时优化这两类计算,导致现有系统无法高效地支持 RALM 的运行。
挑战2:需求多样性。不同的 RALM 对硬件配置的要求各不相同。例如,一些 RALM 在每次生成新词时需要频繁检索,而另一些可能只在生成初期进行一次检索。这种需求差异对系统灵活性提出了更高的要求。
针对上述挑战,本文提出了一种用于检索增强语言模型的异构解耦加速系统——Chameleon,其贡献总结如下:
(1)提出了用于检索增强型语言模型(RALM)优化的一种异构、解耦的硬件架构,利用GPU和FPGA各自的能力有效处理了语言模型推理与向量检索之间的异质性需求。
(2)设计并实现了 ChamVS(分布式向量检索引擎)和 ChamLM(多 GPU 推理引擎),利用两者协同工作以支持高效的RALM推理。ChamVS通过硬件优化显著加速向量检索,而ChamLM通过分布式推理提升了生成任务的吞吐量。
(3)提供了一个模块化的解耦架构,使得硬件资源能够灵活扩展。该架构能够根据不同RALM的需求调整GPU和FPGA的比例,从而适应多样化配置并避免资源浪费。
(4)通过全面的实验验证了Chameleon的优秀性能,结果表明其在延迟、吞吐量和能效方面显著优于现有方案。特别是在高频检索场景中,Chameleon扩展能力和资源利用效率尤为出色。
二. 方法介绍
2.1 总体框架
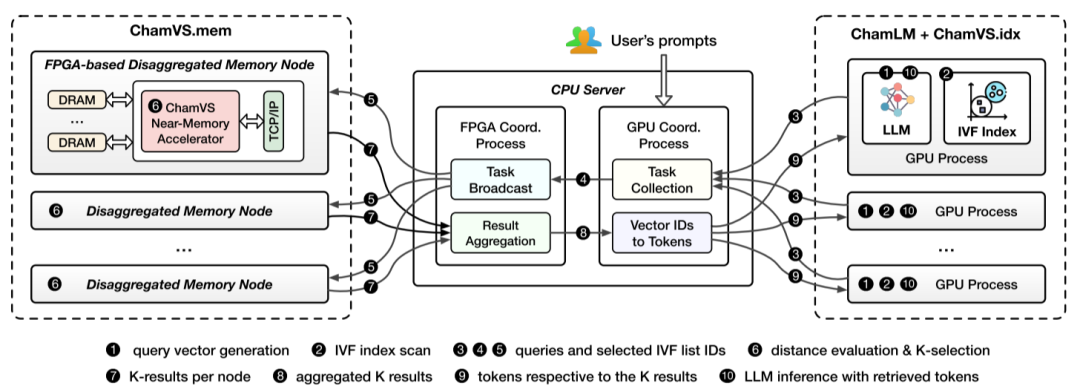
图2 Chameleon系统架构
文章设计并实现了Chameleon,一个高效、灵活和高性能的RALM推理系统:
Chameleon采用异构硬件来有效地加速LLM推理和向量搜索。
Chameleon解耦各加速器,为每种类型的硬件实现独立扩展,从而能够有效地支持各种RALM配置。
Chameleon的模块化设计使其支持灵活的硬件升级,例如在未来集成更强大的LLM推理加速器或基于ASIC的ChamVS加速器。
图2概述了Chameleon的总体架构,该架构由以下三个主要组件组成:ChamVS、ChamLM和一个轻量级的CPU协调器,其中:
ChamVS是一个部署在FPGA上部署在FPGA上的分布式向量检索引擎,其专注于处理检索任务,包括向量相似度计算和近邻搜索。通过硬件优化和流水线设计,ChamVS 能够显著提高检索效率并降低能耗。
ChamLM是一个多GPU推理引擎,负责生成查询向量、整合检索结果并执行语言模型推理。其设计支持分布式运行以适应不同规模的语言模型需求。
CPU协调器负责管理ChamVS和ChamLM之间的通信,确保系统任务的高效分发和数据流的顺畅整合。它采用轻量级通信协议,最大限度地降低网络延迟。
在Chameleon的工作流中,用户的输入首先由ChamLM处理以生成查询向量,随后查询被发送至ChamVS处进行向量检索。检索到的相关内容被返回ChamLM,作为语言模型生成任务的额外上下文。该解耦架构允许ChamVS和ChamLM在独立的硬件资源上运行,从而优化了性能并与扩展的灵活性。通过这种模块化设计,Chameleon 能够适应不同 RALM 配置需求,同时大幅提升推理效率,降低所需的硬件成本和能耗。
2.2 ChamVS:近存加速器
ChamVS是Chameleon系统中的分布式向量检索引擎,其被部署在 FPGA 上,用于高效处理向量相似性计算和近邻搜索任务。为了应对向量检索中高吞吐量和低延迟的要求,ChamVS采用了近存加速(Near-Memory Acceleration, NMA)的设计方法,其核心思想是将计算资源直接集成到存储器附近,从而显著减少数据移动的开销。通过这一设计,ChamVS实现了高效的硬件利用率和卓越的检索性能。
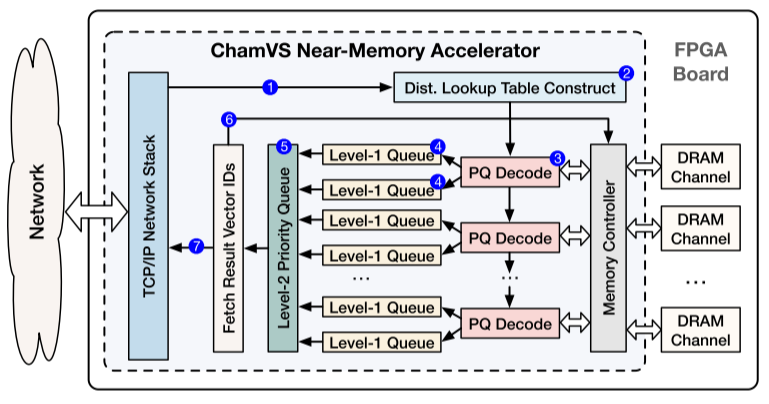
图3 ChamVS近存加速器
具体来说,ChamVS通过将每个分解的内存节点与一个近存储检索加速器配对,实现了高性能的大规模向量搜索,其结构如图3所示,主要包括以下组件:距离查找表构建单元、多个用于计算查询向量与量化数据库向量距离的PQ解码单元、一组用于并行K选择的优先级队列,以及多个内存通道。
2.2.1 PQ解码单元
如图3的标注 (3) 所示,每个ChamVS加速器包含多个PQ解码单元,用于充分利用内存带宽。这些单元从DRAM中读取数据库向量(PQ编码)并利用距离查找表计算它们与查询向量之间的距离。
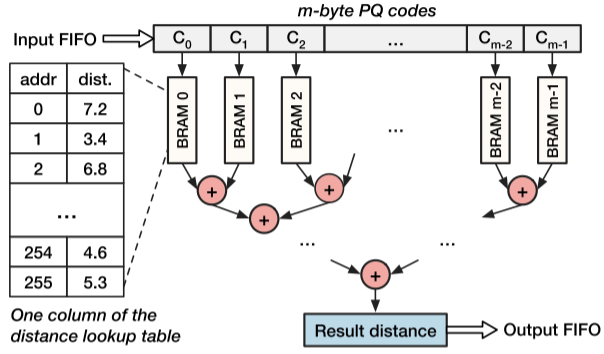
图4 PQ解码单元架构设计
PQ 解码单元的设计结合了操作并行和流水线并行,使其能够实现每时钟周期生成一个距离结果的高吞吐量表现。图4展示了PQ解码单元的架构设计,其解码步骤(包括数据摄取、距离查找、计算和输出)完全流水化,且该单元在距离查找和计算步骤中能够并行化操作从而提高效率。
2.2.2 高效的K选择模块
ChamVS中的K选择模块从PQ解码单元计算的距离中选择K个最近邻的。为了应对每个时钟周期需要处理多个输入元素的高吞吐量要求,作者提出了一种近似分层优先级队列(AHPQ)架构,这是一种适用于硬件的高吞吐量且资源高效的并行K选择方法。
a. 基本组件:Systolic 优先级队列
Systolic 优先级队列能够在硬件加速器上支持高吞吐量的输入摄取,实现每两个时钟周期处理一个输入元素。简单来说,它是一个配备比较交换单元的寄存器阵列,因此其队列的硬件资源消耗与其长度成线性关系。
一种自然的实现方式是在ChamVS中使用分层优先级队列,如图3的标注 (4)(5)所示,在层次结构中,每两个L1队列与一个PQ解码单元配对。对于每个查询,每个L1队列收集一部分最近邻的结果,随后由L2队列选择最终的K个结果。然而,直接实现这样的分层优先级队列会消耗过多的硬件资源,即使在高端 FPGA 上也难以承受。
b. 近似分层优先级队列(AHPQ)
ChamVS提出的AHPQ架构放宽了K选择的精确性要求,使其在绝大多数情况下(如99%的查询)保证结果几乎一致的同时,显著降低了硬件资源消耗。
其核心思想是:所有 K 个结果不可能全部由单个PQ解码单元生成。例如,对于包含16个L1队列的情况,每个队列的平均结果数量仅为K/16=6.25,而统计结果表明,单个队列中包含超过20个结果的概率极低。因此,L1队列的长度可以截断至20,而这不会显著影响结果的准确性。
2.2.3 内存管理与负载均衡
ChamVS的内存管理机制在内存节点和通道之间平衡工作负载。在当前实现中,每个IVF列表中的向量被均匀划分到不同的内存节点,这些子列表进一步分布到内存通道上以确保负载均衡。对于无法进一步划分的小型IVF列表,它们可能驻留在不同的节点或通道上,而这可能导致负载不平衡(尤其是在小批量查询的情况下),这种不平衡可以通过更大的批量查询来缓解。此外,对于访问频率不均的IVF列表,可以根据频率调整其位置以实现更好的负载均衡。
三.实验
3.1 实验设置
表1 实验中各RALM的配置情况
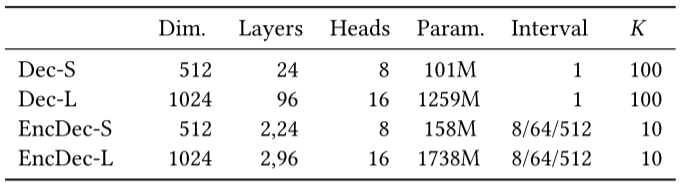
表2 实验中所用的向量数据集
大语言模型(LLMs). 作者评估了类似于现有 RALM 研究中使用的模型,规模从几亿到几十亿参数不等,包括较小(S)和较大(L)的解码器(Dec)和编码-解码器(EncDec)模型。表1总结了四种RALM的评估配置,包括输入维度、层数、注意力heads、模型大小、检索间隔和邻居数量。
向量数据集. 表2列出了实验中使用的四个向量数据集。其中SIFT和Deep是常用的十亿级 ANN 基准数据集。此外,通过将每个 SIFT 向量扩展到 512 和 1024 维,作者还创建了两个合成数据集:SYN-512和SYN-1024。
软件.对于向量搜索,作者使用了由Meta开发的Faiss,其在CPU和GPU上优化了PQ实现。对于LLM推理,作者扩展了Fairseq以支持前文介绍的RALM功能。
硬件. 作者在AMD Alveo U250 FPGA(16nm)上实现了ChamVS近存储加速器,该设备配备了64GB DDR4 内存(4通道,每通道16GB),加速器频率设为140MHz。公平起见,作者将每个ChamVS内存节点与具有相同内存容量(64GB)的CPU向量搜索系统进行比较,该系统基于8核AMD EPYC 7313 处理器(7nm,基础频率为3.0GHz)。此外,作者使用了配备24GB GDDR6X内存的NVIDIA RTX 3090 GPU(8nm)。
3.2 ChamVS上的大规模向量搜索

图5 ChamVS实现了比CPUs和GPUs更低的向量搜索延迟
搜索性能:文章使用四种硬件设置(CPU、CPU-GPU、FPGA-CPU和FPGA-GPU)将ChamVS与基线系统进行比较 ,图5比较了四种方案的延迟分布,从中可以观察到:
ChamVS的近存储加速器显著降低了向量搜索的延迟。在不同的数据集和批大小下,FPGA-CPU方案相较于CPU基线实现了1.36∼6.13倍的加速,而FPGA-GPU方案的加速幅度更高,达到2.25∼23.72倍。这得益于ChamVS的近存储加速器能够实现并行PQ编码,并将解码、距离计算和 K选择流水线化,从而能够快速处理量化向量。
在GPU上扫描IVF索引进一步提高了延迟表现。与FPGA-CPU方案相比,FPGA-GPU方案实现了1.04∼3.87倍的加速。这是因为IVF索引扫描可以充分利用GPU的高并行性和内存带宽。而CPU-GPU混合方案的改进则不大(0.91∼1.42 倍),甚至可能会表现更差,这可能是因为其性能受限于CPU上缓慢的PQ编码扫描过程。
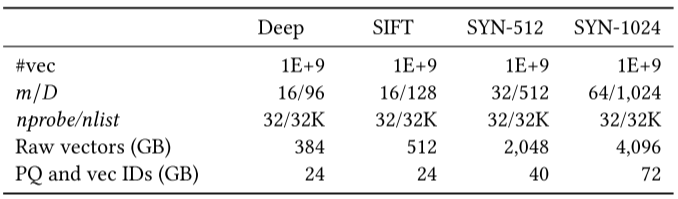
能耗. ChamVS的能效是CPU的5.8∼26.2倍。表 3 总结了不同系统在各种批量大小(1∼16)下的每查询平均能耗。
表3 在ChamVS和CPU上使用各种批量大小(1~16)的每查询的平均能耗(单位:mJ)
其中,ChamVS 的能耗通过以下方式计算:分别测量FPGA上PQ编码扫描和GPU 上索引扫描的功耗,再将其乘以对应的延迟,最后将两部分相加。
召回率. ChamVS使用近似分层优先级队列(AHPQ),结果与软件实现几乎完全一致。表 4 显示了在搜索100个最近邻结果时,不同AHPQ长度(8∼32)下的召回率。
表4 ChamVS使用近似队列的召回率
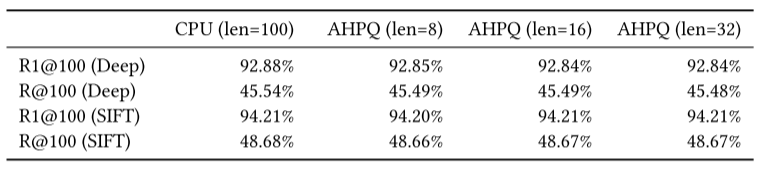
其中,R1@100表示返回结果中包含最近邻的查询百分比,R@100表示返回的100 个结果与真实最近邻之间的重叠百分比。与软件相比,AHPQ的召回率仅下降最多 0.06%。
3.3 Chameleon上的端到端RALM推理
作者在Chameleon上评估了不同模型和检索间隔下的推理性能,并使用SYN-512和SYN-1024数据集分别测试了较小和较大的模型。
推理延迟. Chameleon 在涉及向量搜索的推理步骤中,相较于CPU-GPU基线系统显著减少了延迟。图6显示了Chameleon和基线系统在生成前 128 个令牌时的推理延迟。图中灰点表示推理延迟,其余部分为检索延迟。
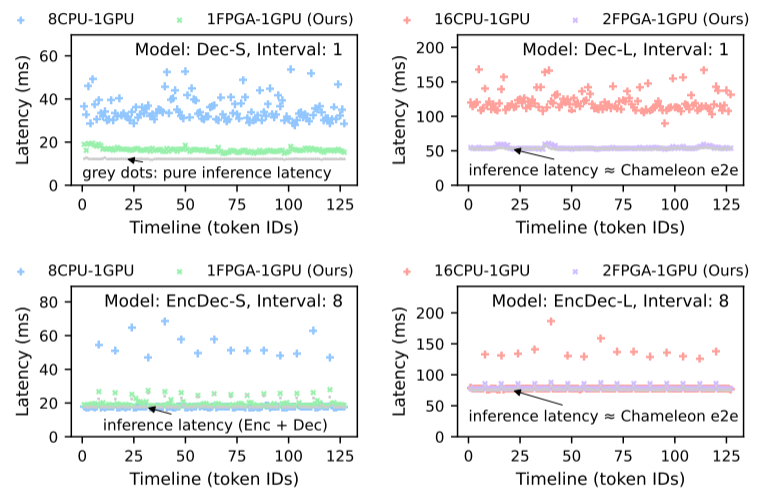
图6 不同LLM配置和检索间隔下RALM的推理延迟
由上图可见ChamVS显著降低了需要检索的令牌生成步骤的延迟。在GPU执行推理的情况下,检索延迟几乎可以忽略不计。具体而言,Chameleon 在基于检索的推理步骤(检索 + 推理)上的加速比为:Dec-S:1.94∼4.11 倍;EncDec-S:1.71∼3.02 倍;Dec-L:1.76∼3.41 倍;EncDec-L:1.29∼2.13 倍。
推理吞吐量. 相较于CPU-GPU基线系统,Chameleon的吞吐量最高提高了3.18倍。图7显示了在不同检索间隔下的吞吐量对比。从中可见检索间隔越低,Chameleon带来的吞吐量优势越明显。对于每个生成令牌均需检索的情况(间隔=1),Dec-S和 Dec-L的吞吐量分别提升了3.18倍和2.34倍。而相比单序列推理,Chameleon在批量推理中的加速效果则更为明显。
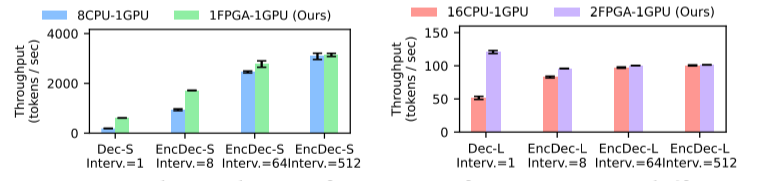
图7 不同的LLM配置和检索间隔下RALM推理的吞吐量
四.总结
论文介绍了一种为 RALM 推理设计的高效异构解耦加速器系统——Chameleon,通过整合FPGA和GPU资源,加速向量搜索和LLM推理过程。相关实验证明了该系统能够显著降低延迟,提高吞吐量,并同时优化能耗表现。
 |

图文|徐小龙
校稿|何 翔
编辑|朱明辉
审核|李瑞远
审核|杨广超
