




随着无线和移动设备的广泛部署,时空数据的生成量急剧增加,这些数据被广泛应用于交通预测、人类移动性挖掘和空气质量预测等领域。然而,现有的深度学习模型在处理流式时空数据时,往往会遇到“灾难性遗忘”问题,导致预测性能下降。本次为大家带来ICDE 2024的文章《A Unified Replay-based Continuous Learning Framework for Spatio-Temporal Prediction on Streaming Data》。

一. 背景
随着社会的快速数字化和传感技术的广泛部署,时空数据的产生呈现指数级增长。例如,道路传感器实时捕获的交通流量数据,可以精确反映不同时间、地点的交通状况。这些流式时空数据蕴含的动态信息,广泛被应用于交通流量预测、按需服务预测等领域。然而,尽管需求旺盛,现有技术在处理流式时空数据的连续学习问题上仍存在明显不足。
目前主流的时空预测方法大多基于静态模型,这些模型通常在固定的数据集上完成训练后直接用于预测,其通常假设数据分布在时间维度上保持不变。然而,流式时空数据常常受“概念漂移”的影响,即数据分布会随着时间的推移发生变化。这种变化使得静态模型难以适应不断到来的新数据,导致预测性能显著下降。特别是当模型简单地用新数据进行更新时,往往会遗忘之前学到的知识,从而在早期学习的任务上表现退化,这种现象被称为“灾难性遗忘”。虽然已有研究在计算机视觉和自然语言处理领域尝试解决这一问题,但这些方法由于未考虑时空数据的特殊性,难以直接应用于流式时空数据的预测。
此外,不同类型的时空数据和预测任务往往存在显著差异。每一种预测应用都可能需要特定的数据处理方式、网络架构和优化目标,这使得为每个任务设计专用模型既耗时又缺乏通用性。更为复杂的是,时空预测任务不仅要求模型能够捕获数据的时空相关性,还需具备对整体特征的保留能力。例如,工作日非高峰时段的交通模式可能对后续工作日的预测具有参考价值,但现有模型往往专注于当前任务的学习,忽视了对过去学到的语义特征的保留,从而影响了对未来任务的预测。
为了应对这些挑战,论文提出了一种统一的基于重放的连续学习框架(URCL),其贡献如下:
(1)论文设计了时空混合机制(STMixup),通过融合当前数据与历史数据,减轻模型对过去知识的遗忘。
(2)基于统一的时空自动编码器(包括时空编码器和解码器),URCL能够有效捕获复杂的时空依赖关系。
(3)论文提出了一种整体特征保留模块(STSimSiam),通过互信息最大化方法帮助模型保留历史特征,并结合五种数据增强方法进一步提升模型的学习能力。
二. 方法介绍
2.1 总体框架
URCL框架由三个主要模块组成:数据集成模块、时空连续表示学习模块(STCRL)和时空预测模块。数据集成模块通过时空混合(STMixup)机制将当前数据与回放缓冲区中的历史数据进行融合,以保留历史知识。STCRL模块使用时空简单孪生网络(STSimSiam)进行自监督学习,通过最大化互信息来保留整体特征。时空预测模块则使用时空编码器(STEncoder)和时空解码器(STDecoder)进行预测。具体如图1所示:
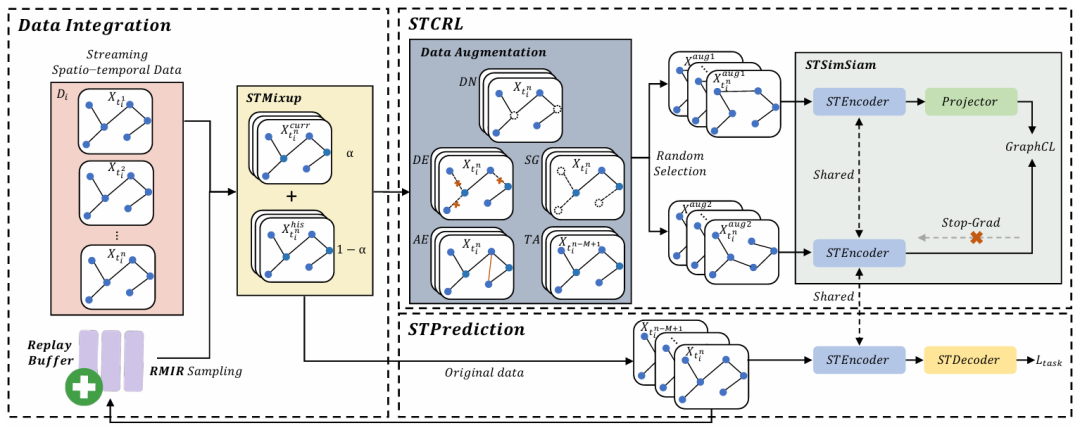
图1 URCL框架
2.2 数据集成模块
2.2.1 回放缓冲区与采样策略
回放缓冲区:URCL引入了一个回放缓冲区(Replay Buffer),用于存储一部分历史数据。这些历史数据是从之前的学习任务中抽取的,目的是在后续训练中与当前数据结合,以保留历史知识并缓解灾难性遗忘。
基于排名的最大干扰检索(RMIR)采样策略:为了从回放缓冲区中选择最具代表性的样本,URCL采用了RMIR采样策略。该策略首先检索那些在参数更新后损失增加最多的样本(即受干扰最大的样本),然后根据这些样本与当前数据的相似性(Pearson相关系数)进行选择。这种策略不仅能够有效缓解灾难性遗忘,还能增强模型对时间依赖性的捕捉能力。
2.2.2 时空混合(STMixup)机制
在选择了回放缓冲区中的样本后,URCL通过时空混合(STMixup)机制将当前数据与历史数据进行融合。STMixup通过线性插值生成虚拟训练样本,从而扩大训练分布的支持范围,克服概念漂移问题。具体公式如下:
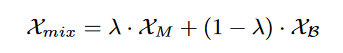
其中,λ是从Beta分布中采样的参数,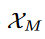 是当前数据,
是当前数据,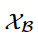 是缓冲区采样数据。
是缓冲区采样数据。
2.3 时空连续表示学习模块(STCRL)
2.3.1 时空数据增强方法
为提高时空特征的学习质量和模型的鲁棒性,STCRL模块引入了五种增强方法。这些方法充分考虑了时空数据的独特性质(如空间关联和时间依赖),生成语义相似的样本对供模型学习。
1. DropNodes(DN):随机丢弃部分节点,增强模型在缺失数据场景下的鲁棒性。
2. DeleteEdges(DE):随机删除部分边,以探索重要边的保留对模型性能的影响。
3. SubGraph(SG):通过随机游走采样子图,保留局部空间结构的语义。
4. AddEdge(AE):为相似的远距离节点对添加边,以捕获全局空间关联。
5. TimeShifting(TS):包括时间切片(slicing)、时间扭曲(warping)和时间翻转(flipping)三种方法,用于改变时间序列的分步。
2.3.3 STSimSiam网络
STSimSiam是STCRL模块的核心网络,通过自监督方式学习时空特征。它包括以下关键组成部分:
1. 双STEncoder:两个共享参数的编码器,用于生成增强样本对的特征表示。
2. 投影 MLP:一个多层感知机(MLP)头,用于将一个编码器的输出映射到另一个编码器的潜在空间。
整个网络的目标是最大化增强样本对的特征表示之间的相似性,以实现全局特征的保持。相似性通过余弦相似度(Cosine Similarity)计算:
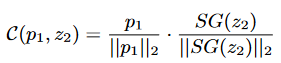
其中,p1和p2分别是第一个样本的投影和第二个样本的编码;SG(⋅)是梯度停止操作,避免网络陷入平凡解。
为了进一步提升表示学习的效果,STSimSiam引入了基于GraphCL的对比损失函数:
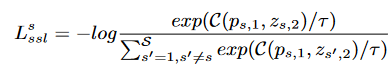
其中,其中ps,1和zs,2表示第s个增强观测对的输出向量,C(·)为余弦相似度,τ为温度参数。
2.4 时空预测模块
2.4.1 时空编码器
时空编码器(STEncoder)是时空预测模块的核心,旨在从输入数据中学习复杂的时空特征表示。它主要结合了多层结构,包括MLP层、门控时间卷积网络(Gated TCN)和图卷积网络(GCN),如图2所示。
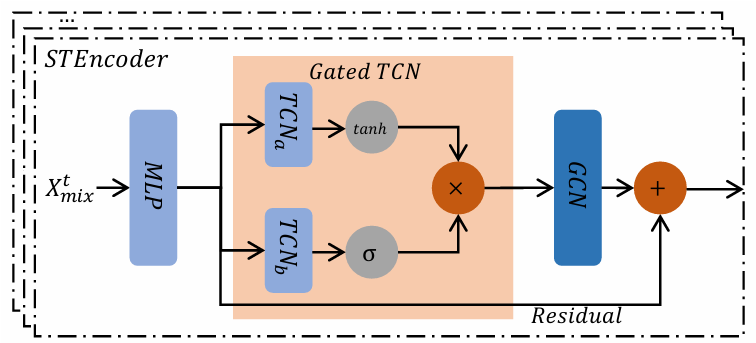
图2 STEncoder示意图
首先,输入数据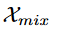 通过MLP层映射到高维空间,为后续的时空特征提取奠定基础。随后,通过门控时间卷积网络捕获数据的时间依赖关系。门控时间卷积采用膨胀因果卷积(Dilated Causal Convolution)来建模长期时间相关性,其公式如下:
通过MLP层映射到高维空间,为后续的时空特征提取奠定基础。随后,通过门控时间卷积网络捕获数据的时间依赖关系。门控时间卷积采用膨胀因果卷积(Dilated Causal Convolution)来建模长期时间相关性,其公式如下:
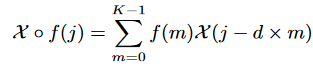
其中,d为膨胀因子,K为卷积核的长度。为了增强对信息流的控制,还在时间卷积中加入门控机制,具体形式为:
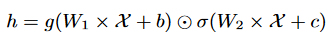
其中,g(·)和σ(·)分别表示激活函数,⊙表示逐元素乘法操作。
在空间依赖建模方面,STEncoder使用图卷积网络(GCN)提取节点之间的空间关联。GCN的基本操作可以表示为:
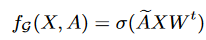
其中,A是邻接矩阵,X是节点特征矩阵,W是可学习的权重矩阵,σ(·)是激活函数。此外,为了更好地捕获全局空间依赖,STEncoder引入了自适应邻接矩阵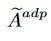 ,其计算公式为:
,其计算公式为:
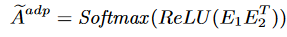
其中,E1和E2是可学习的节点嵌入矩阵。
通过多层次的时间与空间依赖建模,STEncoder最终输出高维时空特征 ,为后续的预测提供丰富的信息支持。
,为后续的预测提供丰富的信息支持。
2.4.2 时空解码器
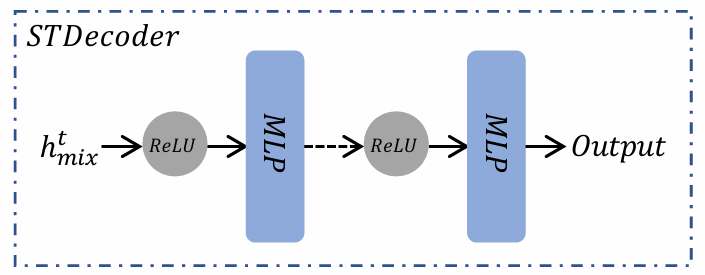
图3 STDecoder示意图
时空解码器(STDecoder)负责将STEncoder提取的高维时空特征转换为具体的预测结果。解码器由多个全连接层(MLPs)组成,通过激活函数(如ReLU)完成特征到输出空间的映射,如图3所示。具体公式为:
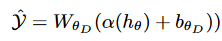
其中,是可学习的权重矩阵,α(·)是激活函数,是偏置项。
通过解码器的操作,复杂的时空特征被有效地解码为预测值,例如未来的交通速度或流量。这种结构设计保证了模块的灵活性和高效性,同时适配多种类型的预测任务。
三.实验
3.1 实验设置
数据集:实验使用了四个常用的时空数据集,涵盖交通流量和交通速度预测任务:
METR-LA:包含洛杉矶交通速度数据,由207个传感器采集,时间跨度为4个月。
PEMS-BAY:包含加州湾区的交通速度数据,由325个传感器采集,时间跨度为5个月。
PEMS04:包含加州圣贝纳迪诺的交通流量数据,由307个传感器采集,时间跨度为2个月。
PEMS08:包含加州交通流量数据,由170个传感器采集,时间跨度为2个月。
每个数据集使用30%数据作为基础训练集(Base Set),其余数据被划分为四个等量的增量训练集(Incremental Sets)。
评价指标:MAE(Mean Absolute Error):平均绝对误差;RMSE(Root Mean Square Error):均方根误差。
比较方法:ARIMA:经典统计模型,用于时间序列预测。DCRNN:基于扩散图卷积和循环神经网络的时空预测模型。STGCN:基于图卷积网络和一维卷积的时空预测模型。MTGNN:使用多变量时间序列建模的图神经网络。AGCRN:自适应图卷积与循环神经网络相结合的时空预测方法。STGODE:采用图微分方程建模时空动态的预测模型。所有基线方法均采用与URCL相同的训练和测试设置,以保证比较的公平性。
模型配置:URCL的STEncoder包含五层,每层的隐藏单元数为32、32、32、32和256;STDecoder包含两层,隐藏单元数分别为512和12。缓冲区大小设置为256,数据在预处理阶段被归一化到[0,1]区间。
3.2 实验结果
3.2.1 在流数据上的训练性能
表1显示了URCL在PEMS-BAY和PEMS08数据集上的MAE和RMSE结果,并与两种基线训练策略(OneFitAll和FinetuneST)进行对比。结果表明:
URCL在所有增量训练集中均取得最佳性能,表现出较强的稳定性。与OneFitAll和FinetuneST相比,URCL分别在MAE和RMSE上获得了14.5%-67.3%和15.5%-72.4%的提升。尽管OneFitAll在基础训练集上表现良好,但其在增量训练集上的性能显著下降,表明静态模型无法有效应对概念漂移。FinetuneST由于灾难性遗忘问题,在增量数据上的表现同样有限,而URCL通过缓冲区和数据增强策略显著缓解了这一问题。
表1 两个流数据集上的训练结果

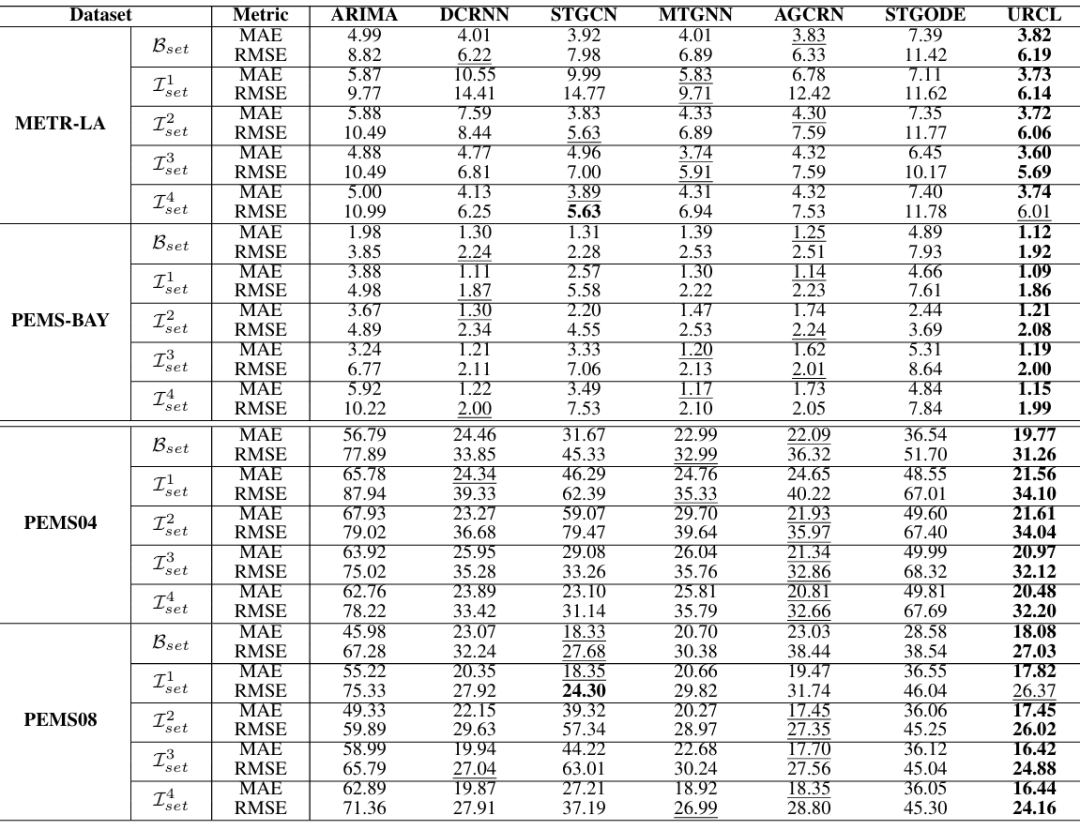
3.2.2 整体预测准确性
表2展示了URCL和基线方法在四个数据集上的MAE和RMSE结果。实验结果表明:URCL在绝大多数情况下均优于所有基线方法。在MAE和RMSE上,URCL分别比最优基线方法提升了最高36.0%和34.1%。在交通速度预测任务(METR-LA和PEMS-BAY)中,URCL表现尤为出色,其对长期时空依赖的建模能力是主要原因。在交通流量预测任务(PEMS04和PEMS08)中,尽管数据量更大,URCL仍然能够通过有效的历史知识整合实现较高的预测准确性。
表2 四个数据集上的总体准确性
3.2.3 消融实验
为了评估URCL各模块的贡献,论文进行了消融实验,分别移除STMixup、RMIR采样、数据增强(STAugmentation)和GraphCL损失模块,并观察性能变化。实验结果如图4所示,其表明:移除任何一个模块都会显著降低预测精度,各模块在URCL框架中都发挥了重要作用。STMixup和RMIR的贡献尤为显著,它们在缓解灾难性遗忘和增强历史知识利用方面起到了关键作用。

图4 URCL及其变体的RMSE和MAE
四.总结
论文提出了一个统一的重放式持续学习框架URCL(Unified Replay-based Continuous Learning),旨在解决流数据场景下时空预测的挑战。通过引入回放缓冲区、时空混合机制(STMixup)、自监督学习模块(STCRL),以及时空编码器与解码器的模块化架构,URCL有效缓解了灾难性遗忘问题,同时捕获复杂的时空依赖关系。在四个真实数据集上的实验表明,URCL在MAE和RMSE指标上显著优于现有方法,验证了其在概念漂移和动态环境中的适应性和稳定性。该框架具有通用性、可扩展性和高效性,能够应用于多种时空预测任务,如交通速度和流量预测,为持续学习和流数据处理领域提供了重要支持,同时为未来复杂场景的持续学习研究指明了方向。
 |
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有3~5名研究生名额,欢迎计算机、GIS等相关专业的学生报考!

图文|孙杨洋
校稿|朱明辉
编辑|朱明辉
审核|李瑞远
审核|杨广超
