




252:给出唯品会的垂直和水平拆分图谱,模拟用户注册和生成销售订单业务,给出 tps 提高的原因,一共有 40 台服务器,tps 落地到某一台具体的服务器。
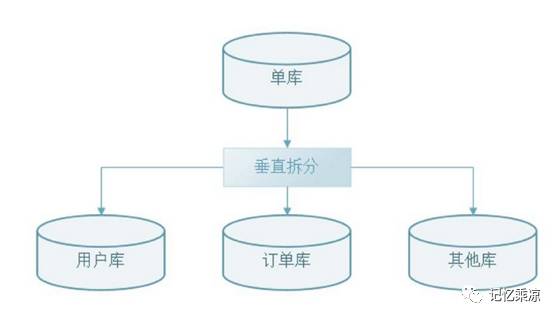
1、垂直拆分
垂直拆库是根据数据库里面的数据表的相关性进行拆分,比如:一个数据库里面既存在用户数据,又存在订单数据,那么垂直拆分可以把用户数据放到用户库、把订单数据放到订单库。如下图:
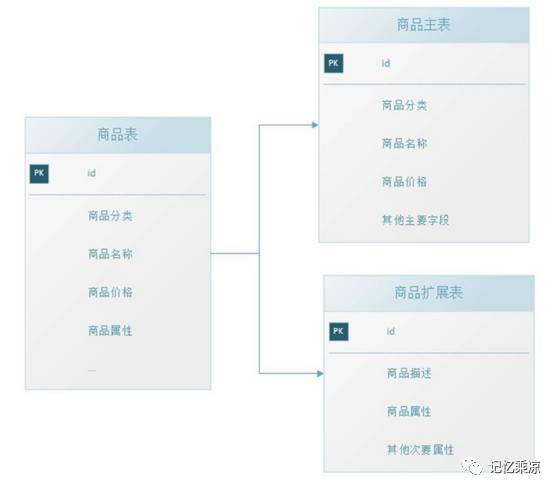
垂直拆表是对数据表进行垂直拆分的一种方式,常见的是把一个多字段的大表按常用字段和非常用字段进行拆分,每个表里面的数据记录数一般情况下是相同的,只是字段不一样,使用主键关联,如下图:
2、水平拆分
水平拆分是把单表按某个规则把数据分散到多个表的拆分方式,比如:把单表1亿数据按某个规则拆分,分别存储到10个相同结果的表,每个表的数据是1千万,拆分出来的表,可以分别放至到不同数据库中,即同时进行水平拆库操作,如下图: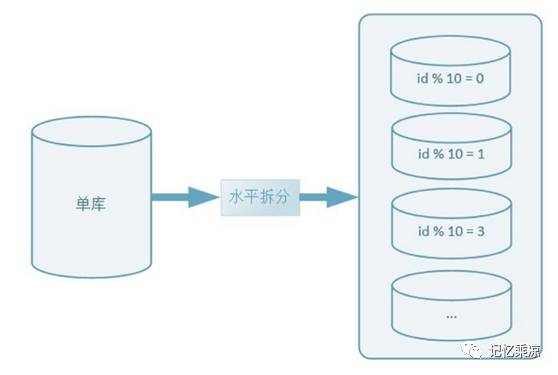
水平拆分可以降低单表数据量,让每个单表的数据量保持在一定范围内,从而提升单表读写性能。但水平拆分后,同一业务数据分布在不同的表或库中,可能需要把单表事务改成跨表事务,需要转变数据统计方式等。
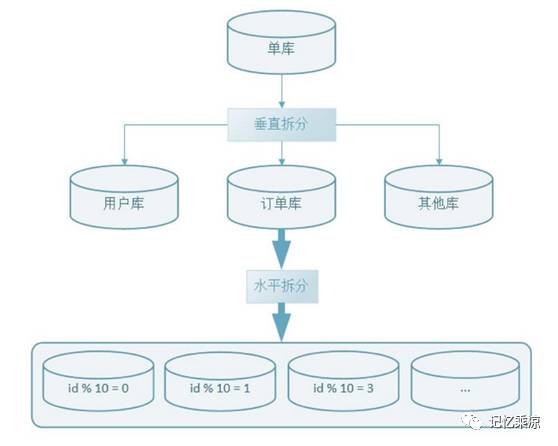
3、垂直水平拆分
垂直水平拆分,是综合了垂直和水平拆分方式的一种混合方式,垂直拆分把不同类型的数据存储到不同库中,再结合水平拆分,使单表数据量保持在合理范围内,提升总TPS,提升性能,如下图:
垂直拆分策略
原订单库把所有订单相关的数据(订单销售、订单售后、订单任务处理等数据)都放在同一数据库中,不符合电商系统分层设计,对于订单销售数据,性能第一,需要能够在大促高峰承受每分钟几万到几十万订单的压力;而售后数据,是在订单生成以后,用于订单物流、订单客服等,性能压力不明显,只要保证数据的及时性即可;所以根据这种情况,把原订单库进行垂直拆分,拆分成订单售后数据、订单销售数据、其他数据等,如下图:

水平拆分策略
垂直拆分从业务上把订单下单数据与下单后处理数据分开,但对于订单销售数据,由于数据量仍然巨大,最大的订单销售相关表达到几十亿的数据量,如果遇到大型促销(如:店庆128、419、618、双十一等等),数据库TPS达到上限,单销售库单订单表仍然无法满足需求,还需要进一步进行拆分,在这里使用水平拆分策略。
订单分表是首先考虑的,分表的目标是保证每个数据表的数量保持在1000~5000万左右,在这个量级下,数据表的大小与性能是最理想的。
如果几十个分表都放到一个订单库里面,运行于单组服务器上,则受限于单组服务器的处理能力,数据库的TPS有限,所以需要考虑分库,把分表放到分库里面,减轻单库的压力,增加总的订单TPS。
1、用户编号HASH切分
使用用户编号哈希取模,根据数据量评估,把单库拆分成n个库,n个库分别存放到m组服务器中,如下图:
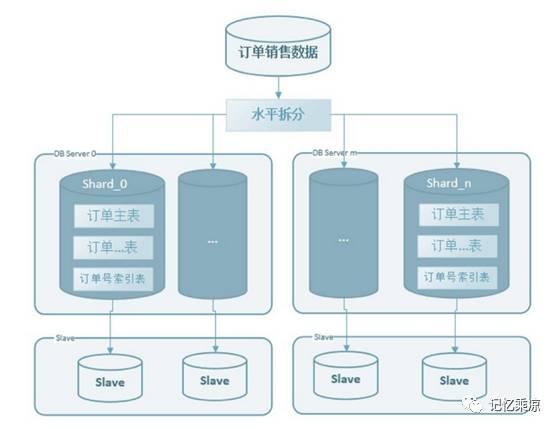
每组服务器容纳4个库,如果将来单服务器达到性能、容量等瓶颈,可以直接把数据库水平扩展为2倍服务器集群,还可以继续扩展为4倍服务器集群。水平扩展可以支撑公司在未来3~5年的快速订单增长。
使用用户编号进行 sharding,可以使得创建订单的处理更简单,不需要进行跨库的事务处理,提高下单的性能与成功率。
2、订单号索引表
根据用户编号进行哈希分库分表,可以满足创建订单和通过用户编号维度进行查询操作的需求,但是根据统计,按订单号进行查询的占比达到80%以上,所以需要解决通过订单号进行订单的CURD等操作,所以需要建立订单号索引表。
订单号索引表是用于用户编号与订单号的对应关系表,根据订单号进行哈希取模,放到分库里面。根据订单号进行查询时,先查出订单号对应的用户编号,再根据用户编号取模查询去对应的库查询订单数据。
订单号与用户编号的关系在创建订单后是不会更改的,为了进一步提高性能,引入缓存,把订单号与用户编号的关系存放到缓存里面,减少查表操作,提升性能,索引不命中时再去查表,并把查询结果更新到缓存中。
3、分布式数据库集群
订单水平分库分表以后,通过用户编号,订单号的查询可以通过上面的方法快速定位到订单数据,但对于其他条件的查询、统计操作,无法简单做到,所以引入分布式数据库中间件。
下图是基本构架:
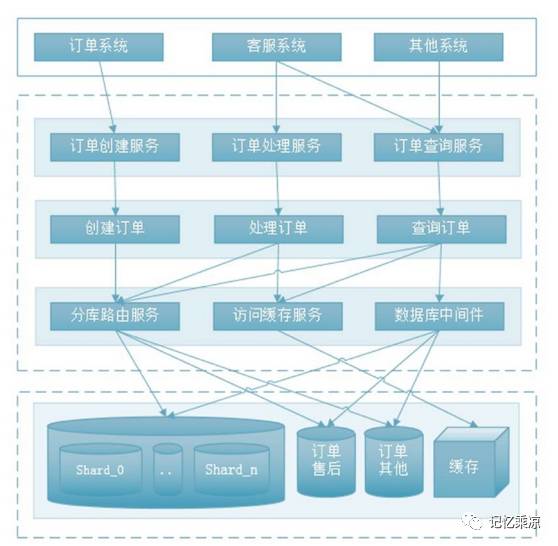
253:对于水平分区的表,不使用水平分区列进行 where 查询的情况下,如何进行操作订单表按照订单编号进行了水平分区,如果使用订单编号进行查找,直接定位某一台服务器上某一张表,如何根据用户编号进行查询呢?
在每一台服务器上建立一个用户编号和订单编号的对应表,同时对于用户编号也进行取模分别存放。
254:分析垂直拆分、水平拆分如何来解决空间压力、写入压力、TPS 问题,解决扩展性问题。
(1) 水平拆分
如果一个表的数据量过多,并且经常被查询,就建议对其进行水平拆分。将一个表中的数据进行分块保存在不同的数据库或表中,这些数据库和表的结构完全相同,拆分的方法有很多,这里列举几点。
1.顺序拆分:在逻辑上可以进行顺序的拆分,例如我们可以按照时间的年份月份来进行拆分,当然也可以按主键标准拆分。这样分的优点就是可以部分迁移,但缺点就是导致数据分布不均,每个时间段的数据量可能并不相同。
2.hash取模分: 利用hash的方式进行不同块的运算,每个块代表着一个数字,这样一来就可以均匀的将数据分配到不同的库中。这样的优点就是数据分布均匀,但缺点是数据迁移的时候会很麻烦,不能按照机器的性能分摊数据。
3.建立分配库:就是建立一个库,这个库里保存着数据到每个库的映射关系,每次访问数据库的时候先查询该数据库,得到具体的库的信息,再进行我们需要的查询操作。该方式的优点是灵活性强,关系明确,缺点就是增加了查询操作,会造成性能损失。
(2)垂直拆分
如果一个表的字段很长,占用的表空间大,这样进行查询操作时会造成大量I/O并使效率下降,就建议对该表进行垂直拆分。将大的字段或者不常用的字段拆分到另一个表中去,该表与原表有着一一对应的关系。
拆分主要是根据业务的应用类型来看是否适合这种方式,在某些业务耦合度较高的表中就不建议使用这种拆分方式。
拆分的方法相对比较简单,将拆分出来的字段进行数据迁移独立成表,根据表名的不同进行访问就可。
255:如何查看一个执行计划所走的索引是否低效。
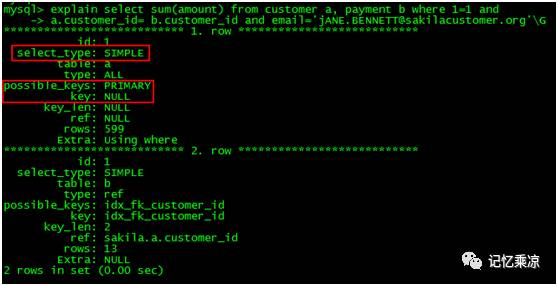 select_type:
select_type:
表示SELECT的类型,常见取值有
SIMPLE: 简单表,即不使用表连接或者子查询
PPRIMARY:主查询,即外层的查询
UNION: union中的第二个或者后面的查询语句
SUBQUERY:子查询中的第一个SELECT
type:
访问表的类型
ALL: 全表扫描,MySQL遍历全表找到匹配行
index: 索引全扫描,遍历整个索引来查询匹配的行
range: 索引范围扫描,常见于 <,<=,>,>=,between 等操作符
ref: 使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录
eq_ref: 类似于ref,区别在于使用的索引时唯一索引
const/system:单表中最多有一个的匹配行,例如:根据主键 primary key 或 唯一索引 unique index 进行的查询
null: 不访问表直接取数据(例:select 1 from dual where 1;)
然后看rows的值和Extra的来判断。
256:如何通过执行计划判断表的连接顺序是否合适。
可以看两个表分别过滤出的行数和走索引的类型进行判断,内连表应该选择查询结果行数少的表。
257:or 为什么不适合复合索引。
SELECT * FROM TB WHERE A=1 AND B>2 AND C<3 AND DIN (4,5,6)
并且在TB表上有这样一个索引:CREATE INDEX INX_TB_ABCD ON TB(A,B,C,D)
那么这个查询可以用到这个索引
如果同样是这个索引,查询换成
SELECT * FROM TB_ WHERE A=1 OR B>2 OR C<3 OR D IN(4,5,6)
那么这个查询就用不到上面那个索引,因为结果集是几个条件的并集,最多只能在查找A=1的数据时用索引,其它几个条件都需要表扫描,那优化器就会选择直接走一遍表扫描,所以索引就失效了。
那么像第二个查询这样的应该怎么建索引呢,答案就是四个列上各建一个索引,或者只在选择性最高的列上建索引,比如A=1的数据量很少,就在A上建,如果D是4,5,6的数据很少,就在D上建,这样优化器就会选择先走索引查找,再对找出的结果集进行筛选,扫描数就会大幅减少。
258:如何使用索引来处理 or 条件。
将or条件中的每个列都单独建立索引。
259:如何使用索引来处理 union、union all 条件。
在UNION和UNION ALL上面和下面的SQL分别建立符合条件的索引,SQL会进行完相应的查询之后再进行UNION和UNION ALL的操作。
260:表的逆规范化来降低表链接的频率。
将经常访问的列放到一个表中,即使出现数据冗余
解释一下三范式:
1NF:表中有字段,而且字段不可再分,表现了其原子性。
2NF:表中有主键,非主键字段和主键有对应关系,且一个表可以说明一个事物,表现了其唯一性。
3NF:表中的非主键字段不相互依赖,只与主键有直接关系,不存在传递关系。
三范式是一种规则,一般我们是基于三范式来进行数据库和表的设计,在这种模式下,我们的数据库可以得到有效的存储,也避免了数据的冗余。但是,有些时候做查询操作需要关联很多表,就会导致效率下降,这时候我们就可以根据实际的情况,有意的反范式,做适度的冗余操作,这种情况下,查询效率的提高是大于冗余的影响的。
261:如何来解决逆规范化中的数据冗余问题呢。
1、事务化
要修改用户的信息,就需要在一个事务中同时修改用户表和账单表
2、写一个存储过程,存储过程作为修改用户表的一个接口、配合权限控制
3、定期统一更新
