





在大数据时代,大家无论是生活还是工作中都会遇到各样的相关关系。例如,冬奥会的热度和媒体报道是否相关、公司的业绩和产品质量是否相关、熬夜人数和短视频软件的兴起是否相关等。了解相关关系、相关性分析等,有助于大家更好在生活、工作、甚至投资中获得更多启发和洞察。下面我们将会带您了解相关性分析的概念、理论以及用法。
#01
什么是相关性分析

相关性分析指的是判断一个事情的发生是否和其他事情相关。相关关系指的是通过识别有用的关联物来帮助人们分析某个现象,而不是揭示其内部机理。例如,沃尔玛发现当季节性飓风来临前,手电筒和蛋挞的销售额都上升了,这是为什么?这个问题的答案对于沃尔玛的经理来说可能并不重要,他要做的就是在合适的时机,把这两种商品陈列在一起,以便顾客将两种商品都购买走。

进行相关性分析的前提是我们可以将信息进行量化,就可以把这些变量放到散点图中。相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母 r 表示。由于研究对象的不同,相关系数有多种定义方式,较为常用的是皮尔逊相关系数。
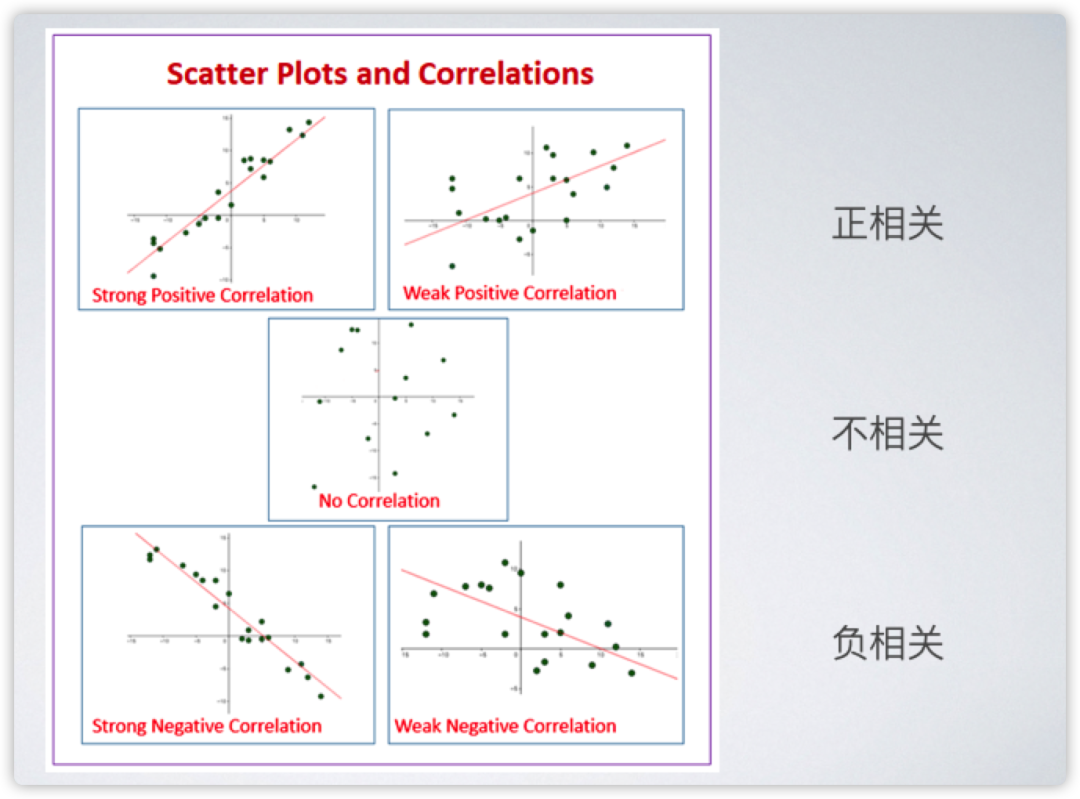
相关表和相关图可反映两个变量 X 和 Y 之间的相互关系及其相关方向。如果 X 越大 Y 越大,那么两个变量之间的趋势就是正相关。如果两个变量间分散没什么明显方向联系,那么是不相关。如果 X 越大 Y 越小,那么两个变量之间的趋势就是负相关。
Kyligence Enterprise 中的 CORR 函数返回数值即为相关系数,可以用来衡量两个变量之间的线性关系,结果为 Double 型数据(双精度浮点型),范围为 -1 至 +1(包括 -1 和 +1),其中 1 表示精确的正向线性关系,比如一个变量中的正向更改即表示另一个变量中对应量级的正向更改,0 表示变量之间没有线性关系,而 −1 表示精确的反向关系。
有了相关系数,我们就可以判断一些趋势,甚至进行预测。比如在分析了某小区楼盘的房屋出售价格和层数的相关性关系之后,如果有一套 18 层房屋要出售,我们就可以按照层数的关系大致预估出这套房屋挂牌能卖到多少钱。我们甚至可以用相关系数高的变量做出房价基于几个变量的线性公式,用来得出专属的房价算法,类似的相关性分析也可以运用于很多领域,比如零售、投资、实验等。
#02
相关关系不等于因果关系
既然我们知道了相关性分析,并且可以推断出一些结论,那么可不可以说我们找到了因果关系呢?比如说 A 和 B 相关,可以说 A 导致了 B 么?
统计学家一个非常重要的观点是:相关不等于因果。(Correlation doesn't imply Causation !)这里有大量的例子来说明相关性和因果性的不等关系。
例子1:“人们普遍出门只穿着T恤背心”和“空调的使用量大幅增加”这两个现象在时间上是相关的,但它们并不是其中一个导致的另一个,它们都来源于同一个原因,即“天气变热”。
例子2:一场火灾的死伤人数和救火动员的消防员数量是成正比的,但是同时影响他们的第三因素是火灾的严重程度,所以我们不能通过减少消防员数量来减少死伤人数。
例子3:根据权威统计,在中国,身高越高的人,平均头发长度越短,是因为长得高导致了头发长不长呢?还是头发长了会导致长不高?其实都不是,因为性别同时控制了这两个变量,男性的身高更高,他们的头发也更短。
要说明两个变量“相关”,通常是没加强相关或者弱相关的定义,人们总以为是强相关,即一个条件是另一个条件的充分且必要条件。但是现实生活中,很少有完美的强正相关,更多的是充分非必要的相关性。我们看如下例子。
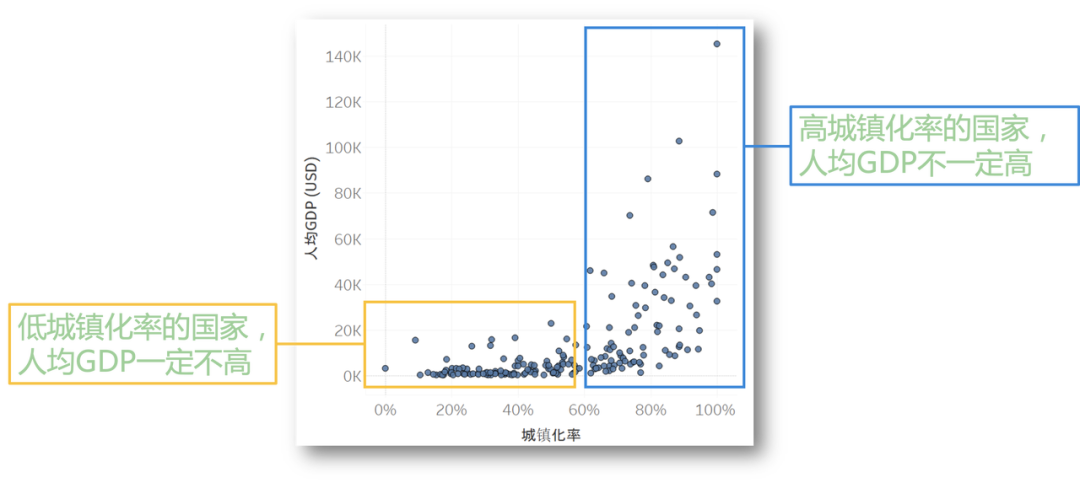
如上图所示,人均 GDP 和城镇化率呈正相关的趋势,在左侧的低城镇化率下,人均 GDP 一定不高;但在右侧的高城镇化率下,人均 GDP 不一定高。所以提高城镇化率,是提高人均 GDP 的必要条件,而非充分条件。
接下来,我们来了解一下实际客户使用 Kyligence 来实现相关性分析的案例。
#03
用户故事:基于大数据 OLAP 技术的业财一体化分析应用
在应对市场竞争中,某头部保险企业基于 Kyligence 搭建了大数据的业财一体化分析和管理平台,对业务和财务数据中的40个维度和300个指标进行建模,实现了多维统计报表秒级响应,极大地提升了业务分析效率和分析深度,更好支持业务管理层进行市场资源配置和成本预测,并逐步推广成为该公司精细化的成本管理平台。
公司整合来自车险、非车险、渠道、费用、精算、再保等业务财务数据,搭建了一个高性能、高并发、可扩展的业财一体化大数据平台。通过引入精算预期赔付率与细分销售跟单费用十个段,引入成本区间分析、费赔相关系数等指标,让业务、财务均能及时清楚地了解相关层级和维度的业务成本结构,明细赔付与费用投放的匹配关系,帮助各层级机构强化对资源配置的管理。
业财一体化分析平台通过企业级大数据 OLAP 引擎对海量数据进行数据预计算,多维统计分析报表查询响应时效从“半小时”级提升到“秒”级,大幅提升用户分析效率,已初步形成生产力。目前系统已开放给1000多个总分公司机构、4000多名分析用户使用,其中车险核心用户1000多人,全司平均使用率67次/人。截止当年,公司相关系数为强相关,环比上一年的弱相关,配置能力提升明显,有效解决分公司资源“往哪投、投得了、敢于投”的问题,全面实现业财融合。
#04
运用 Kyligence 加速相关性分析
因果关系固然重要,但如果相关关系能够将预测的效果与成本控制在合理匹配的程度,能够支撑商业决策就是最大的价值。
相关系数在统计学里已经存在了很多年了,但是随着智能设备的普及,数据量的膨胀使得相关性的计算也遇到了性能上的瓶颈。Kyligence 智能数据云平台可以对接多个 BI 或者 Excel 工具实现相关性分析。
在 Kyligence Enterprise 中导入数据并按需求创建模型,在设置模型度量时添加 CORR 函数、选择 CORR 表达式,即可开启查询基于海量数据的相关性分析啦~
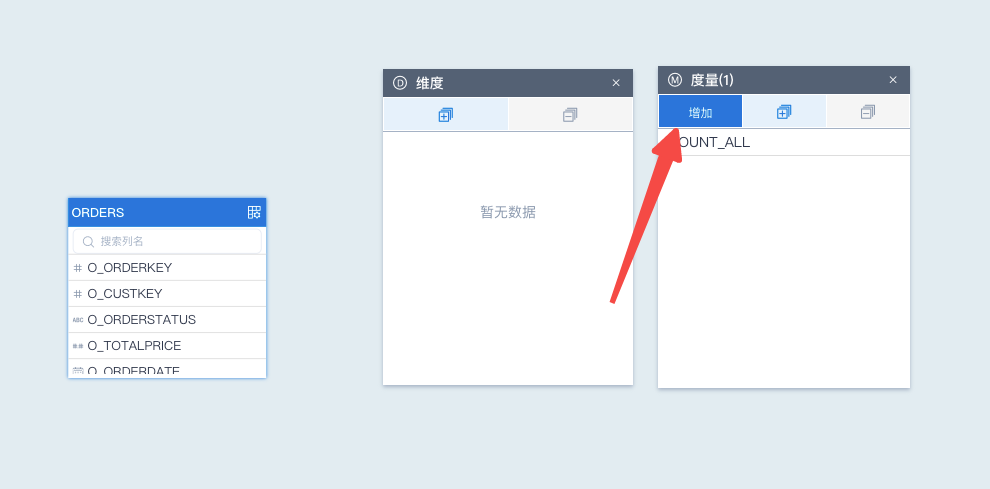
1. 添加度量页面
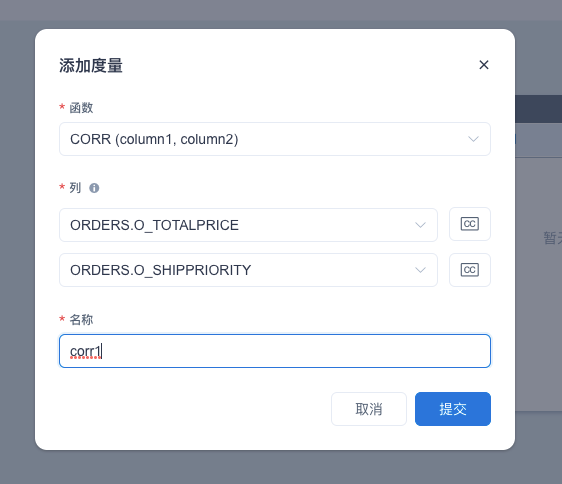
2. 选择 CORR 表达式

3. SQL 查询
#05
相关性分析在金融领域的应用
了解了相关性分析的功能原理,我们将继续介绍一些相关性分析在金融领域的应用场景,来带您领略相关性分析给企业级用户能带来哪些价值。
1.反欺诈
例如,一个数据集包含 80 个描述公司财务状况或健康状况的财务比率变量(例如短期偿债能力变量、现金流量能力变量、营运能力变量等),这些变量可能对检测欺诈行为具有指示性或相关性。然而,这些财务比率变量中的许多变量通常具有很强的关联性。换句话说,这些变量中有许多是重叠的。这可以解释为这些比率变量是由相同的基本信息衍生出来的。因此,人们更倾向于通过减少金融指数的数量来合并或总结原来的一大堆比率,这可以通过主成分分析(PCA)来实现。
此外,新的财务指数最好是不相关的,这样它们可以被纳入欺诈检测模型,而不会导致最终的模型变得不稳定。解释变量或预测变量之间的相关性,即所谓的多重线性,可能会导致模型不稳定。模型的稳定性或稳健性是指根据观察样本估计的模型参数的准确值的稳定性。如果这些参数的值严重依赖于诱导模型的确切观测样本,那么该模型就被称为不稳定的。
事实上,参数值表达了解释变量或预测变量与因变量或目标变量之间的关系。当确切的关系在不同的观察样本中差异很大时,就会对这种假定关系的确切性质和可靠性产生疑问。当一个模型中包含的解释变量是相关的,通常情况下,所产生的模型是不稳定的。因此,通常会进行输入选择程序,使用过滤器方法,或者使用主成分分析法得出一组新的因素来解决这个问题,因为所得出的新变量(即主成分,它们之间是不相关的)。
2.基金投资
在金融投资中,投资组合经理常常利用具有负相关性的资产组合配置来分散风险。某基金公司通过计算28个行业的样本,得出纺织服装业和化工业的相关性最高,计算机行业和银行业的相关性最低,相关性越高,“同涨同跌”的概率越高,反之同理。因此建议投资组合经理考虑构建银行和计算机的行业资产组合,来分散经济市场波动带来的风险。
3.债券投资
金融相关性风险:由于金融资产或非金融资产中多个因子相互关联引起的不利变化,而导致的金融损失的风险。
例如一个投资者买了法国的债券,为避免损失,避免法国债券违约,从德国德意志银行购买了德国的债券,来抵消风险。但是如果法国债券和德国债券有着强相关的关系,那么投资者违约的风险性就大大增加。如果市场上的债券、股票、各种主流投资都具强相关,那么市场性的风险也将增加。所以通常来讲,可以通过购买股票负相关的黄金投资来抵消市场性风险。
4.互联网金融 | 用户画像
互联网金融企业常常借助用户画像来了解客户信息,定位目标客户。构建用户画像需要从海量的数据信息中,通过对用户不同维度的分析,精确地提取出有价值的用户数据范围。
对于互联网金融企业,用户收入决定了用户的消费能力,用户收入越高越有价值。为了构建用户画像,选取用户收入、年龄、学历、身高、体重等维度,考虑用户收入与其余各维度间的相关关系。如果某一维度与用户收入呈正相关,则该维度数值越高,用户收入越高。反之呈负相关时,该维度数值越高,用户收入越低。若没有相关性,则该维度与用户收入无关,不建议用于构建用户画像。
#06
总结
相关性分析在传统统计学领域占有一席之地, Kyligence 助力相关性分析在大数据时代的应用变得更加广泛。
CORR 函数是 Kyligence Enterprise 支持的众多函数中的一员。基于分布式计算框架、预计算原理,Kyligence 可以预先将相关系数的各维度组合都计算好存放于低成本的分布式存储,助力企业识别多个商业因素的相关关系,提前对一些快速增长的新兴市场和地区进行战略布局。
关于 Kyligence
Kyligence 由 Apache Kylin 创始团队创建,致力于打造下一代智能数据云平台,为企业实现自动化的数据服务和管理。基于机器学习和 AI 技术,Kyligence 从多云的数据存储中识别和管理最有价值数据,并提供高性能、高并发的数据服务以支撑各种数据分析与应用,同时不断降低 TCO。Kyligence 已服务中国、美国及亚太的多个银行、保险、制造、零售等客户,包括建设银行、浦发银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、一汽、安踏、YUMC、Costa、UBS、Metlife、AppZen 等全球知名企业和行业领导者。公司已通过 ISO9001,ISO27001 及 SOC2 Type1 等各项认证及审计,并在全球范围内拥有众多生态合作伙伴。


