




不同的AI模型要求的GPU资源有很大的差别。有的模型可能规模很小,只有几十个卷积层,数千个参数,只要一块GPU卡就可以完成训练。而有的神经网络模型则有多达几百个隐藏层,上亿个参数,这样的模型将需要一个分布式的GPU训练环境。Oracle 公有云可以提供这样的分布式训练环境,同时还支持利用OKE(Oracle Kubernetes Engine)进行GPU资源调度。
其通用处理过程包括:
1)根据近似光流对输入帧进行变换扭曲,得到新的画面帧;
2) 使用多层卷积神经网络 (CNN)再对这些帧进行融合和细化。
RIFE模型使用了torchelastic.distributed.launch启动工具定义了所需要的GPU数量和并行计算的节点。
一个AI公司实际的日常工作场景往往是多人在同时执行AI训练任务,往往出现GPU资源争用或GPU资源闲置的情况。
OKE则可以实现GPU资源的合理调度。
此外,GPU服务资源比较昂贵。空闲的时候,开发人员应当及时释放,以节约使用成本。OKE集群的资源池大小可以动态调整,很好地满足了这一需求。
以下是一个POD定义文档的片段,其中要求OKE调度2块GPU。

架构设计的难点在于要同时满足计算动态供应和数据持久存放的需求,其中数据包括训练数据集(约30GB)和生成的训练结果。
而训练时所用的GPU计算节点则是OKE动态分配的。
为此,使用了OCI的文件存储服务。创建了两个NFS文件系统,分别存放训练数据集和生成的训练结果。它们以Kubernetes PV 资源的形式被挂载到Kubernetes POD上面。这样,即便是GPU计算节点被释放了,数据仍然保存在OCI的文件存储中。
整个系统部署在独立的隔间和VCN上,出于安全的考虑, OKE 集群被部署在私有子网中,通过额外部署的堡垒机访问。如下图所示:
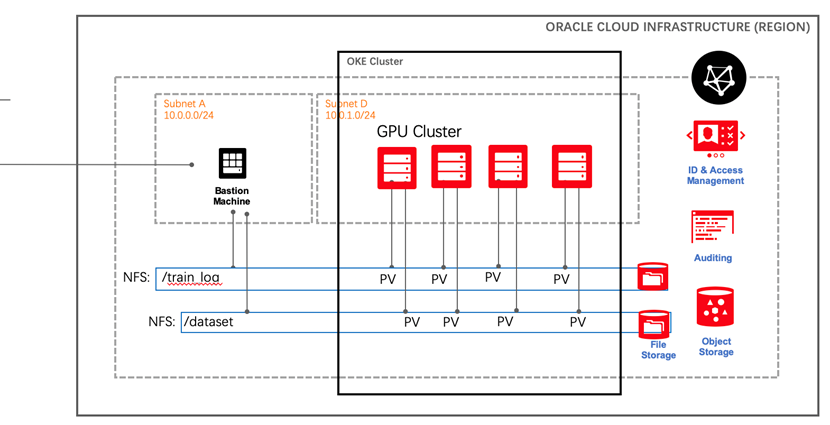
创建OKE集群
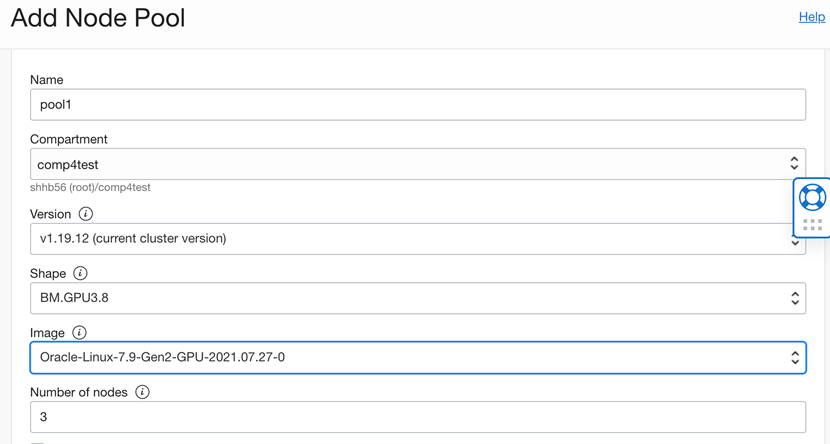
在OCI 控制台上创建OKE集群非常简便,这里不一一赘述了。创建过程中需要注意的是,在定义Pool 的时候要选择GPU类型的机型,并且选择支持GPU的image。
创建NFS Filesystem并制作PV
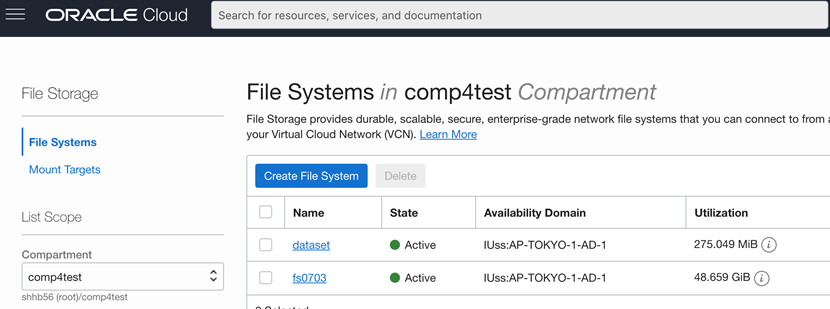
在OCI 控制台上创建NFSfilesystem非常简单,输入文件系统名称,建立Mount target即可,创建好的两个文件系统如下图所示。
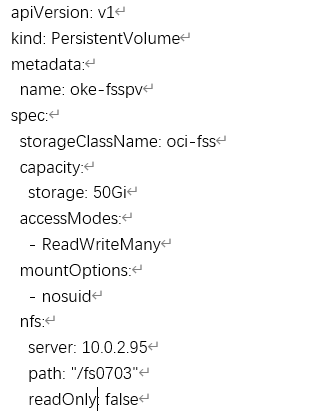
然后将文件系统配置为Kubernetes PV, 下面是一个Yaml 文件例子:
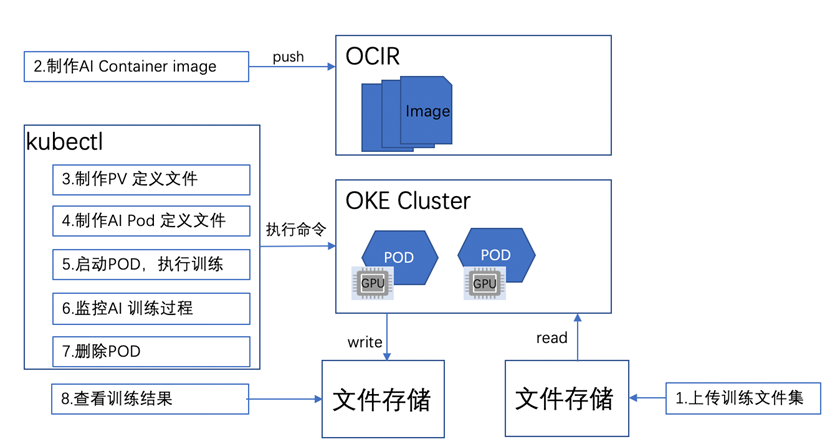
完整的部署过程包括:
将训练用的数据集上传到NFS文件系统中;
利用Github 中的代码制作Docker image, 并且发布到OCIR 容器注册库;
使用Kubectl 工具执行制作好的PV定义文件,POD定义文件,并创建POD;
OKE将按照POD定义文件调度合适GPU资源,启动POD;
训练完成之后,生成的模型文件将被写入到NFS 文件存储中。可以下载使用。
如下图所示:
下面的动图是利用训练好的模型,对前后两张图像进行补帧之后,形成的连续动态画面:


作者简介
郭钧,甲骨文云计算首席咨询顾问。专注于甲骨文云计算相关产品和解决方案。具有超过15年的咨询服务经验。熟悉电信、金融、交通、制造等行业。您可以通过jun.guo@oracle.com与他联系。



