




Hadoop集群模式安装(Cluster mode)
Hadoop源码编译
安装包、源码包下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/复制
为什么要重新编译Hadoop源码?
首先第一个问题就是先要搞定我们的安装包,根据官方提供的下载地址,我们可以看到里面有两个核心的包,一个叫做src是源码包,另一个包是我们官方编译好的安装包,正常情况下,如果是非生产环境,我们直接使用官方的安装包就可以了,但这里涉及到一个关键点,就是源码编译,因为官方提供的安装包,不支持本地的库。
那为什么要进行源码编译呢,首先,这个软件是开源的,源码我们能看的到,如果你觉的某些地方逻辑写的不好,或者并不适合你,我们是可以修改这个源码的,所以需要重新编译。第二点,就是软件的运行,是需要系统支持的,但是呢,我们用的操作系统之间,是存在差异的,就比如linux那么多的发行版本,之间是存在本地库环境差异的,而hadoop的本地库操作,是需要本地库支持的,比如读写IO流操作等等。
这个时候,为了让我们的hadoop运行的更加稳定,兼容性更好,匹配我们的本地环境,最好就是下载源码重新编译。
修改源码、重构源码
匹配不同操作系统本地库环境
Hadoop某些操作比如压缩
IO需要调用系统本地库(.so|.dll)

如何编译Hadoop?
那么怎么样编译呢,在我们的源码包当中,有一个文件描述了你需要做的哪些动作,安装什么软件,如果嫌编译麻烦,可以直接使用hadoop提供好的编译安装包。
编译源码教程 https://www.modb.pro/doc/59872
源码包根目录下文件:BUILDING.txt
编译好的安装包:
编译好的Hadoop安装包,支持了一个叫做snappy的数据压缩。
hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
下载地址:安装包下载 https://www.modb.pro/download/520649
Step1:集群角色规划
搞定安装包的问题之后,接下来就涉及到集群角色的规划,举个例子,公司给你了2000台服务器,让你搭建hadoop集群,还有其他软件,请问你要做一个怎么样的规划,如果我们想让这个规划更加何理,需要了解软件,硬件的各种特性。
举个例子,比如某个软件运行的时候需要的内存要大,怎么办呢,你就部署到内存大的机器上,两个角色进程互相冲突打架怎么办,这些都是集群规划要考虑的问题,规划的准则和注意事项如下:
- 角色规划的准则
根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上
- 角色规划注意事项
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起
- 我们准备三台虚拟机,部署的角色如下:
| 服务器 | 运行角色 |
|---|---|
| node1 | namenode, datanode, resourcemanager, nodemanager |
| node2 | secondarynamenode, datanode, nodemanager |
| node3 | datanode,nodemanager |
Step2:服务器基础环境准备
我们在windows下安装软件的时候,没有那么麻烦,基本上不配置基础环境,点击下一步下一步就可以了,但是我们现在位于linux上,由三台机器构成的集群,假如一台机器在美国,一台机器在新疆,互相一通信就凉凉,时间差过大,所以这些小的服务器,什么时间同步、免密登录、防火墙没有关闭等,只要有一台机器没有做到位,那后面安装的分布式软件,就可能会报错,所以说这一点非常重要。
配置教程 https://www.modb.pro/doc/59872
- 修改主机名(3台机器)
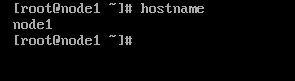
首先我们需要保证每台主机在网络上有独一无二的主机名,我们的三台机器分别叫做node1,node2,node3,我们可以使用vim编辑器修改/etc/hostname文件设置集群的名称
vim /etc/hostname # 分别修改集群三台主机的名称为 hostname # 查看主机名称复制
- Hosts映射(3台机器)
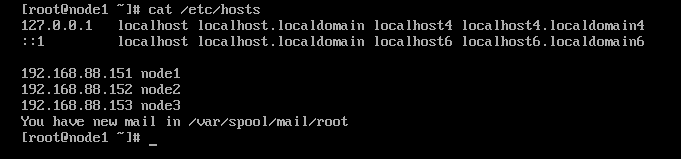
我们在生产经营过程中间发现ip地址太长,不好记怎么办,可以修改/etc/hosts文件,让主机名和ip地址形成映射关系,也就是给IP地址起个简单的名字,可以使用cat命令查看hosts文件
vim /etc/hosts 192.168.88.151 node1 192.168.88.152 node2 192.168.88.153 node3 cat /etc/hosts # 查看映射关系复制
- 防火墙关闭(3台机器)
下一步需要进行的就是一个防火墙的关闭,以及禁止他开机启动,这个防火墙本身是一个好东西,但是如果我们在局域网环境中把防火墙打开的话,好多端口就被他屏蔽了,那软件之间就不能正常相互通信,所以最好把它关闭,注意,stop是当前关闭,disable是永久关闭。
systemctl stop firewalld.service # 关闭防火墙 systemctl disable firewalld.service # 禁止防火墙开启自启 systemctl status firewalld # 查看防火墙状态复制

- ssh免密登录(node1执行->node1|node2|node3)
正常情况下,我们从一台机器访问另一台机器,我们是需要输入密码的,如果集群机器比较多,安装软件的过程、集 群启动就很麻烦,ssh这个东西,可以让我们直接进行免密码登录的操作。这个比简单,我们只要通过内部指令,生成公钥和私钥,拷贝到其他主机即可。
ssh-keygen # 4个回车生成公钥、私钥 ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3复制
- 集群时间同步(3台机器)
接下来我们做时间同步工作,时间同步使用的是我们的ntp协议,跟我们的网络授时服务器做一个同步,这里我们同步的时一个阿里云的服务器ntp4.aliyun.com,需要yum安装ntpdate,这个时候一定保证网络通畅,不成功就多试几次。
yum -y install ntpdate ntpdate ntp4.aliyun.com复制

- 创建统一工作目录(3台机器)
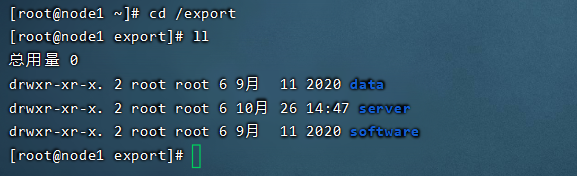
我们去安装软件,理论上安装到哪个目录都行,但是在真实的生产环境当中,企业会给你一个约束,会创建一个统一的工作目录,软件必须放这边,数据要放那边,安装包要放那里等等。我们可以使用mkdir创建。
mkdir -p /export/server/ # 软件安装路径 mkdir -p /export/data/ # 数据存储路径 mkdir -p /export/software/ # 安装包存放路径复制
- JDK 1.8安装(3台机器)
我们的hadoop使用java语言写的,运行hadoop就需要jdk给他提供相关的支撑,安装比较简单,我们可以在第一台机器安装,然后发送给其他机器就可以了。安装完成以后需要配置环境变量,说明java安装在哪里,他的bin目录在哪里。
安装包下载 https://www.modb.pro/download/520679
# JDK 1.8安装 # 上传 jdk-8u241-linux-x64.tar.gz到/export/server/目录下 cd /export/server/ tar zxvf jdk-8u241-linux-x64.tar.gz # 配置环境变量 vim /etc/profile export JAVA_HOME=/export/server/jdk1.8.0_241 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # 重新加载环境变量文件 source /etc/profile复制

安装完成之后,可以使用 java -version指令去验证。

验证完成之后我们只是安装了一台机器的java环境,当然,我们一台一台安装也是可以的,我们可以用到scp命令直接拷贝到其他机器上。root用户node2、node3主机。但是大家别忘了,/etc/profile文件也需要拷贝一份过去。
# java拷贝到node2,node3 scp -r /export/server/jdk1.8.0_241/ root@node2:/export/server/jdk1.8.0_241/ scp -r /export/server/jdk1.8.0_241/ root@node3:/export/server/jdk1.8.0_241/ # 配置文件拷贝到node2,node3 scp /etc/profile root@node2:/etc/profile scp /etc/profile root@node3:/etc/profile复制
完成之后记得重新加载环境变量文件source /etc/profile
各集群主机可以使用java -version指令去验证
至此,我们的基础环境搭建就完成了。
传送门
(一) 初探Hadpoop
(二) hadoop发行版本及构架的变迁
(三) hadoop安装部署集群介绍
(四) hadoop安装部署-基础环境搭建
(五) hadoop安装部署-配置文件详解
(六) hadoop集群启停命令、Web UI
(七) hadoop-HDFS文件系统基础
(八) Hadoop-HDFS起源发展及设计目标
(九) Hadoop-HDFS重要特性、shell操作
(十) Hadoop-HDFS工作流程与机制
(十一) 如何理解Hadoop MapReduce思想
(十二) map阶段和Reduce阶段执行过程
待更新
文章被以下合辑收录
评论

 0 点赞
0 点赞


