




HDFS简介
HDFS它并不是一个单词,而是一连串单词的缩写(Hadoop Distributed File System ),意为:Hadoop分布式文件系统。不管我们用多少词汇修饰他,关键词就是文件系统,就是用来存储文件的,只不过他是一个分布式的文件系统,就意味着横跨多台机器。
HDFS系统作为Apache Hadoop三大核心组件之一,十分的关键,处于hadoop整个生态圈的最底层,因为大数据第一个要解决的就是海量数据存储的问题,如果连存储都没有解决掉,所有的分析、应用又从何谈起呢,所以他的地位非常重要。
- HDFS主要是解决大数据如何存储问题的。分布式意味着是HDFS是横跨在多台计算机上的存储系统。
- HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据(比如TB 和PB)。
- HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。
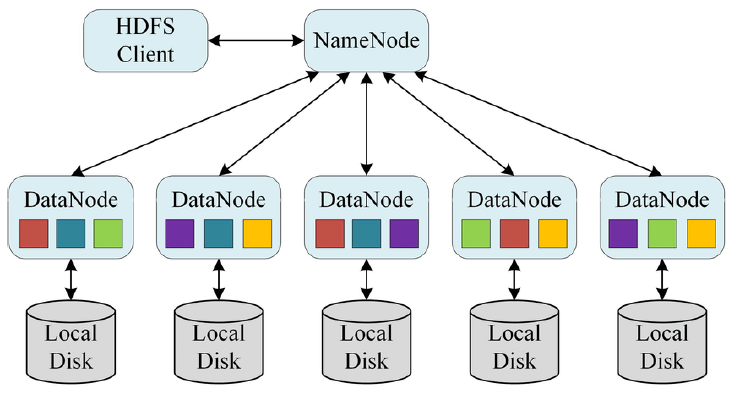
分布式就意味着多台机器,我们看一下上图,左边就是hdfs的客户端,client代表我们大的用户,右边是一个namenode带领5个datanode构成了一个一主多从的分布式架构,整个hdfs虽然是运行在多个机器上,但是它对外只提供了一个访问的入口,这样就使得用户层面上,看到的hdfs结构很像我们传统的文件目录树结构,降低了用户使用的难度,但是注意,虽然这时候看起来hdfs像一个单机系统,但其实,他是一个分布式文件系统。
HDFS起源发展
我们的卡大爷Doug Cutting领导Nutch项目研发,Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能。随着爬虫抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。这个问题其实谷歌也遇到了,但是谷歌并不开源,它在2003年的时候, 发表的论文为该问题提供了可行的解决方案。
- 《分布式文件系统(GFS),可用于处理海量网页的存储》
- Nutch的开发人员完成了相应的开源实现HDFS,并从Nutch中剥离和MapReduce成为独立项目HADOOP。

HDFS设计目标
我们想使用一个软件,它到底好还是不好,用起来怎么样,就是这款软件的设计目标决定的。就比如我们去网上买一个玻璃水壶,然后设计目标告诉我们,这个水壶只能承受不超过80度的热水,如果超过就爆炸,当我们看到这个说明,就知道了适合哪里用。hdfs也一样,接下来我们一起来看一下HDFS设计目标的问题,卡大爷团队在设计之初就有一些目标,到底存大数据,还是小数据等等,所以有几个重要的概念需要大家去理解,一起来看一下他的设计目标:
- 硬件故障(Hardware Failure)是常态,HDFS可能有成百上千的服务器组成,每一个组件都有可能出现故障。因此故障检测和自动快速恢复是HDFS的核心架构目标。
- HDFS上的应用主要是以流式读取数据(Streaming Data Access)。HDFS被设计成用于批处理,而不是用户交互式的。相较于数据访问的反应时间,更注重数据访问的高吞吐量。
- 典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件(Large Data Sets)。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
简单来理解,分布式系统最怕的就是某个机器出问题,或者硬盘挂掉,所以我们的hdfs系统内存的文件一定要安全,设置各种冗余保证数据有备份能恢复。第二个就是hdfs系统适合大吞吐量的存储,忽视的是数据的访问时间,也就是说,我们访问数据的延迟会比较高,没有实时的交互性,也就是说,你的数据越大,hdfs越开心,数据越小,越麻烦。
- 大部分HDFS应用对文件要求的是write-one-read-many访问模型。一个文件一旦创建、写入、关闭之后就不需要修改了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
- 移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效。将计算移动到数据附近,比之将数据移动到应用所在显然更好。
- HDFS被设计为可从一个平台轻松移植到另一个平台。这有助于将HDFS广泛用作大量应用程序的首选平台。
write-one-read-many是一个关键的设计要点,hdfs认为,大的数据一旦存储,就不用再去修改了,接下来就是各种的读取,各种的分析,既然是这样的场景,那么hdfs就不支持文件修改。可以上传,可以追加,可以删除,就是不能修改,不是因为技术实现不了,而是因为设计的时候,就没有追求这个点。
数据比较大的时候,它认为数据移动很费时间,我们可以吧程序移动过来,还支持我们不同平台之间的移植。
了解了他的设计目标之后,我们在使用的时候一定要想明白他的优点缺点等等。
HDFS应用场景
基于刚才了解的设计目标,我们就可以清楚的知道hdfs的应用场景,它只适合大文件场景,数据越大越开心,比如过去100年人口增长数据等。
-
适合场景:大文件
- 数据流式访问
- 一次写入多次读取低成本部署,廉价PC
- 高容错
-
不适合场景:小文件
- 数据交互式访问
- 频繁任意修改
- 低延迟处理
传送门
(一) 初探Hadpoop
(二) hadoop发行版本及构架的变迁
(三) hadoop安装部署集群介绍
(四) hadoop安装部署-基础环境搭建
(五) hadoop安装部署-配置文件详解
(六) hadoop集群启停命令、Web UI
(七) hadoop-HDFS文件系统基础
(八) Hadoop-HDFS起源发展及设计目标
(九) Hadoop-HDFS重要特性、shell操作
(十) Hadoop-HDFS工作流程与机制
(十一) 如何理解Hadoop MapReduce思想
(十二) map阶段和Reduce阶段执行过程
待更新
