




「目录」
数据聚合与分组运算
Data Aggregation and Group Operations
10.1 => GroupBy机制
10.2 => 数据聚合
10.3 => apply:拆分 - 应用 - 合并
10.4 => 透视表和交叉表

这篇笔记还是接着上篇数据聚合的内容讲的,上篇内容写了如何使用groupby对数据分组,然后应用min、max、std等聚合的方法。
这篇呢,拓展了以下内容:
如何改变列名 如何对不同的列应用不同的函数
下面是本篇笔记需要用到的库
import numpy as np
import pandas as pd复制
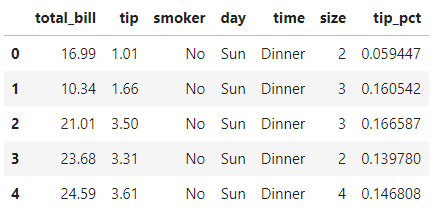
还是前面原书举过的一个小费的例子。使用read_csv读取csv数据,添加一个小费百分比的的列tip_pct:
tips = pd.read_csv(r'.\tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()复制
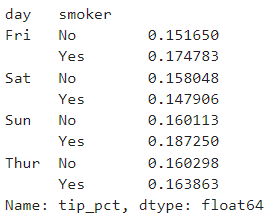
我们根据'day'和'smoker'来分组,然后查看分组后的平均小费百分比
grouped = tips.groupby(['day', 'smoker'])
grouped_pct = grouped['tip_pct']
grouped_pct.agg('mean')复制
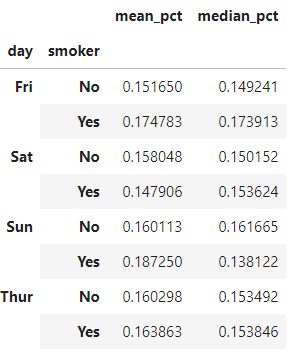
如何改变列名
若我们传入一个元组组成的列表,每个元组的第一个元素就会被用作DataFrame列名:
grouped_pct.agg([('mean_pct', 'mean'), ('median_pct', 'median')])复制
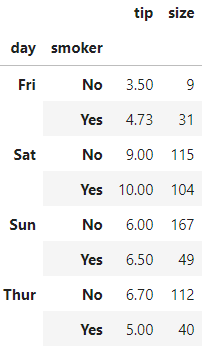
如何对不同的列应用不同的函数
若我们想要对不同的列应用不同的函数,我们可以向agg传入一个从列名映射到函数的字典
grouped.agg({'tip' : np.max, 'size' : 'sum'})复制
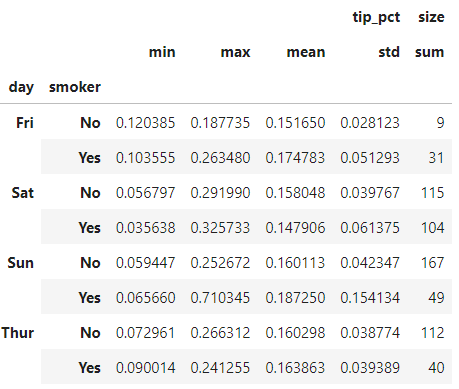
grouped.agg({'tip_pct' : ['min', 'max', 'mean', 'std'], 'size' : 'sum'})复制
那就这样吧,BYE-BYE
往期回顾


Stay hungry, stay foolish
文章转载自Yuan的学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
571次阅读
2025-04-14 09:40:20
Hologres x 函数计算 x Qwen3,对接MCP构建企业级数据分析 Agent
阿里云大数据AI技术
538次阅读
2025-05-06 17:24:44
一页概览:Oracle GoldenGate
甲骨文云技术
471次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
466次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
355次阅读
2025-04-18 10:01:22
千万级数据秒级响应!碧桂园基于 EMR Serverless StarRocks 升级存算分离架构实践
阿里云大数据AI技术
294次阅读
2025-04-27 15:28:51
Coco AI 入驻 GitCode:打破数据孤岛,解锁智能协作新可能
极限实验室
246次阅读
2025-05-04 23:53:06
关于征集数据库标准体系更新意见和数据库标准化需求的通知
数据库标准工作组
239次阅读
2025-04-11 11:30:08
XCOPS广州站:从开源自研之争到AI驱动的下一代数据库架构探索
韩锋频道
212次阅读
2025-04-29 10:35:54
优炫数据库成功应用于晋江市发展和改革局!
优炫软件
198次阅读
2025-04-25 10:10:31




