




「目录」
数据聚合与分组运算
Data Aggregation and Group Operations
10.1 => GroupBy机制
10.2 => 数据聚合
10.3 => apply:拆分 - 应用 - 合并
10.4 => 透视表和交叉表
GroupBy机制
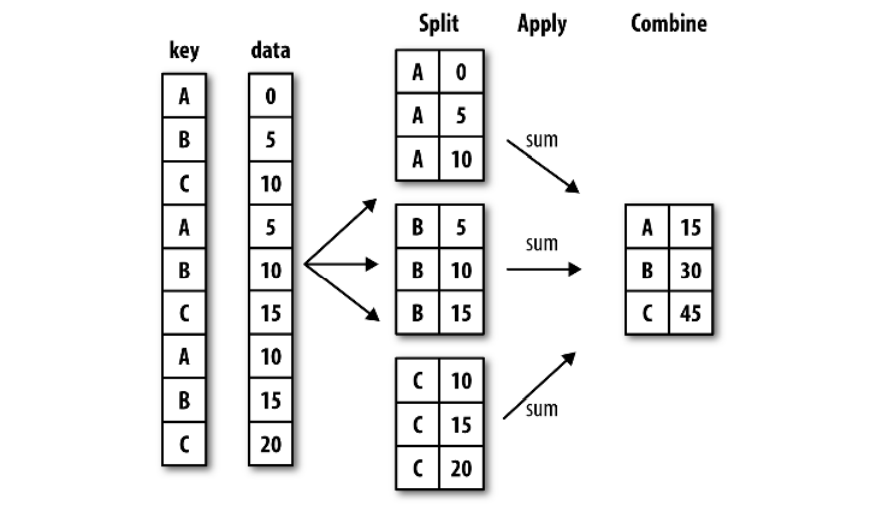
我们常常需要对数据进行分组来计数、求平均值、求和或其他操作。
groupby就是pandas对象(Series或DataFrame)中的数据会根据我们提供的一个或多个键被分为多组。
然后,我们可以将函数应用到每个分组产生新值。
最后,将函数执行的结果合并到最终的对象中。
In [1]: import numpy as np
In [2]: import pandas as pd
In [3]: df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'], 'key2' : ['one', 'two', 'one', 'two', 'one'], 'data1' : np.random.randn(5), 'data2' : np.random.randn(5)})
In [4]: df
Out[4]:
key1 key2 data1 data2
0 a one -0.756564 -0.488013
1 a two 0.395095 0.187971
2 b one -0.539514 -1.797890
3 b two -0.145949 0.896793
4 a one -0.140692 0.869048复制
我们现在想对Key1进行分组,并计算data1列的平均值。
grouped是一个groupby对象,访问它并不会看到什么,但是现在它有了分组执行运算所需的信息。
In [5]: grouped = df['data1'].groupby(df['key1'])
In [6]: grouped
Out[6]: <pandas.core.groupby.generic.SeriesGroupBy object at 0x000002C25DDA77B8>复制
现在可以调用GroupBy的mean, sum, count方法来对每组计算平均值,求和还有统计数量:
In [7]: grouped.mean()
Out[7]:
key1
a -0.167387
b -0.342732
Name: data1, dtype: float64
In [8]: grouped.sum()
Out[8]:
key1
a -0.502161
b -0.685463
Name: data1, dtype: float64
In [9]: grouped.count()
Out[9]:
key1
a 3
b 2
Name: data1, dtype: int64复制
也可以传入多个数组的列表:
In [10]: means = df['data1'].groupby([df['key1'], df['key2']]).mean()
In [11]: means
Out[11]:
key1 key2
a one -0.448628
two 0.395095
b one -0.539514
two -0.145949
Name: data1, dtype: float64复制
对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组
In [12]: for name, group in df.groupby('key1'):
...: print(f'name : {name}')
...: print(group)
...:
name : a
key1 key2 data1 data2
0 a one -0.756564 -0.488013
1 a two 0.395095 0.187971
4 a one -0.140692 0.869048
name : b
key1 key2 data1 data2
2 b one -0.539514 -1.797890
3 b two -0.145949 0.896793复制
通过字典分组
如果字典中包含分组的信息,则也可以将字典传给groupby。
In [13]: people = pd.DataFrame(np.random.randn(5, 5), columns = ['a', 'b', 'c', 'd', 'e'], index = ['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
In [14]: people.iloc[2:3, [1, 2]] = np.nan
In [15]: people
Out[15]:
a b c d e
Joe -1.115527 0.473344 2.340781 -0.184186 1.064539
Steve -1.154502 0.398595 -0.842444 -1.737123 2.263129
Wes 0.239473 NaN NaN -1.391547 0.555808
Jim 0.077415 1.843222 0.159626 0.371162 -1.556054
Travis -1.073688 0.192671 -0.087655 0.137067 0.476065复制
比如我们将下面DataFrame的a-e列,分成三组'red','blue'和'orange'。
In [16]: mapping = {'a' : 'red', 'b' : 'red', 'c' : 'blue', 'd' : 'blue', 'e' : 'red', 'f' : 'orange'}
In [17]: by_column = people.groupby(mapping, axis=1)
In [18]: by_column.sum()
Out[18]:
blue red
Joe 2.156595 0.422355
Steve -2.579566 1.507221
Wes -1.391547 0.795281
Jim 0.530788 0.364582
Travis 0.049411 -0.404953复制
结果中没有orange这一列,是因为不存在'f'列。
通过索引级别分组
若是层次化索引,我们还可以根据轴索引的级别分组:
In [21]: columns = pd.MultiIndex.from_arrays([['CN', 'CN', 'CN', 'US', 'US'],['Shanghai', 'Beijing', 'Hangzhou', 'NewYork', 'Washington']], names = ['Country', 'City'])
In [23]: hier_df = pd.DataFrame(np.random.randn(4,5), columns=columns)
In [24]: hier_df
Out[24]:
Country CN US
City Shanghai Beijing Hangzhou NewYork Washington
0 -0.888773 0.765340 1.235451 1.242831 -0.461181
1 1.299011 0.089933 0.435047 0.648429 -0.289734
2 -1.494521 0.116480 1.485656 0.558251 -1.453102
3 0.395570 0.238149 1.120664 -0.509797 1.286999
In [27]: hier_df.groupby(level='Country', axis=1).count()
Out[27]:
Country CN US
0 3 2
1 3 2
2 3 2
3 3 2复制
就这样吧,bye-bye
往期回顾
Pandas绘制分面网格


Stay hungry, stay foolish
文章转载自Yuan的学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
金仓数据库26套!宁波市司法局信息系统适配改造(一期)采购项目
天下观查
373次阅读
2025-03-21 10:33:59
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
312次阅读
2025-04-07 09:44:54
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
264次阅读
2025-04-14 09:40:20
为什么总是很难客观评价某个国产数据库产品
白鳝的洞穴
217次阅读
2025-03-19 11:21:09
关于征集数据库标准体系更新意见和数据库标准化需求的通知
数据库标准工作组
212次阅读
2025-04-11 11:30:08
国产数据库时代,一些20年前的数据库设计小技巧又可以拿出来用了
白鳝的洞穴
205次阅读
2025-04-10 11:52:51
史诗级革新 | Apache Flink 2.0 正式发布
严少安
194次阅读
2025-03-25 00:55:05
TDengine 3.3.6.0 发布:TDgpt + 虚拟表 + JDBC 加速 8 大升级亮点
TDengine
166次阅读
2025-04-09 11:01:22
Apache Doris 2025 Roadmap:构建 GenAI 时代实时高效统一的数据底座
SelectDB
166次阅读
2025-04-03 17:41:08
GoldenDB助力江苏省住房公积金国产数据库应用推广暨数字化发展交流会成功举办
GoldenDB分布式数据库
157次阅读
2025-04-07 09:44:49

