




Catalyst优化器是Spark引擎中非常重要的组成部分,也是近年来Spark社区项目重点投入、并且发展十分迅速的核心模块,对于Spark任务的性能提升起到了关键的基础作用。
我们知道,在Spark1.6之前开发人员是通过Spark的RDD编程接口来实现对大规模数据的分析和处理的,到了Spark1.6版本后推出了DataSet和DataFrame的编程接口,这种数据结构与RDD的主要区别在于其携带了结构化数据的Schema信息,从而可以被Spark Catalyst用来做进一步的解析和优化;而Spark SQL则是比DataSet和DataFrame编程接口更为简单易用的大数据领域语言,其用户可以是开发工程师、数据科学家、数据分析师等,并且与其他SQL语言类似,可以通过SQL引擎将SQL预先解析成一棵AST抽象语法树;同时,AST抽象语法树、DataSet及DataFrame接下来均会被Spark Catalyst优化器转换成为Unresolved LogicalPlan、Resolved LogicalPlan,Physical Plan、以及Optimized PhysicalPlan,也就是说带有schema信息的Spark分布式数据集都可以从Spark Catalyst中受益,这也是Spark任务性能得以提升的核心所在。
值得一提的是,在物理计划树的生成过程中,首先会将数据源解析成为RDD,也即在Spark SQL的物理计划执行过程中所操作的对象实际是RDD,一条Spark SQL在生成最终的物理计划后仍然会经过前面文章中所提到的生成DAG、划分Stage、并将taskset分发到特定的executor上运行等一系列的任务调度和执行过程来实现该Spark SQL的处理逻辑。
接下来,本文将着重讲解Spark SQL逻辑计划的相关实现原理,在后续的文章中会继续解析Spark SQL的物理计划。
生成Unresolved LogicalPlan
用户可以通过spark-sql等客户端来提交sql语句,在sparksession初始化时通过BaseSessionStateBuilder的build()方法始化SparkSqlParser、Analyser以及SparkOptimizer对象等:
def build(): SessionState = {
new SessionState(
session.sharedState,
conf,
experimentalMethods,
functionRegistry,
udfRegistration,
() => catalog,
sqlParser,
() => analyzer,
() => optimizer,
planner,
() => streamingQueryManager,
listenerManager,
() => resourceLoader,
createQueryExecution,
createClone,
columnarRules,
queryStagePrepRules)
}复制
当用户程序调用SparkSession的sql接口时即开始了解析sql语句并执行对数据处理的过程:
def sql(sqlText: String): DataFrame = withActive {
val tracker = new QueryPlanningTracker
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) {
sessionState.sqlParser.parsePlan(sqlText)
}
Dataset.ofRows(self, plan, tracker)
}复制
其中通过AbstractSqlParser的parsePlan方法将sql语句转换成抽象语法树:
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}复制
1、从SqlBaseParser的singleStatement()方法开始基于ANTLR4 lib库来解析sql语句中所有的词法片段,生成一棵AST抽象语法树;
2、访问AST抽象语法树并生成Unresolved 逻辑计划树:
1)访问SingleStatementContext节点:
SingleStatementContext是整个抽象语法树的根节点,因此以AstBuilder的visitSingleStatement方法为入口来遍历抽象语法树:
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
visit(ctx.statement).asInstanceOf[LogicalPlan]
}
...
public T visit(ParseTree tree) {
return tree.accept(this);
}复制
2)根据访问者模式执行SingleStatementContext节点的accept方法:
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof SqlBaseVisitor ) return ((SqlBaseVisitor<? extends T>)visitor).visitSingleStatement(this);
else return visitor.visitChildren(this);
}
...
@Override public T visitSingleStatement(SqlBaseParser.SingleStatementContext ctx) { return visitChildren(ctx); }复制
3)迭代遍历整棵AST Tree:
@Override
public T visitChildren(RuleNode node) {
T result = defaultResult();
int n = node.getChildCount();
for (int i=0; i<n; i++) {
if (!shouldVisitNextChild(node, result)) {
break;
}
ParseTree c = node.getChild(i);
T childResult = c.accept(this);
result = aggregateResult(result, childResult);
}
return result;
}复制
根据以上代码,在遍历AST 树的过程中,会首先解析父节点的所有子节点,并执行子节点上的accept方法来进行解析,当所有子节点均解析为UnresolvedRelation或者Expression后,将这些结果进行聚合并返回到父节点,由此可见,AST树的遍历所采用的是后序遍历模式。
接下来以查询语句中的QuerySpecificationContext节点的解析为例进一步阐述以上过程:
如下为一条基本的sql语句:
select col1 from tabname where col2 > 10复制
QuerySpecificationContext节点下会产生用于扫描数据源的FromClauseContext、过滤条件对应的BooleanDefaultContext、以及投影时所需的NamedExpressionSeqContext节点。
1)FromClauseContext继续访问其子节点,当访问到TableINameContext节点时,访问到tableName的tocken时根据表名生成UnresolvedRelation:
override def visitTableName(ctx: TableNameContext): LogicalPlan = withOrigin(ctx) {
val tableId = visitMultipartIdentifier(ctx.multipartIdentifier)
val table = mayApplyAliasPlan(ctx.tableAlias, UnresolvedRelation(tableId))
table.optionalMap(ctx.sample)(withSample)
}复制
2)BooleanDefaultContext的子节点中分为三个分支:代表Reference的ValueExpressionDefaultContext、代表数值的ValueExpressionDefaultContext、以及代表运算符的ComparisonContext;
例如遍历代表数据值ValueExpressionDefaultContext及其子节点,直到访问到IntegerLiteralContext:
override def visitIntegerLiteral(ctx: IntegerLiteralContext): Literal = withOrigin(ctx) {
BigDecimal(ctx.getText) match {
case v if v.isValidInt =>
Literal(v.intValue)
case v if v.isValidLong =>
Literal(v.longValue)
case v => Literal(v.underlying())
}
}复制
而Literal的定义如下,是一个叶子类型的Expression节点:
case class Literal (value: Any, dataType: DataType) extends LeafExpression复制
3)NamedExpressionSeqContext是投影节点,迭代遍历直到RegularQuerySpecificationContext节点,然后通过访问withSelectQuerySpecification方法创建出投影所需的Project Logical Plan:
override def visitRegularQuerySpecification(
ctx: RegularQuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withSelectQuerySpecification(
ctx,
ctx.selectClause,
ctx.lateralView,
ctx.whereClause,
ctx.aggregationClause,
ctx.havingClause,
ctx.windowClause,
from
)
}
...
def createProject() = if (namedExpressions.nonEmpty) {
Project(namedExpressions, withFilter)
} else {
withFilter
}复制
总结一下以上处理过程中所涉及的类之间的关系,如下图所示:
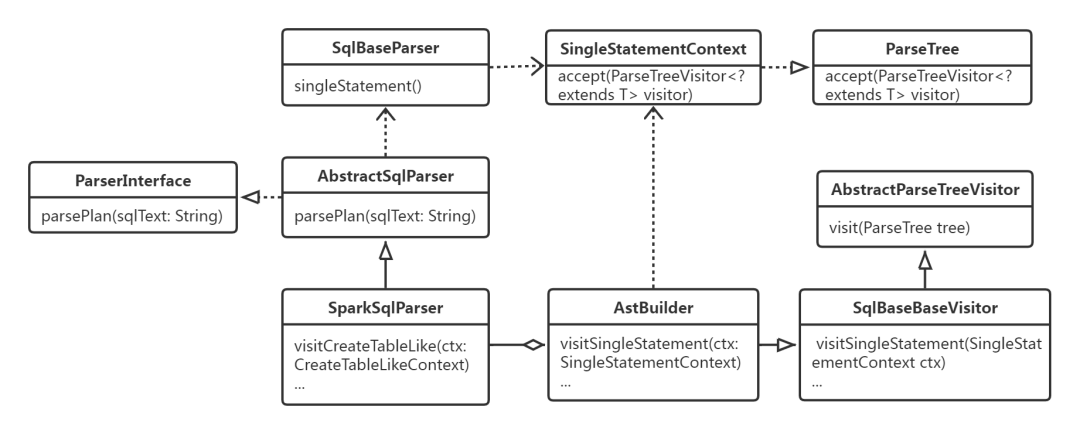
生成Resolved LogicalPlan
Spark Analyser
在SparkSession的sql方法中,对sql语句进行过Parser解析并生成Unresolved LogicalPlan之后则通过执行Dataset.ofRows(self, plan, tracker) 继续进行catalog绑定,数据源绑定的过程如下:
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan, tracker: QueryPlanningTracker)
: DataFrame = sparkSession.withActive {
val qe = new QueryExecution(sparkSession, logicalPlan, tracker)
qe.assertAnalyzed()
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema))
}
...
def assertAnalyzed(): Unit = analyzed复制
由如下实现逻辑可见, analyzed变量是通过懒加载方式初始化的,通过该变量的初始方法可见Spark的catalog实现逻辑主要通过Analyser类来实现的:
lazy val analyzed: LogicalPlan = executePhase(QueryPlanningTracker.ANALYSIS) {
// We can't clone `logical` here, which will reset the `_analyzed` flag.
sparkSession.sessionState.analyzer.executeAndCheck(logical, tracker)
}复制
其中,executeAndCheck方法的执行是通过Analyzer的父类RuleExecutor的execute方法来实现的:
def execute(plan: TreeType): TreeType = {
...
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val startTime = System.nanoTime()
val result = rule(plan)
val runTime = System.nanoTime() - startTime
val effective = !result.fastEquals(plan)
if (effective) {
queryExecutionMetrics.incNumEffectiveExecution(rule.ruleName)
queryExecutionMetrics.incTimeEffectiveExecutionBy(rule.ruleName, runTime)
planChangeLogger.logRule(rule.ruleName, plan, result)
}
...
result
}
iteration += 1
if (iteration > batch.strategy.maxIterations) {
// Only log if this is a rule that is supposed to run more than once.
if (iteration != 2) {
val endingMsg = if (batch.strategy.maxIterationsSetting == null) {
"."
} else {
s", please set '${batch.strategy.maxIterationsSetting}' to a larger value."
}
val message = s"Max iterations (${iteration - 1}) reached for batch ${batch.name}" +
s"$endingMsg"
if (Utils.isTesting || batch.strategy.errorOnExceed) {
throw new TreeNodeException(curPlan, message, null)
} else {
logWarning(message)
}
}
// Check idempotence for Once batches.
if (batch.strategy == Once &&
Utils.isTesting && !blacklistedOnceBatches.contains(batch.name)) {
checkBatchIdempotence(batch, curPlan)
}
continue = false
}
if (curPlan.fastEquals(lastPlan)) {
logTrace(
s"Fixed point reached for batch ${batch.name} after ${iteration - 1} iterations.")
continue = false
}
lastPlan = curPlan
}
planChangeLogger.logBatch(batch.name, batchStartPlan, curPlan)
}
planChangeLogger.logMetrics(RuleExecutor.getCurrentMetrics() - beforeMetrics)
curPlan
}复制
如上代码的主要处理过程如下:
1、遍历的Analyzer类中的batches列表:
通过batches方法获取所有的catalog绑定相关的规则,在Analyzer中包括Substitution、Hints、Resolution、UDF、Subquery等几个规则组;
以较为常见的"Resolution"规则组为例,其具有非常多的规则用于解析函数、Namespace、数据表、视图、列等信息,当然用户也可以子定义相关规则:
Batch("Resolution", fixedPoint,
ResolveTableValuedFunctions ::
ResolveNamespace(catalogManager) ::
new ResolveCatalogs(catalogManager) ::
ResolveInsertInto ::
ResolveRelations ::
ResolveTables ::
ResolveReferences ::
ResolveCreateNamedStruct ::
ResolveDeserializer ::
ResolveNewInstance ::
ResolveUpCast ::
ResolveGroupingAnalytics ::
ResolvePivot ::
ResolveOrdinalInOrderByAndGroupBy ::
ResolveAggAliasInGroupBy ::
ResolveMissingReferences ::
...复制
其中,Batch类的定义如下,包括Batch名称、循环执行策略、具体的规则组集合,循环执行策略Strategy又分为Once和FixedPoint两种,即仅执行一次和固定次数:
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)复制
2、将每个Batch中所有的规则Rule对象实施于该Unsolved LogicalPlan,并且该Batch中规则可能要执行多轮,直到执行的批数等于batch.strategy.maxIterations或者logicalplan与上个批次的结果比没有变化,则退出执行;
其中在Spark 中的定义如下,在spark3.0中默认可最大循环100次:
protected def fixedPoint =
FixedPoint(
conf.analyzerMaxIterations,
errorOnExceed = true,
maxIterationsSetting = SQLConf.ANALYZER_MAX_ITERATIONS.key)
...
val ANALYZER_MAX_ITERATIONS = buildConf("spark.sql.analyzer.maxIterations")
.internal()
.doc("The max number of iterations the analyzer runs.")
.version("3.0.0")
.intConf
.createWithDefault(100)复制
接下来以将ResolveRelations(解析数据表或者视图)规则应用于Unresolved LogicalPlan的解析过程为例,支持解析UnresolvedRelation、UnresolvedTable、UnresolvedTableOrView等多种未解析的数据源:
def apply(plan: LogicalPlan): LogicalPlan = ResolveTempViews(plan).resolveOperatorsUp {
...
case u: UnresolvedRelation =>
lookupRelation(u.multipartIdentifier).map(resolveViews).getOrElse(u)
case u @ UnresolvedTable(identifier) =>
lookupTableOrView(identifier).map {
case v: ResolvedView =>
u.failAnalysis(s"${v.identifier.quoted} is a view not table.")
case table => table
}.getOrElse(u)
case u @ UnresolvedTableOrView(identifier) =>
lookupTableOrView(identifier).getOrElse(u)
}复制
当解析对象为UnresolvedRelation实例时,调用lookupRelation方法来对其进行解析,通过SessionCatalog或者扩展的CatalogPlugin来获取数据源的元数据,并生成Resolved LogicalPlan:
private def lookupRelation(identifier: Seq[String]): Option[LogicalPlan] = {
expandRelationName(identifier) match {
case SessionCatalogAndIdentifier(catalog, ident) =>
lazy val loaded = CatalogV2Util.loadTable(catalog, ident).map {
case v1Table: V1Table =>
v1SessionCatalog.getRelation(v1Table.v1Table)
case table =>
SubqueryAlias(
catalog.name +: ident.asMultipartIdentifier,
DataSourceV2Relation.create(table, Some(catalog), Some(ident)))
}
...复制
最常见的是SessionCatalog,作为SparkSession级别catalog接口对象,其定义如下,包括ExternalCatalog、GlobalTempViewManager、FunctionRegistry、SQLConf、Hadoop的Configuration、Parser、FunctionResourceLoader对象;其中,ExternalCatalog有两个主要的实现类:HiveExternalCatalog和InMemoryCatalog,而HiveExternalCatalog则主要应用于企业级的业务场景中:
class SessionCatalog(
externalCatalogBuilder: () => ExternalCatalog,
globalTempViewManagerBuilder: () => GlobalTempViewManager,
functionRegistry: FunctionRegistry,
conf: SQLConf,
hadoopConf: Configuration,
parser: ParserInterface,
functionResourceLoader: FunctionResourceLoader)复制
如果采用默认的SessionCatalog,当需要获取数据表时则通过ExternalCatalog实例调用其对应的接口来实现:
override def loadTable(ident: Identifier): Table = {
val catalogTable = try {
catalog.getTableMetadata(ident.asTableIdentifier)
} catch {
case _: NoSuchTableException =>
throw new NoSuchTableException(ident)
}
V1Table(catalogTable)
}
...
def getTableMetadata(name: TableIdentifier): CatalogTable = {
val db = formatDatabaseName(name.database.getOrElse(getCurrentDatabase))
val table = formatTableName(name.table)
requireDbExists(db)
requireTableExists(TableIdentifier(table, Some(db)))
externalCatalog.getTable(db, table)
}复制
接下来如果采用ExternalCatalog接口的实现类HiveExternalCatalog的情况下,则通过HiveClientImpl类从Hive的metadata中类获取用户表的元数据相关信息:
private def getRawTableOption(dbName: String, tableName: String): Option[HiveTable] = {
Option(client.getTable(dbName, tableName, false /* do not throw exception */))
}复制
另外,如需扩展的catalog范围可通过实现CatalogPlugin接口、并且配置“spark.sql.catalog.spark_catalog”参数来实现,例如在iceberg数据湖的实现中通过自定义其catalog来实现其个性化的逻辑:
spark.sql.catalog.spark_catalog = org.apache.iceberg.spark.SparkSessionCatalog复制
3、返回解析后的Resolved LogicalPlan。
以上处理逻辑中所涉及的主要的类之间的关系如下所示:
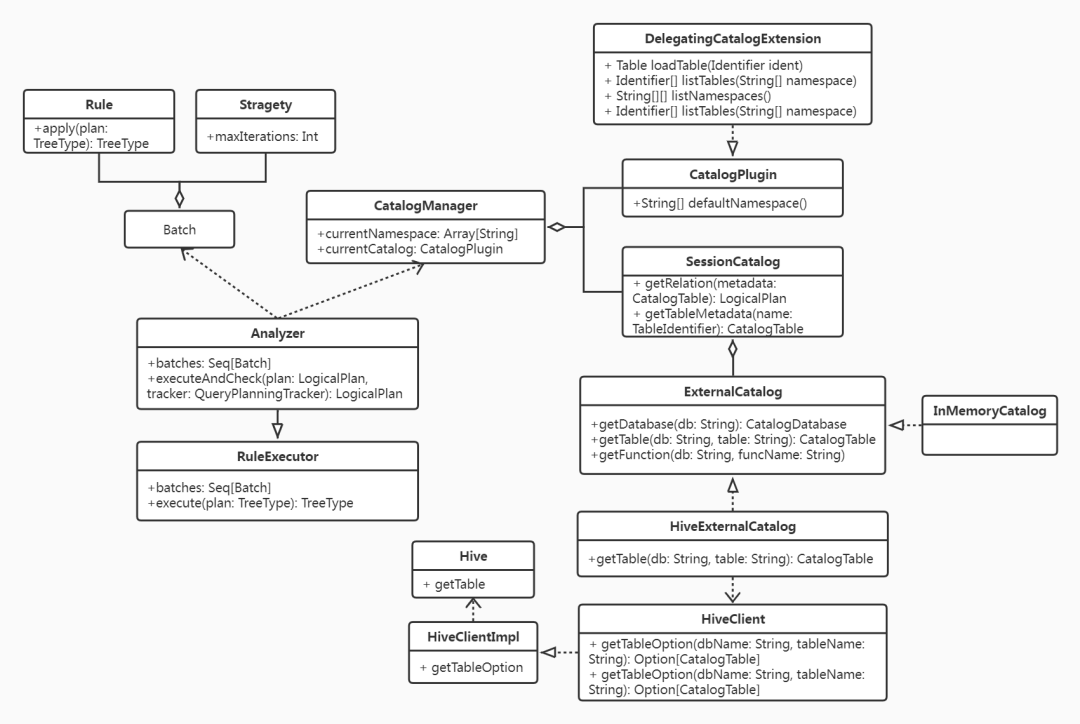
接下来仍然以前面的SQL语句(select col1 from tabname where col2 > 10)为例,简要阐述如何将一个Unresolved LogicalPlan解析成为Analyzed LogicalPlan:
1、根据Analyzer的解析规则,UnResolvedRelation节点可以应用到ResolveRelations规则,通过CatalogManger获取数据源中表的信息,得到Relation的相关列的信息并加上标号,同时创建一个针对数据表的SubqueryAlias节点;
2、针对过滤条件col2>10的过滤条件,针对列UnresolvedAttribute 可以适用到ResolveReference规则,根据第1步中得到的列信息可以进行解析;数字10可以应用到ImplicitTypeCasts 规则对该数字匹配最合适的数据类型;
3、针对Project 节点,接下来在进行下一轮解析,再次匹配到ResolveReference规则对投影列进行解析,从而将整棵树解析为Resolved LogicalPlan。
生成Optimized LogicalPlan
得到Resolved LogicalPlan之后,为了使SQL语句的执行性能更优,则需要根据一些规则进一步优化逻辑计划树,生成Optimized LogicalPlan。
本文采用的是Spark 3.0的源码,生成Optimized LogicalPlan是通过懒加载的方式被调用的,并且Optimizer类与Analyzer类一样继承了 RuleExecutor类,所有基于规则(RBO)的优化实际都是通过RuleExecutor类来执行,同样也是将所有规则构建为多个批次,并且将所有批次中规则应用于Analyzed LogicalPlan,直到树不再改变或者执行优化的循环次数超过最大限制(spark.sql.optimizer.maxIterations,默认100):
lazy val optimizedPlan: LogicalPlan = executePhase(QueryPlanningTracker.OPTIMIZATION) {
// clone the plan to avoid sharing the plan instance between different stages like analyzing,
// optimizing and planning.
val plan = sparkSession.sessionState.optimizer.executeAndTrack(withCachedData.clone(), tracker)
// We do not want optimized plans to be re-analyzed as literals that have been constant folded
// and such can cause issues during analysis. While `clone` should maintain the `analyzed` state
// of the LogicalPlan, we set the plan as analyzed here as well out of paranoia.
plan.setAnalyzed()
plan
}
...
def executeAndTrack(plan: TreeType, tracker: QueryPlanningTracker): TreeType = {
QueryPlanningTracker.withTracker(tracker) {
execute(plan)
}
}复制
逻辑计划优化规则仍然又多个Batch组成,每个Batch中包含多个具体的Rule并且可以执行一次或者固定次数。其中比较常用的优化规则有:谓词下推、常量累加、列剪枝等几种。
谓词下推将尽可能使得谓词计算靠近数据源,根据不同的场景有LimitPushDown、PushProjectionThroughUnion、PushDownPredicates等多种实现, PushDownPredicates又包含PushPredicateThroughNonJoin和PushPredicateThroughJoin;
其中,PushPredicateThroughJoin可实现将谓词计算下推至join算子的下面,从而可以提升数据表之间的join计算过程中所带来的网络、内存以及IO等性能开销:
val applyLocally: PartialFunction[LogicalPlan, LogicalPlan] = {
// push the where condition down into join filter
case f @ Filter(filterCondition, Join(left, right, joinType, joinCondition, hint)) =>
val (leftFilterConditions, rightFilterConditions, commonFilterCondition) =
split(splitConjunctivePredicates(filterCondition), left, right)
joinType match {
case _: InnerLike =>
// push down the single side `where` condition into respective sides
val newLeft = leftFilterConditions.
reduceLeftOption(And).map(Filter(_, left)).getOrElse(left)
val newRight = rightFilterConditions.
reduceLeftOption(And).map(Filter(_, right)).getOrElse(right)
val (newJoinConditions, others) =
commonFilterCondition.partition(canEvaluateWithinJoin)
val newJoinCond = (newJoinConditions ++ joinCondition).reduceLeftOption(And)
val join = Join(newLeft, newRight, joinType, newJoinCond, hint)
if (others.nonEmpty) {
Filter(others.reduceLeft(And), join)
} else {
join
}
case RightOuter =>
// push down the right side only `where` condition复制
常量折叠是通过ConstantFolding规则来实现的,如果表达式中的算子是可以折叠的则在该阶段直接生成计算结果,以避免在实际的sql执行过程中产生逐行计算,从而可以降低CPU的计算开销:
object ConstantFolding extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case q: LogicalPlan => q transformExpressionsDown {
// Skip redundant folding of literals. This rule is technically not necessary. Placing this
// here avoids running the next rule for Literal values, which would create a new Literal
// object and running eval unnecessarily.
case l: Literal => l
// Fold expressions that are foldable.
case e if e.foldable => Literal.create(e.eval(EmptyRow), e.dataType)
}
}
}复制
列剪枝规则通过ColumnPruning规则来实现,去掉不需要处理的列,可避免从数据源读取较多的数据列、将不需要的列加载至内存中计算计算计算中、以及返回不需要数据(想象一下大宽表的情况),从而获得较大的性能收益:
object ColumnPruning extends Rule[LogicalPlan]
def apply(plan: LogicalPlan): LogicalPlan
prunedChild(c: LogicalPlan, allReferences: AttributeSet):LogicalPlan=
if (!c.outputSet.subsetOf(allReferences)) {
复制
Optimizer所涉及的主要类的关联关系如下图所示:
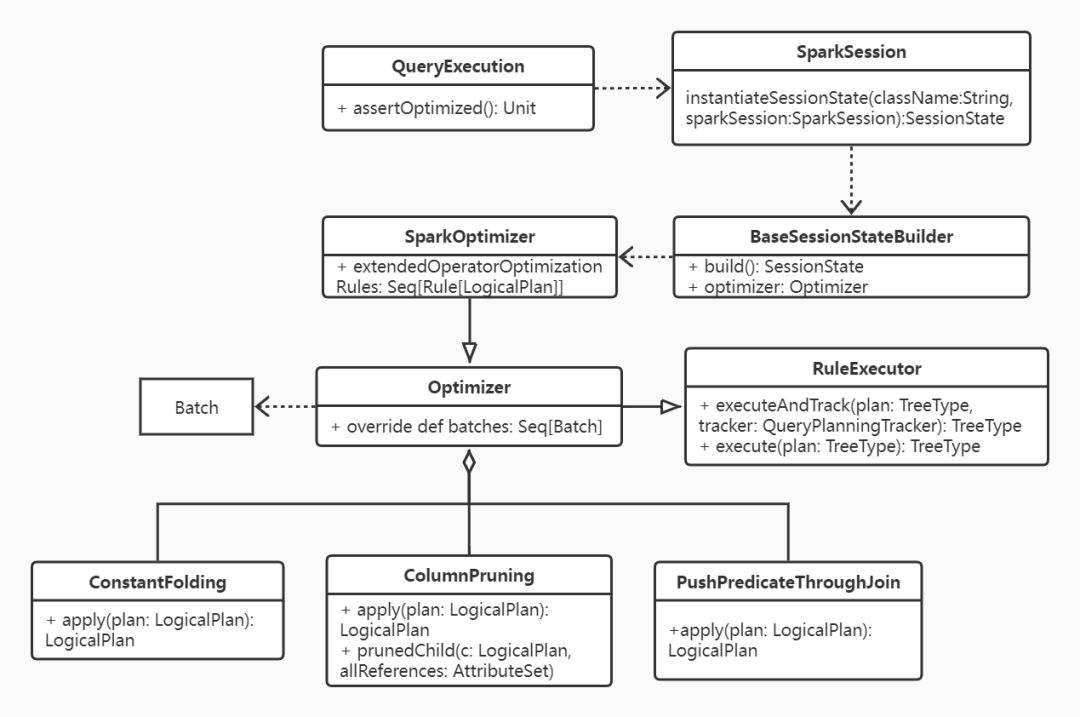
当所有优化规则完成对于Aanalyzed LogicalPlan的应用则可生成Optimized LogicalPlan。
本文重点讲解了Spark SQL解析为AST抽象语法树、生成Unresolved LogicalPlan、生成Resolved LogicalPlan以及Optimized LogicalPlan的过程,为接下来进一步生成物理计划Spark Plan做好了准备。
作者简介
焦媛,负责民生银行Hadoop大数据平台的生产运维工作,以及HDFS和Spark周边开源产品的技术支持,并致力于Spark云原生技术的支持与推广。
评论

 0 点赞 0 点赞
0 点赞 0 点赞