




前言:读完这篇文章,你可以
1. 了解两种最常见的分布式机器学习策略,包括原理,历史发展和应用场景
2. 掌握Ring Allreduce的原理及其高效的原因
1. 分布式机器学习介绍
1.1 分布式策略简介
分布式机器学习按其分布式策略可以分为数据并行,模型并行,还有两种的混合模式。
Data Parallism (数据并行)是指对所有训练数据进行切分,每个worker用相同的模型参数对自己的那一部分数据进行计算,所有worker通过同步或者异步的方式进行通信得到全局的梯度来进行下一轮迭代。而Model Parallism (模型并行)是指整个模型被划分到不同的worker上,每个worker利用所有的数据进行计算。
当前数据并行的两大主流通信拓扑结构,一个是Parameter Server 参数服务器(异步通信),还有一个是Ring Allreduce(同步通信)。
1.2 Parameter Server
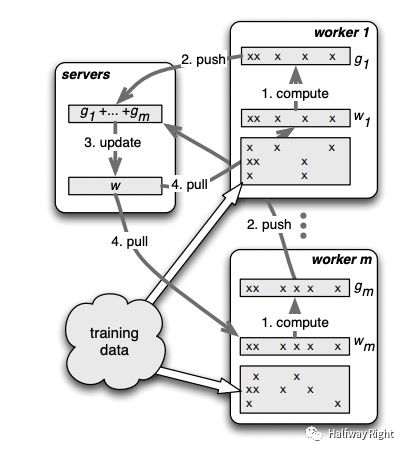
历史:Parameter Server的概念最早由Alex Smola 2010年在parallel topic models中提出,而后Jeff Dean老师首次将Parameter Server应用于深度学习的训练中(Distbelief,Tensorflow前身),2013年李沐在Parameter Server的consistency, fault tolerance, 和弹性方面进行改进。这里我们就讲最基本的参数服务器。
主要思想:参数服务器中,所有node被分为server node和worker node,server node负责参数的存储和全局的聚合操作,而worker node负责计算。在计算过程中,所有数据会被划分到每个worker node上,每个worker node首先从server node中pull 模型的参数,并利用本地的数据进行计算得到本地的梯度(local gradient gi),并将其push到server node上。而server node根据所有worker node的梯度进行求和得到全局的梯度g,进行参数的更新(对SGD进行推演易得每个worker的梯度是独立的),然后worker node再从server node中pull新的参数进行下一轮迭代。
适用场景:模型EmbeddingLookupTable在一台机器放不下和CPU异步训练场景(如搜广推等大规模稀疏特征场景)
此外,根据该server node的求和是否阻塞下一步的迭代,我们可以将Parameter Server分为同步更新和异步更新,一般PS采用异步更新,因为PS下CPU计算能力不均衡加上Parameter Server All2All的通信方式,造成其同步更新效率很低。而数据并行下的同步更新,其主流的通信策略是Ring Allreduce,适用于各设备计算能力均衡的硬件如GPU。
1.3 Ring Allreduce
关于异步通信和同步通信的异同我们放在下一次的Parameter Server中讲,下面我们只讲同步通信机制。
为什么需要Ring Allreduce?
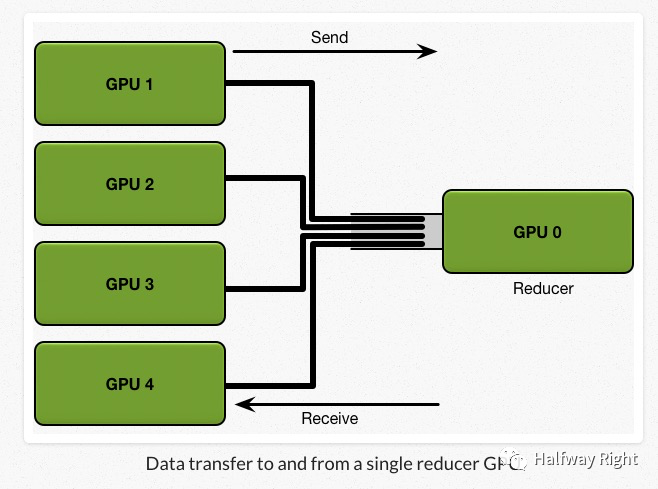
如图所示,假设有5块GPU,每一块GPU拥有完整的模型参数可以进行forward pass和backward pass,总共的训练数据大小为K,我们需要根据训练数据计算出所需要的梯度进行一次迭代。
考虑一个简单的同步通信策略。首先,每张GPU拥有同样的初始参数,我们将大小为K的训练数据分为N块,也就是5块,分给每张GPU。每个GPU基于自己那一部分的数据,计算得到本地的local gradients,然后N-1块(4块)GPU将计算所得的local gradients 发送给GPU 0,让GPU 0对所有的local gradients进行reduce(汇聚操作)得到全局的梯度,然后再将该全局梯度返回给每块GPU进行back propagation来更新每个GPU上的模型参数。
那么我们可以计算下整个通信过程的communication cost。首先要记住现实中,network的 bandwidth是有限的,假设每张GPU需要发送给GPU 0的通信数据大小是1GB,我们的network bandwidth是1GB每秒(GPU 0最多每秒接受1GB的数据),那么我们需要4秒才可以将数据全部发送到GPU 0上,然后计算出全局的平均梯度。我们可以看到其通信成本是 C * N,由于受GPU 0的network bandwidth的影响,通信成本随着设备数的增加,而线性增长。
其实我们把GPU 0用作Parameter Server,只存放模型的参数和只做reduce操作,就可以看到参数服务器随着 worker 数量的增加,其加速比会迅速恶化的原因。
Ring Allreduce介绍
相比之下,Ring Allreduce的通信成本恒定,和设备数量无关,完全由系统中GPU之间最慢的连接决定。
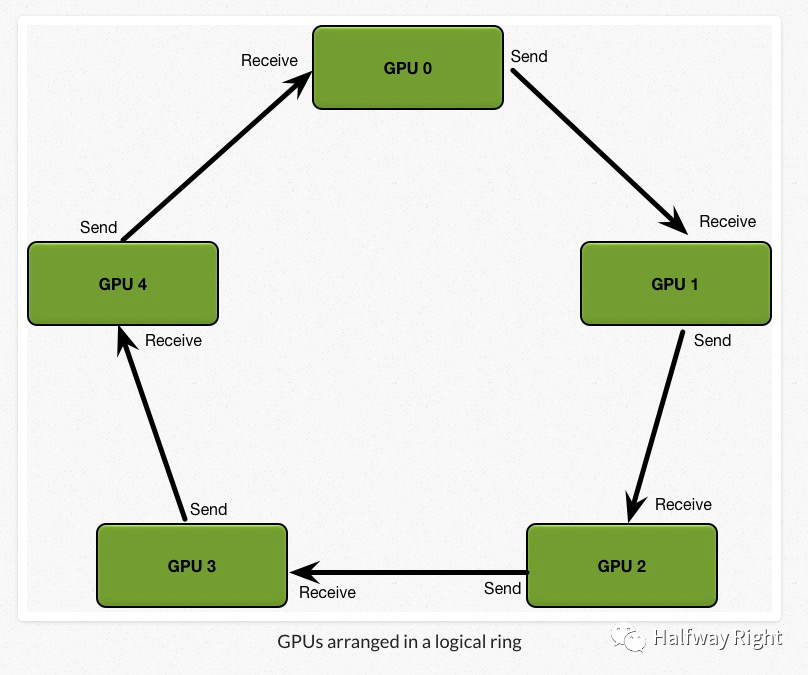
主要思想:我们将所有设备安排在一个逻辑环中,每个GPU应该有一个左邻和一个右邻,设备只会从它的右邻居发送数据,并从它的左邻居接收数据,整个计算过程通过Scatter reduce和Allgather两个通信原语完成。
适用场景:模型可以在一台机器放下
Ring Allreduce的历史:
AllReduce来源于MPI_AllReduce,是MPI中的集合通信原语。在2016的时候,百度首先将Ring Allreduce应用到到Tensorflow中。后来,当红炸子鸡Horovod基于百度的Ring Allreduce进行了NCCL版本的实现。
Ring Allreduce的主要过程:
不失一般性,假设我们5个设备(GPU),每个设备上有一个数组,我们的目标是计算所有数组中的元素之和,并且每个设备都要有该求和的结果。(这其实模拟了数据并行中,每个设备拥有全部数据的一部分数据进行forward pass和backward pass,并且同时拥有具有全局一致性的模型参数和梯度进行参数更新)
首先,我们将一个设备上的数据分为N份,N为设备个数。
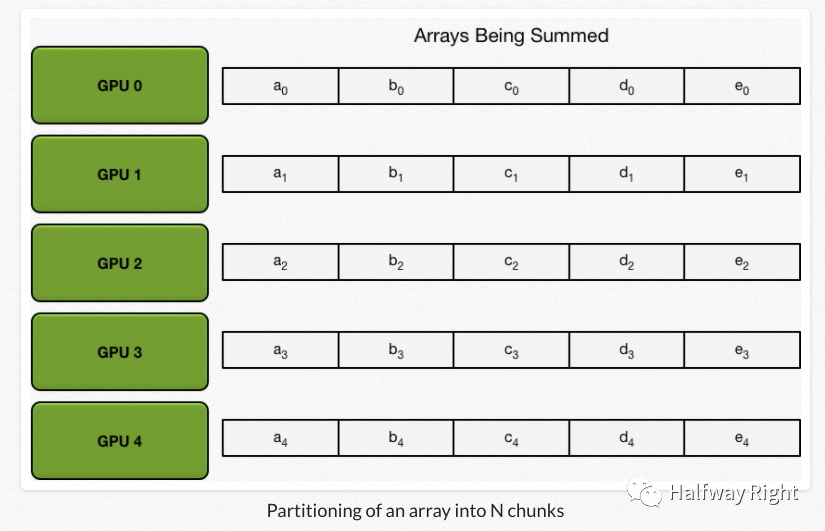
Scatter-Reduce
在一轮Scatter-reduce迭代中,左边的GPU将一个chunk的数据发送给其右边的GPU,右边的GPU收到了数据和本身的一个chunk数据进行求和。
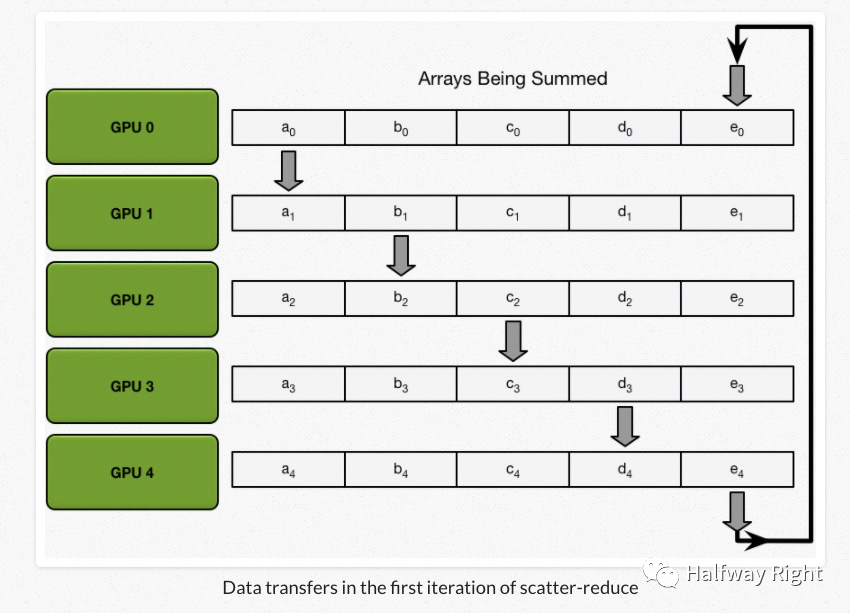
在一轮Scatter-Reduce以后,我们可以得到下图的结果:
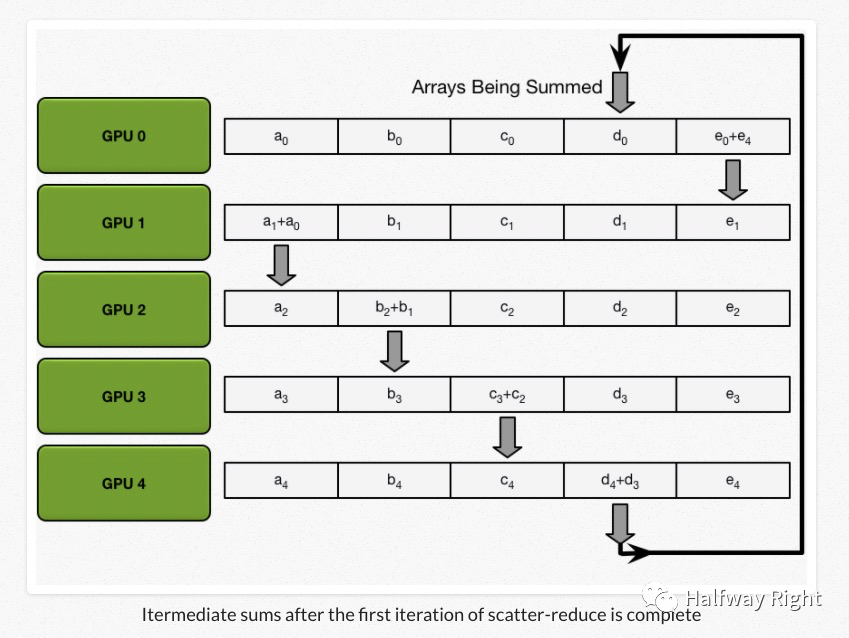
经过N轮迭代以后,我们得到Scatter-Reduce的结果,每一个设备都拥有一部分全局的accumulation的结果。
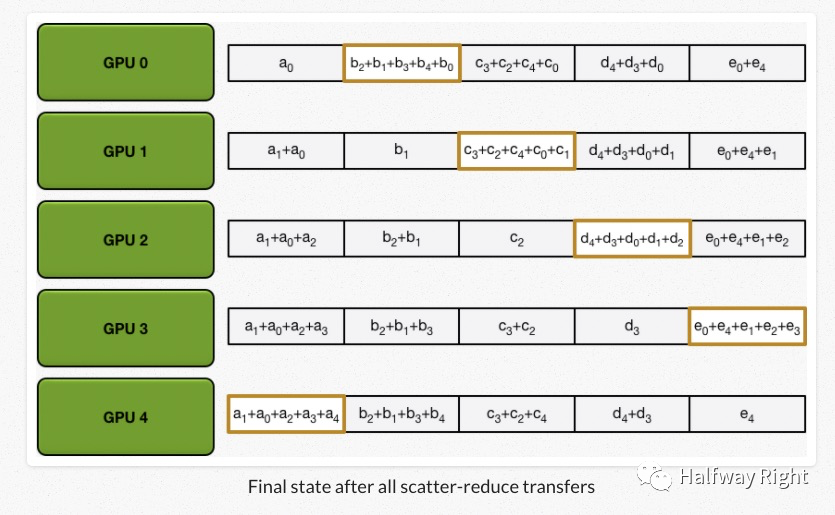
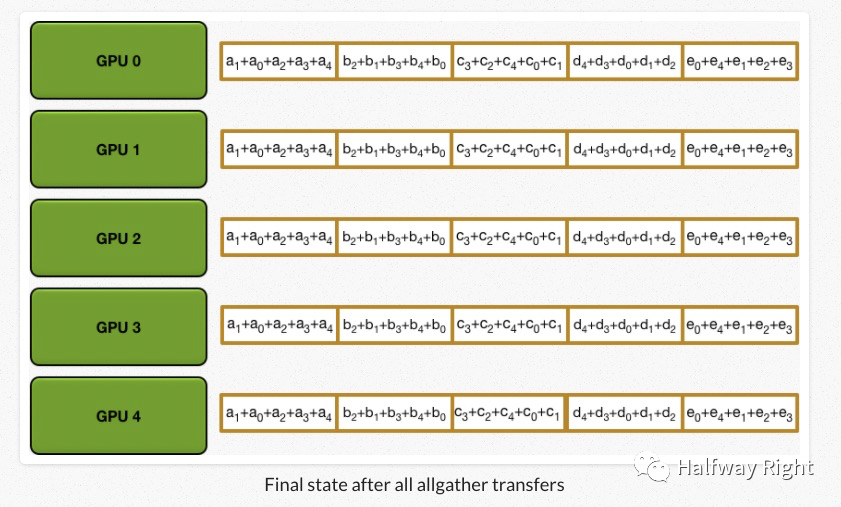
Allgather
我们最终是需要所有设备可以计算出所有数组的求和。这里,所有的设备通过allgather的操作交换那一部分的数据,其实进行的是和Scatter-Reduce类似的操作,只是从加法变成了重写。
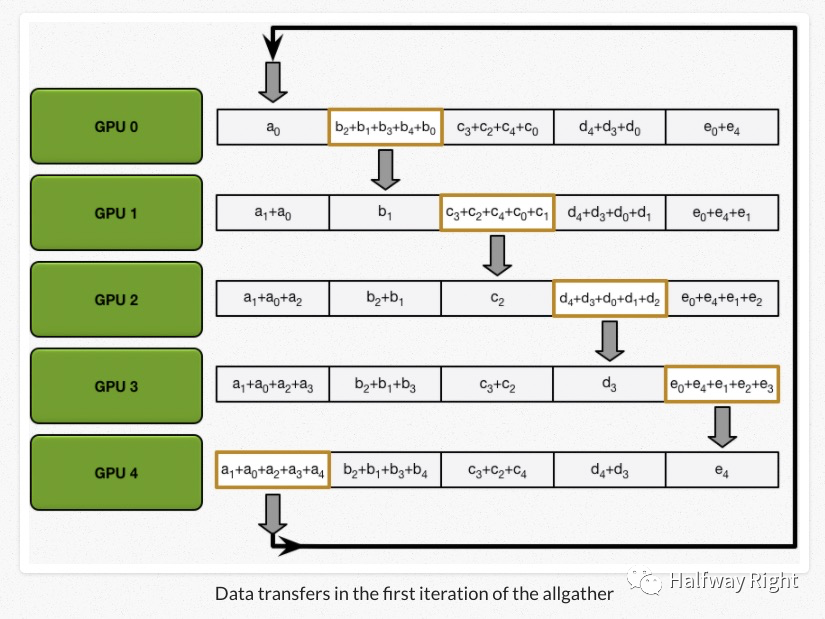
经过N轮All gather的迭代以后,所有的设备都可以得到能够累加得到全部数组大小的中间值了,每个设备只要再各自进行求和就可以得到整个数组的大小。(如下图所示)
Ring Allreduce的通信成本
我们来计算下整个Allreduce过程的通信成本。假设我们有N个设备,每个设备的数据大小为K,在一次Allreduce过程中,我们进行了N-1次Scatter-Reduce操作和N-1次Allgather操作,每一次操作所需要传递的数据大小为K/N,所以整个Allreduce过程所传输的数据大小为2(N-1) * K/N (< 2K,与设备数N无关),而整个Allreduce的通信速度只受限于逻辑环中最慢的两个GPU的连接(每次需要通信的数据大小仅为K/N,随着N增大,通信量减少,一般小于network bandwidth)。
Horovod中的Allreduce
在深度神经网络中,一个网络由多个layer组成,在backpropagation的过程中,在前层的神经网络的gradient的计算中,后层的神经网络的梯度已经计算完成,我们可以先开始后层layer 梯度的allreduce操作,这样和前层梯度计算过程的overlap也可以减少通信时间。
Renference:
文章参考:
Bringing HPC Techniques to Deep Learning @Andrew Gibiansky
Parameter Server for Distributed Machine Learning @李沐
封面图片:Ghost in the shell @Martin Ansin 最喜欢的科幻动漫
