




前言
老板说啥咱就做啥,最近老板让看看Pytorch的分布式方案,笔者满心欢喜地开始瞄Pytorch原生的DistributedDataParallel,Uber的Horovod,还有巨硬的Deepspeed。(毕竟一边端着杯枸杞学习,一边还能拿着工资哈哈)
那我们首先从Horovod开始介绍(别问为啥不先讲DistributedDataParallel,只是因为看太久忘了;为啥不讲DeepSpeed,因为还没看明白)。
Horovod介绍
Horovod是Uber开发的一款数据并行的深度神经网络模型开发框架,支持不同深度学习框架(TensorFlow、PyTorch、MxNet),可以把它理解为一个Tensorflow这种深度学习框架的一个插件,主要用于支持更好的分布式训练。大概意思就是说,用户只需要调用Horovod的API在原有的单机版本代码上进行简单改造,就可以实现分布式深度学习的功能,而分布式的实现细节都托管给Horovod框架。
Ring Allreduce介绍
首先我们讲下Horovod这个框架的motivation是什么。Parameter Server和Allreduce都是分布式机器学习中基于Data Paramlism Paradigm的通信拓扑结构,他们定义了分布式系统中,节点和节点的逻辑连接方式。
DistBelief/Tensorflow最开始使用异步的Parameter Server作为通信策略的,有效地解决了Spark MLlib Master单点通信的瓶颈。然而Paramaeter Server和worker之间All2All的通信方式也容易造成流量堵塞,且其通信成本是和设备的数量线性相关的。相较而言,Horovod采用通信成本与设备数量线性无关的Ring Allreduce作为其分布式策略。
话说,Allreduce本来是HPC里的communication primitives,Baidu在2017实现及开源了一版高效的Allreduce(也就是Ring Allreduce)用于tensorflow的分布式训练,后来Uber的Horovod框架基于Baidu的Ring Allreduce实现了这一套分布式策略。
那么使用Ring Allreduce可以带来以下优点
reduce the communication overhead (减少通信冗余)
scale to many more devices(容易scale up)
保持同步随机梯度下降的收敛性
后面我会专门拿一篇文章来详细介绍Parameter Server和Ring Allreduce来解释这个原因,当然Parameter Server和Ring Allreduce都有各有各的适用场景,其中PS适用于大规模稀疏特征场景如搜广推,而Ring AllReduce适用于中小规模场景或者对一致性要求高的场景,不过目前搜广推下有结合两者使用的趋势。
Installing
1. 手动编译
笔者尝试手动编译了下Horovod,用于Pytorch的分布式训练,尝试了一天还是放弃了。主要在于gcc需要重新编译 (gcc >= 4.9),Pytorch的horovod版本和 Tensorflow的版本不一样,从pip安装不行,也需要重新编译。结果编译了一天还是有问题,所以直接拉docker镜像了。
2. Docker
本来以为用Horovod github上的Dockerfile可以一举成功,结果发现自己还是想多了(或者枸杞吃多了),docker build的时候,碰到各种环境问题如cuda报错,有点崩溃。最后,索性直接从Dockerhub拉了一个编译好的Horovod镜像下来,终于可以愉快地玩耍了。
Dockerhub地址: https://hub.docker.com/r/horovod/horovod/tags?page=1&ordering=last_updated
docker pull horovod/horovod:0.20.0-tf2.3.0-torch1.6.0-mxnet1.6.0.post0-py3.7-cuda10.1复制
本机环境
CUDA 10.1
GPU: 两张16G的Tesla P100
# 启动并进入容器
sudo nvidia-docker run -itd --name torch-horovod-gpu --network host horovod/horovod:0.20.0-tf2.3.0-torch1.6.0-mxnet1.6.0.post0-py3.7-cuda10.1 bin/bash
sudo docker exec -it torch-horovod-gpu bin/bash复制
Horovod主要过程
# 1. init environ
hvd.init()
# 2. Pin each GPU to a single process.
# 进程会按照顺序pin到GPU上,one gpu per process
torch.cuda.set_device(hvd.local_rank())
# 3. 限制每个worker的CPU线程数目
torch.set_num_threads(1)
# 4. dataloader的sample继续用torch原生的DistributedSampler进行数据切片
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
# 5. 用hvd.DistributedOptimizer wrap优化器
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=model.named_parameters(),
compression=compression,
op=hvd.Adasum if args.use_adasum else hvd.Average,gradient_predivide_factor=args.gradient_predivide_factor)
# 6. 将initial variables从rank 0 broadcast到各个processes去
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)复制
Demo实验我们直接采用Horovod的官方代码,直接跑简单的cnn + mnist这个example。有些examples的prerequsite需要自己安装下,如tqdm, filelock的。
git clone https://github.com/horovod/horovod.git
cd horovod/examples/pytorch
# 单机启动方式
python pytorch_mnist.py
# 分布式的启动方式
horovodrun -np 2 python pytorch_mnist.py复制
实验结果:
实验 | epochs | 运行时间 | Avg loss | Accuracy |
CNN+MNIST(pytorch_mnist.py 2进程) | 20 | 4.07 minutes | 0.0424 | 98.71% |
horovodrun的坑
用horovodrun跑Horovod自己的example又有新的坑,碰到通信错误“bus error”,解决方案可以参考https://github.com/horovod/horovod/issues/2053,亲测把demo中的num_workers设置为0是OK的。(不过这应该是Python多进程依赖的问题,可能还是环境上还有些许问题,如果worker是0,那么只起了一个进程load数据)
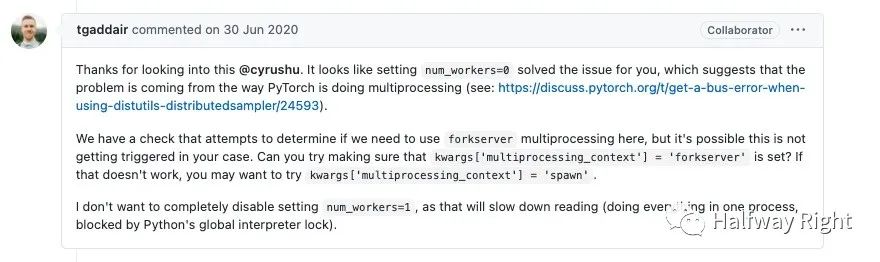
解决方案:由于我是在docker中跑的,后来其实发现是Docker容器内存过小造成的,通过加大容器内存可以解决这个问题。
例子参考链接:
https://github.com/horovod/horovod/blob/master/examples/pytorch/pytorch_mnist.py
Reference
Horovd论文:Fast and easy distributed deep learning in TensorFlow: https://arxiv.org/pdf/1802.05799.pdf
Parameter Server论文:Scaling distributed machine learning with the parameter server
封面图片引用自:Leo@pinterest.jp/hhp0820
封面图片都是来自Pinterest的,说起Pinterest是因为以前业余学Graph Machine Learning的时候,一直在看Jure Leskovec的课,然后当时Jure Leskovec是Pinterest首席科学家,就一下种草了这个App。
