




前言
这段时间一直在调研各大厂搜广推的训练框架,基本覆盖了国内外各大互联网公司,不过很多内容并不是团队所需要的,但也想着自己梳理出来理清思路,于是准备写这一篇小白文,也能帮助在学校里的学弟学妹们了解下工业界的模型是如何进行训练的。
本文主要会
说明为什么需要大规模分布式训练,论述不同场景下面对的问题和的挑战
然后尝试阐述各解决方案中核心的两点
通信拓扑的设计
embedding Lookup优化
最后也会简单总结下目前调研的各框架的主要特点。
为什么需要分布式训练?
首先我们来说明下为什么需要分布式训练。在学校或者实验室的时候,我们会学习和研究不同的机器学习算法,也会在各种比赛中使用sklearn或者tensorflow训练我们的模型,看到的算法论文也基本是偏学术性的模型结构论文。而工业界进行模型训练却大不相同:
数据量级大。在学校中接触到的数据量都很小,多的也只有几十万,上百万而已,而在工业界做模型训练的时候,我们需要面对千万级,亿级以上的训练数据,这种规模的数据给预处理和模型训练都来了很大的问题,所以会有使用MapReduce或者Spark进行数据预处理,采用分布式训练起成百上千的节点进行模型训练。大部分公司采用Tensorflow Estimator模式或者Pytorch DDP/Horovod模式或者魔改版本进行分布式训练。
模型参数量级大。相比于学校里几十MB的模型可以在单机内存中放下,搜广推的模型可能高到百GB,甚至TB级别,比如百度的CTR模型在2016年就高达10TB,仅模型参数就无法在单机内存中放下。
实效性要求高。抛开在线训练,即使只进行离线训练,大量级的训练数据也会造成模型训练耗时过长,影响日新月异的业务迭代,所以一般会通过软硬件上的scale up和 scale out缩短模型的训练时长,但这些都会带来分布式系统在机器学习领域上的特定问题和挑战。
大规模的数据IO和预处理。相比于学校中,我们将几万条数据存放在本地磁盘上,写单进程的程序进行数据的预处理,工业界的数据量级高达千万级,亿级甚至千亿级,业界一般会将数据存储在分布式的存储系统中(如HDFS),如何读取这么大量级的数据和高效的数据预处理成为了显著的问题。离线训练下我们可以采用MapReduce, Spark,多进程/线程,或者缓存的方式进行高并发的数据读取和分布式的特征预处理。
上述的这些原因造成了在工业界需要开发分布式系统承载数据的存储(HDFS),预处理(MapReduce),和模型训练(Parameter Server/All Reduce),然而随着节点数增多,我们会面对着底层环境不稳定因素概率增大,各阶段的性能瓶颈,都需要进行相关的优化和容错。而各大厂也会有专门的中台框架负责衔接模型的训练的各个阶段,如数据源IO,预处理,模型训练和在线部署,以及进行稳定性保障和相关性能优化,而算法只需要调用框架API就可以完成模型的分布式训练。
不同场景下分布式训练的痛点
CV和NLP场景
搜广推模型,CV和NLP模型,由于各自的数据形式,应用场景和模型结构,面对着不同的痛点问题,也需要不同的解决方案。对CV和NLP场景的大规模的分布式训练来说,除了上述的数据量级大,还有两个主要的问题
CV和NLP场景模型复杂,单机性能要求高,比如卷积的计算时间在CPU上和 GPU上相差十倍到几十倍。
模型大(DenseNet部分),比如NLP领域,GPT-3这样的模型高达1750亿参数,显存占用高达2.8 TB,单机内存无法容纳。而Bert-Large虽然只有3.4亿参数规模,但由于各种内存占用,在16G V100上,训练也仅能使用batch Size=8。
针对问题一,业界主要使用高性能的GPU进行计算,并采用All-reduce的通信拓扑进行参数的同步更新。关于Allreduce可以参考前面一篇文章。而针对问题二,当面对GPT-3这种DenseNet部分大的模型,Allreduce 单卡内存无法容纳,我们需要采用模型并行(model parallelism)的方式将计算图划分到不同的设备上构建有向无环图(DAG)进行分布式训练,其中Gpipe, Megatron, Oneflow和Whale都提出模型并行的相关解决方案。模型并行可以按其对Layer切分的维度分为Intra-layer parallelism和Inter-layer parallelism(相比于数据并行每个worker只有一部分数据,模型并行下每个node使用所有数据):
Intra-layer parallelism(Tensor Parallelism) 。主要是将一层Layer中的矩阵计算分别拆分到不同的机器上进行运算,比如简单的Y_1=W_1 X_1这一次矩阵乘法中,我们将模型参数W_1或者输入数据X_1,按某个维度分别拆分到不同设备上计算,比如1D Megatron。
Inter-layer parallelism(Pipeline Parallelism)。而Inter-Layer Parallism会将模型的layers拆分到不同的机器上,则一次forward就需要跨过不同的机器串行地进行运算,而流行并行通过将batch size切分为更小的mirco batch,减少数据依赖,从而将整个计算过程异步起来,最大化资源利用率。举例来说,在一个简单的三层MLP中(的Y_i = W_i X_i, i=1,2,3)会存在三次矩阵乘法 W_i X_i,流水线并行会把W_iX_i分别分配到三台机器上进行运算。
搜广推场景
不同于CV和NLP场景,在搜广推场景下,碰到的主要问题是:
模型小,词表大。(我们沿用XDL将模型分为DensetNet和SparseNet的描述,其中SparseNet特指Embedding Lookup Layer,主要针对给定的int或者string类ID查询相应的embedding vector;DenseNet一般是我们常说的抛开Embedding lookup Layer的模型部分))。模型中的DenseNet部分,不像BERT是模型巨大词表小,往往一台机器的内存就可以容纳,但是其特征量级可能高达成百上千亿,造成Sparsenet部分或者Embedding lookup table高达TB级别,使得单机无法容纳。
一个batch的embedding lookup量级大,造成查询耗时大。由于特征数量多,一个batch可能包含几十万个ID类特征,tf原生的embedding lookup查询耗时大,造成训练和inference性能低。尤其在线上inference的时候,无法在给定RT内完成服务响应。
CPU集群稳定性差。搜广推场景数据量级大,耗费资源多,往往需要起几十个,或者成百上千个计算节点进行一次模型训练。然而GPU价格高,造成搜广推场景下,仍然主要采用CPU集群进行大规模分布式训练,然而CPU计算能力不均衡和大规模节点下通信延迟高和不稳定性上升(比如straggler 和failover问题),这会严重影响模型训练的效率和成功率。不过近些年的趋势是各大厂也在用高性能的GPU进行模型的forward和backward计算,词表的查询和参数的aggregate和update还是采用CPU进行计算。
数据具有大规模稀疏的特点。不同于CV和NLP场景,数据是稠密的图像和文本,搜广推的数据非常稀疏的,第一这来源于很多数据无法对所有用户和场景有效采集到,第二是因为建模使用的特征量级大造成的高维稀疏性。这会影响了数据的存储格式和计算效率。
针对上述的问题,各个大厂的训练框架进行很多相关优化,目前总结下来,核心的两点,一个在于分布式通信拓扑的设计,还有一个在于Embedding Lookup的性能优化。
参数服务器:
参数服务器介绍
我们首先简单介绍下参数服务器(Paramter Server or PS)。PS最早由Alex Smola于2010年在parallel topic models中提出,Jeff Dean在DistBelief(Tensorflow前身)中首次采用参数服务器进行神经网络的分布式训练,而后李沐在容错和弹性方面对参数服务器进行相关改进。
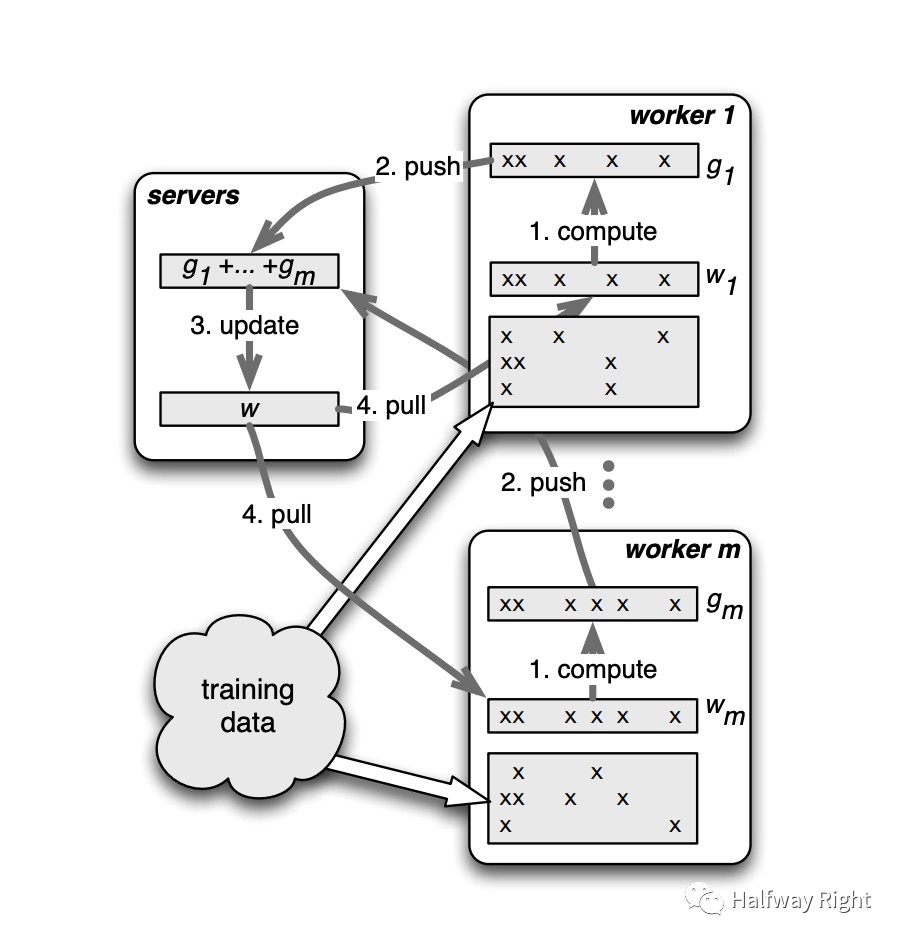
简单来说,参数服务器有parameter server和worker两个角色,parameter server负责参数的存储,聚合和更新。worker负责从server上pull最新的模型参数,并利用部分训练数据进行模型的forward和backward的计算得到梯度并push回server。观察如下带正则项的loss公式,我们可以发现n条数据的梯度的计算是相互独立,这样在PS和Allreduce这种数据并行模式下,我们可以将一个global batch size的数据分为N个local batch size的数据给N个worker或者处理器分别进行计算梯度,然后aggregate每个worker的梯度(local gradient)来实现全局的梯度下降。举例来说,在一次计算中,worker从Parameter Server中pull最新的DenseNet参数,然后,worker根据一定的数据切分逻辑从数据源(如HDFS)拉取该local batch的数据,进行模型的forward和backward(同时在需要的时候会即时查询EmbeddingLookupTable获得SparseNet的Dense参数),计算得到local gradients然后push回paramter server。Parameter Server接受到N个worker的local gradients,然后聚合 N个local gradients进行全局参数的更新,来得到最新的模型参数。而后,各个worker pull最新的模型参数进行下一轮迭代。
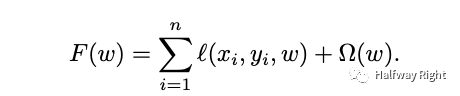
参数服务器如何解决上述问题
针对问题一,参数服务器将DenseNet和SparseNet的参数分布式地存储到不同的server节点上来解决单点无法存储SparseNet的问题,而worker节点只负责从servers上拉取最新的模型参数进行模型计算。这样每一次迭代中,worker只需要最新的DenseNet参数,而不需要存储所有的Sparsenet(词表),只需要在forward和backward中按需去Parameter Server上进行查询和更新。
针对问题二和三,按照worker的下一次forward是否需要等到所有其他worker的梯度完成聚合更新获取到最新的模型参数,可以分为异步(Aynschronous Parallel),同步(Synchronous Parallel)和半同步(Stale Synchonrouse Parallel)的更新。PS通过异步更新或者半同步的更新方式解决一部分模型训练耗时长的问题(比如worker的慢节点straggler问题),因为单个worker并不需要等其他worker都完成gradient的计算和通信就可以进行下一次迭代。这里的异步是指,一个worker在完成backward得到梯度以后就push到paramter server上进行模型参数的更新,然后pull最新的参数开始下一轮迭代,而不需要等待其他worker完成该轮次梯度的计算和push。同步更新下,下一次迭代需要等到所有worker完成backward,并将梯度push到Paramter Server,并由Parameter Server完成所有梯度的聚合并进行模型参数的更新,然后再pull最新的模型参数进行下一轮的迭代。而半同步更新允许worker梯度的更新慢一定时间。
参数服务器带来的问题
Consistency vs. Availablity。显然,这边我们面对着Consistency和Availability的问题,同步更新虽然可以保证Consistency,但由于各节点计算能力不均衡无法保证性能,而异步更新或者半同步更新并没有理论上的收敛性证明,Hogwild!算法证明了异步梯度下降在凸优化问题上按概率收敛,而深度学习问题一般面对的是非凸问题,所以无论异步和半同步算法都无收敛性的理论保障。所以只是根据经验,大部分算法在异步更新是可以收敛,求得最优或者次优解(其实现在无论是学术界和工业界,深度学习只要效果好就行)。当然目前比较好的方式针对针对SparseNet部分( 低IO pressure, 但高memory consumption),DenseNet部分 (高IO pressure,但低memory consumption)的特点,对sparsenet进行异步更新(因为Embedding Lookuptable的更新是稀疏的,冲突概率低),DenseNet采用同步更新的方式尽量逼近同步训练的效果。
All2All的通信瓶颈。随着Parameter Server和Worker的节点数增多,PS和worker间ALLtoALL的通信方式会带来新的性能瓶颈,比如参数服务器数量过大,造成一个worker pull/push时间过大;worker数量过大,造成单个PS的通信带宽瓶颈)和不稳定性问题(比如训练中某个PS或者Worker节点突然挂了,或者出现慢节点)。对于这些问题的解决都比较细节,不再细述。
容错和弹性。当Parameter Server或者worker在运行时因为各种错误(比如OOM,软硬件错误)挂了时,可以从checkpoint中restore参数回来进行重新训练。此外,李沐老师基于一致性哈希将模型参数分配到各server上进行存储,通过range pull和range push进行参数的更新,这解决了多server的参数存储和协同计算问题(在server数量弹性变化时,尽量减少参数重新的replacement)。不过,目前看Tensorflow Estimator的实现并不考虑PS的弹性增减,所以相比于一致性哈希,其采用简单的round-robin策略对模型参数进行分配,
相关优化工作
Overlap 通信和计算的时间来加速训练。在梯度的计算中,深度学习框架如Tensorflow,Pytorch都是采用backward mode的自动差分进行梯度的计算,在一次Backpropagtion的计算中,我们通过loss从output 到input依次计算loss对各个node的梯度,得到各个参数的梯度,我们可以发现模型的forward过程是从input layer到output layer依次计算中间结果的,而backward过程是从output layer到input layer依次计算模型参数。那我们可以让上一次backpropagtion得到的梯度,尽早地开始后续forward的过程,来加速分布式训练,当然这需要允许一定的staleness。比如,快手的Persia通过overlap backward的计算和梯度的allreduce来加速训练(其梯度是T+2更新的)。
其他魔改的通信拓扑。比如,字节的BytePS,虽然这个也叫PS,但其实是一种新的all reduce机制,其通过增加额外的CPU worker,增加了更多的通信带宽,来加快模型的训练。阿里的EFLOPS,相比于一般Paramter Server并没有PS节点,SparseNet和DenseNet的模型参数都存放在worker上,其中SparseNet通过ALLtoALL的方式进行embedding lookup和梯度的交换,而DenseNet采用Allreduce的方式交换梯度。
针对如何解决针对问题二中Embedding Lookup的计算性能问题,放到下一篇中,主要会尝试解释下目前主流的基于HashTable的Embedding Lookup方案和简单总结下各大训练框架的特点。
