




首先我们假设有张简约版的商品表, 创建语句如下:
CREATE TABLE `goods` (`id` int(11) NOT NULL,`category` varchar(16) NOT NULL DEFAULT '' COMMENT '类别',`name` varchar(16) NOT NULL DEFAULT '' comment '商品名称',`img` varchar(128) NOT NULL DEFAULT '' comment '封面',PRIMARY KEY (`id`),KEY `idx_category` (`category`)) ENGINE=InnoDB;复制
现在有个业务场景需要根据名称升序获取食品类的商品:
select * from goods where category = 'food' order by name limit 1000;复制
这条简单的语句你知道是怎样执行的吗?
首先,我们了解一个概念:MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
该条语句的执行过程如下:
首先初始化 sort_buffer。
从索引idx_category中找到第一个 category = 'food' 的行。
取出索引表的主键id,到主键表找到该行的信息,并存到sort_buffer中。
从idx_category索引表取下一个category = 'food' 的行。
重复2,3,4直到在索引表找到第一个不满足category = 'food' 的行。
在sort_buffer中对name进行排序,并返回前1000行。
图示过程如下:
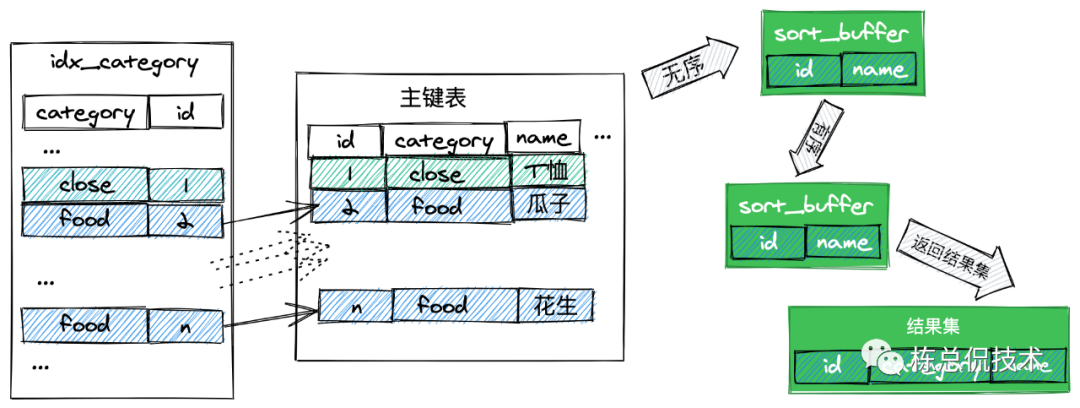
其中第6步,sort_buffer中对name进行排序,可能是在内存中完成的,也可能需要借助磁盘完成,取决于 sort_buffer_size 是否够用。
可通过如下语句查看排序语句是否借助磁盘完成:
/* 打开optimizer_trace,只对本线程有效 */SET optimizer_trace='enabled=on';select * from goods where category = 'food' order by name limit 1000;/* @a保存Innodb_rows_read的初始值 */select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';/* 查看 OPTIMIZER_TRACE 输出 */SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G复制
输出的 number_of_tmp_files表示使用的磁盘文件个数,0表示在内存中完成排序。(参考林晓斌老师极客课程)
如果表goods字段特别多,一行的数据就很大,那么在sort_buffer中可存储的行比较少,就得完全依赖磁盘文件进行排序了,会增加了很多次磁盘IO,必定影响查询结果的响应时间,所以大家尽量只取自己需要的字段。
假如goods表字段比较多而只需要名称时,可将该语句:
select * from goods where category = 'food' order by name limit 1000;复制
改为:
select category,name from goods where category = 'food' order by name limit 1000;复制
如果确实业务上需要的字段比较多,这个时候也不用担心,mysql通过 max_length_for_sort_data属性判断一行的数据是否会超过该大小。如果一行数据大小超过max_length_for_sort_data,只会把需要排序的字段以及主键存储至sort_buffer中。其过程如下图:
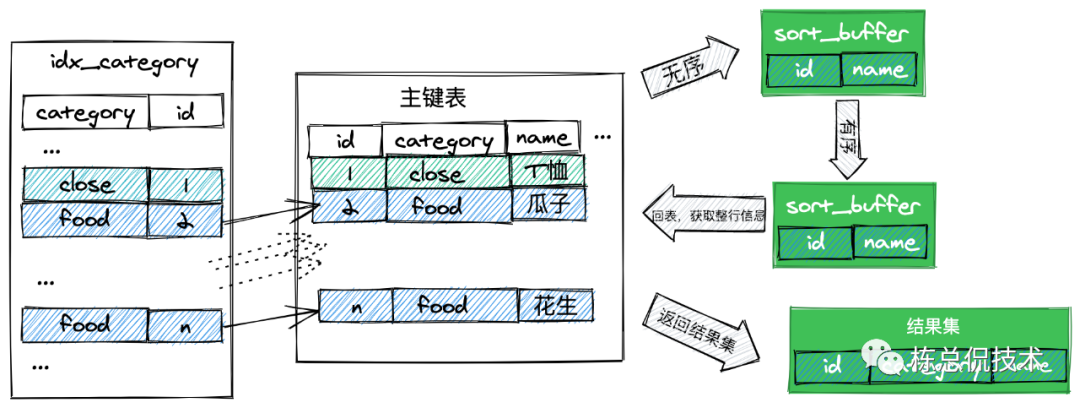
我们看到相对于原来的过程,多了一次回表查询。多的这一次回表操作同样会影响查询的响应时间。
我们不着急往下读,大家思考下上述例子中的查询语句是否还可以优化呢?
当然是可以的,我们在 MySQL系列2 - 什么是索引以及优化器怎么工作的?这一节提到过覆盖索引,我们同样可以使用覆盖索引来优化上述查询过程。
我们可以建立一个category、name的联合索引。这样在索引内部已经根据name排好序了,无需再通过sort_buffer排序了。过程如下图:
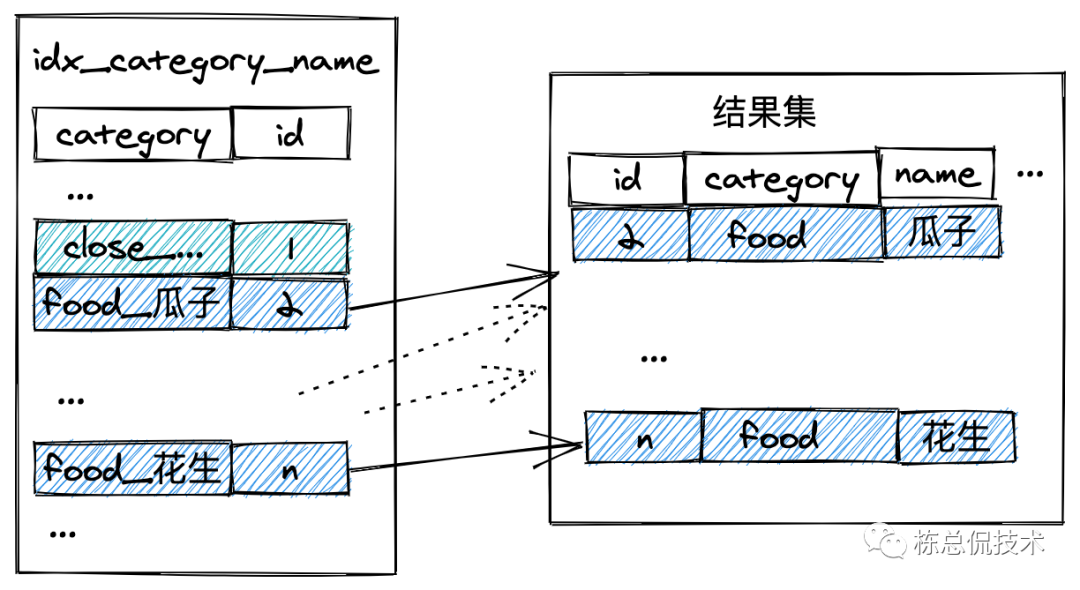
我们在开发实践中,总是会使用order by语句的。如果我们能够知道其运行原理,同时还能分析出出语句有哪些消耗,并能及时的做优化。将会在每一行代码、每一句sql、每一个索引中提高服务的稳定性和提升服务的接口效率。
往期回顾:
MySQL系列1 - sql语句的执行过程以及redo log和binlog扮演的角色



